学习内容
在本期训练营中,我们将以AWS数据分析完善架构作为理论范本,学习数据分析的架构中的6个层级定义(数据摄取层、数据访问与安全层、目录与搜索层、集中存储层、处理与分析层、用户访问与界面层),学习各层级的关键点和最佳实践。同时通过案例分析去讨论数据分析为业务带来的收益,以及案例中各个层级架构选件的最佳实践。您可以在这里下载英文版《WellArchitected-Analytics-Lens》 或中文版《AWS数据分析完善架构白皮书》 以作为学习课件。
我们的学习过程将通过解决方案架构师讲解授课和学员互动方式进行,除了理论学习我们将在每个环节将进行动手实验,让理论和实践交叉练习。
我们将课程设计为标准课程和进阶课程两部分内容,进阶课程针对不同细分场景侧重点进行深入,您可以根据自身情况选择进阶内容进行学习。
而通过标准课程安排,我们可以了解数据分析工作负载的工作流,包括数据摄取加载,存储,清洗转换,BI展现和机器学习的模型训练。关于标准实验内容,请阅读以下的实验概述:
实验概述
在实验动手环节,我们将学习数据分析工作负载的典型场景。我们将讨论如何建立数据分析端到端管道。以数据可视化和机器学习为最终目标。最终目标不仅仅是建立一个很棒的模型或是漂亮的可视化图表。它涉及的任务包括数据源,数据摄取,数据转换,预处理数据以及业务指标绘图,以及将这些数据用于训练,训练模型和托管模型。
AWS提供了多种服务来满足数据分析数据管道不同阶段的特定需求。该研讨会有多个实验室,专注于数据分析的不同阶段。最终我们将通过使用movielens公开数据集构建电影推荐引擎来演示机器学习管道的总体流程和设计。
关于该数据集的介绍:https://grouplens.org/datasets/movielens/
下图是本次动手训练营的标准课程整体实验架构图
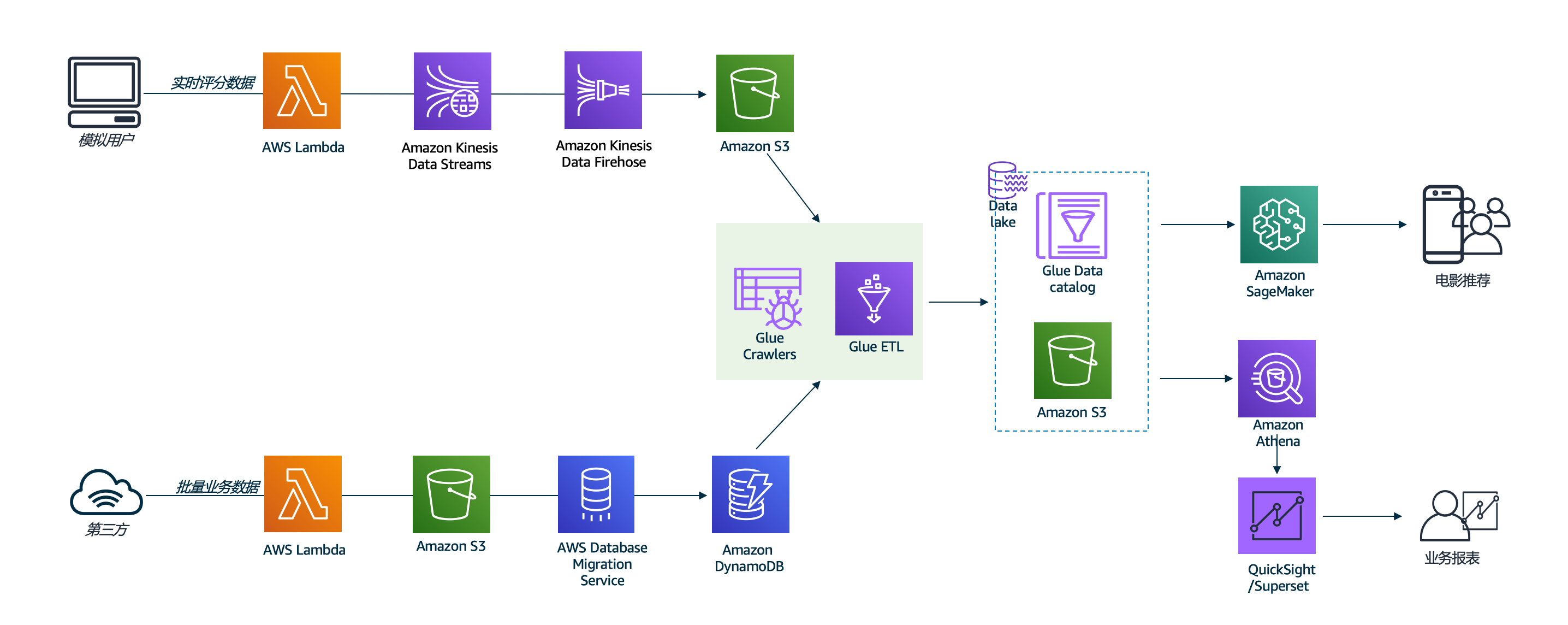
结合理论学习的划分,我们以数据分析负载的不同环节拆分成以下5个实验:
实验1-我们将从互联网上的外部来源获取电影数据集,将其存放在S3作为原始数据层,然后将其加载到Dynamo DB。在企业中,类似的数据可能已经存在于某些RDS,NoSQL或数据仓库系统中。可以一次性将数据作为批处理或实时数据流摄取。
实验2–根据具体的需求用例,可能需要同时进行批处理和流处理,或者仅需要进行批处理或流处理。在当前的研讨会中,我们将使用DMS一次性将一个完整的数据加载到Dynamo DB中,然后使用Lamda函数作为源数据生成模拟器将新记录传输到Kinesis流中以模拟流数据加载。
实验3-在本实验中,您将使用Glue数据目录在S3和DynamoDB中存储的数据上定义架构。您将对数据执行ETL,以准备将其用于机器学习和可视化。
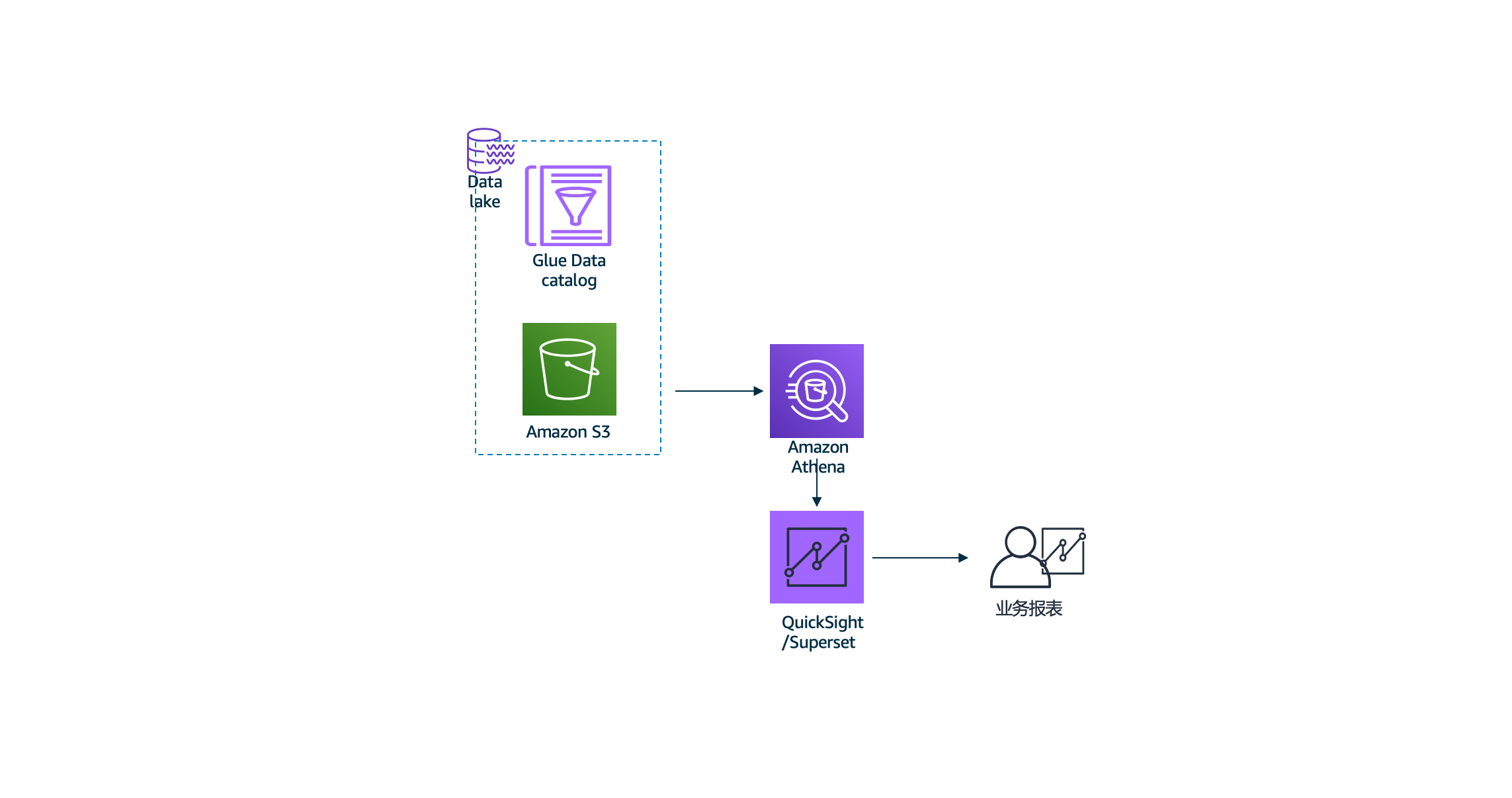
实验4-结合不同的行业或业务,我们会在实际需求中定义不同的举足轻重的业务指标,将他们可视化为业务报表以遍业务人员,决策人员进行优化业务的判断,在这里,我们实验superset和Athena搭建可视化报表。
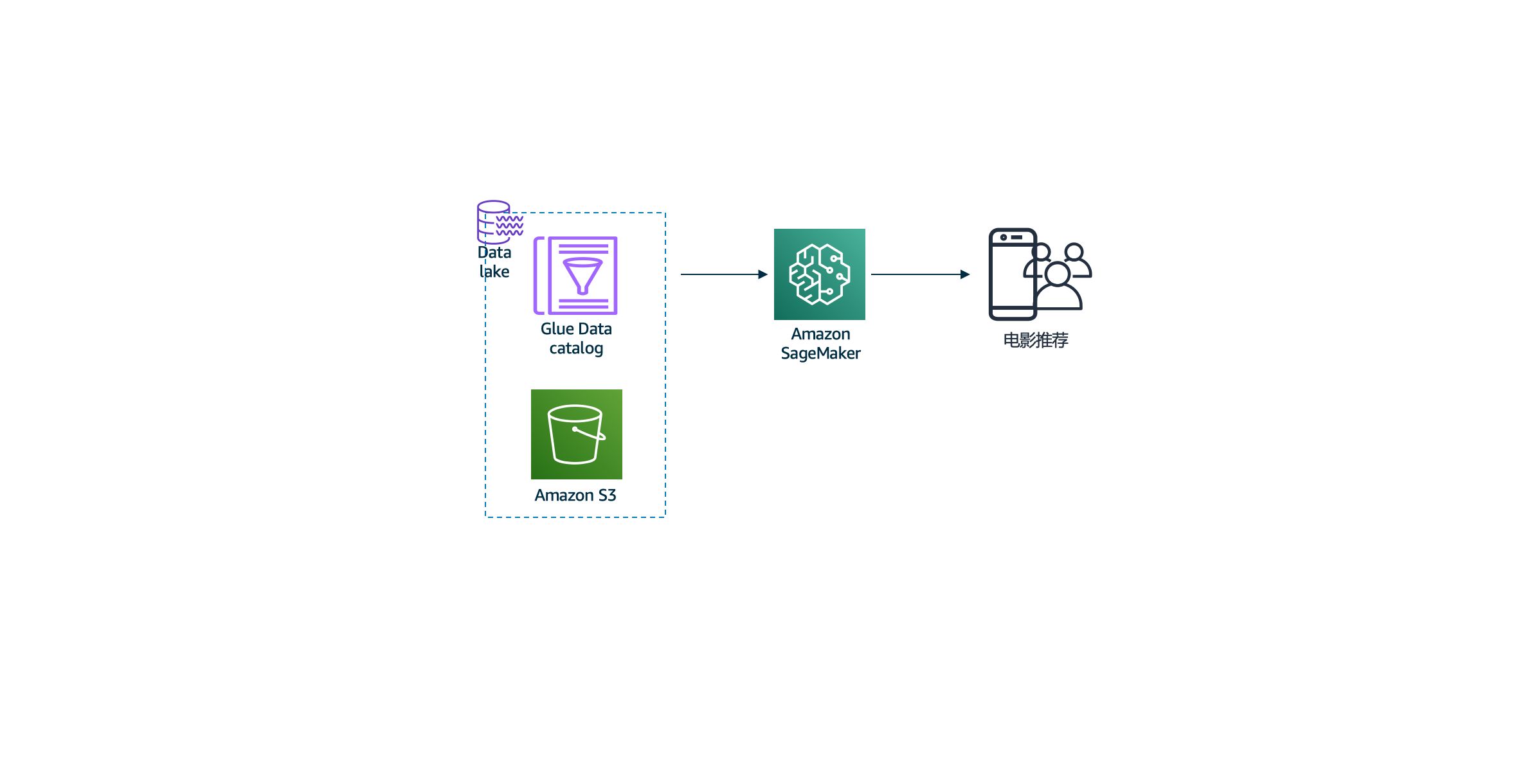
实验5-此时,您应该将所有文件都放在AWS S3存储桶中,以准备进行数据科学工作。我们将使用Amazon Sagemaker进行模型训练和推理。
实验是“顺序的”,参与者必须按顺序完成。每个实验都有参考资源和说明,以帮助您成功完成实验。
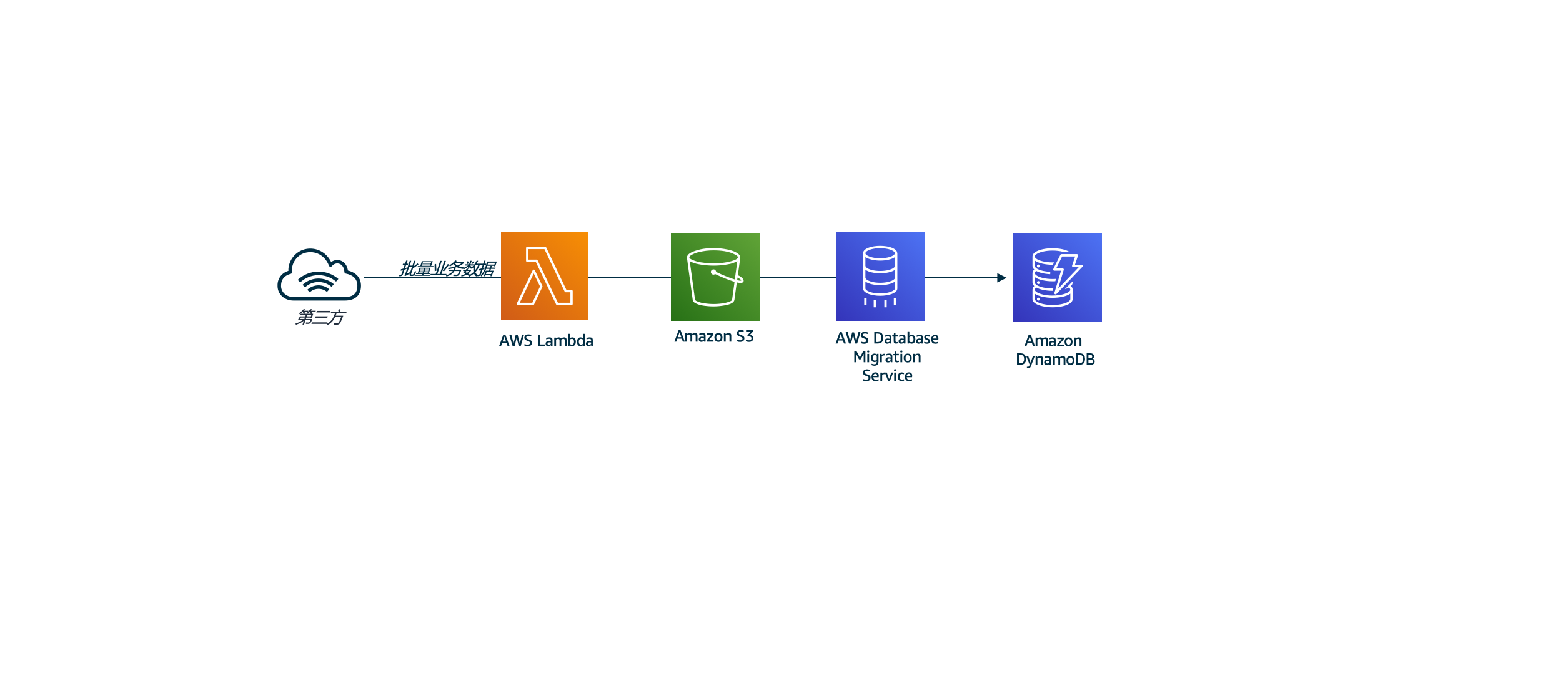
1, 使用 DMS 将数据从 S3 加载到 DyanamoDB
- 我们模拟批量的已有数据导入,使用lambda从互联网下载电影数据集,将其存放在S3,然后将使用DMS将数据加载到Dynamo DB。在企业中,类似的数据可能已经存在于某些RDS,NoSQL或数据仓库系统中,这些数据库均可以通过DMS将数据作为批量或实时数据流摄取。
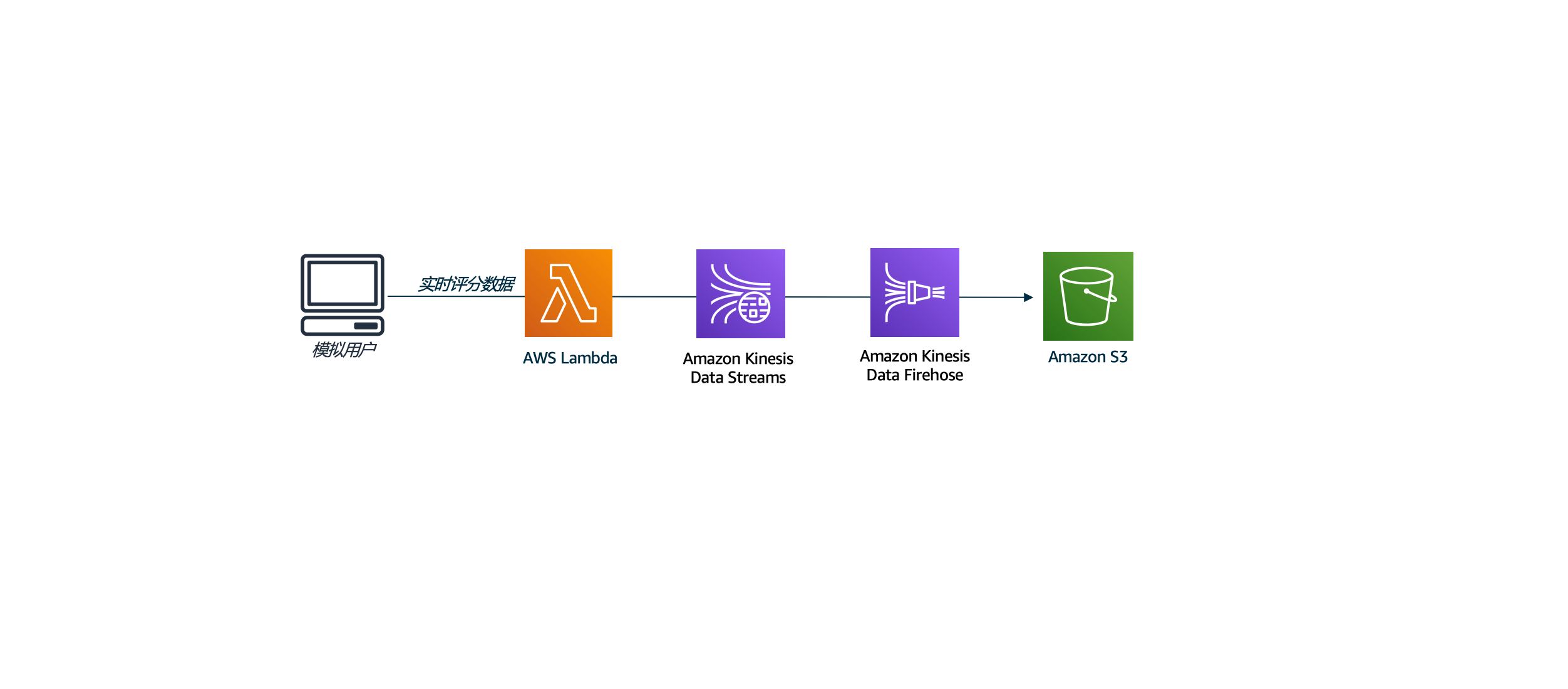
2, 使用 Kinesis 接入实时数据流
- 我们将创建一个lambda函数生成实时的数据,模拟真实业务中应用端流式的将数据向数据湖加载。lambda生成的数据将首先经过kinesis data stream,再经过kinesis dara Firehose,之后到达S3。
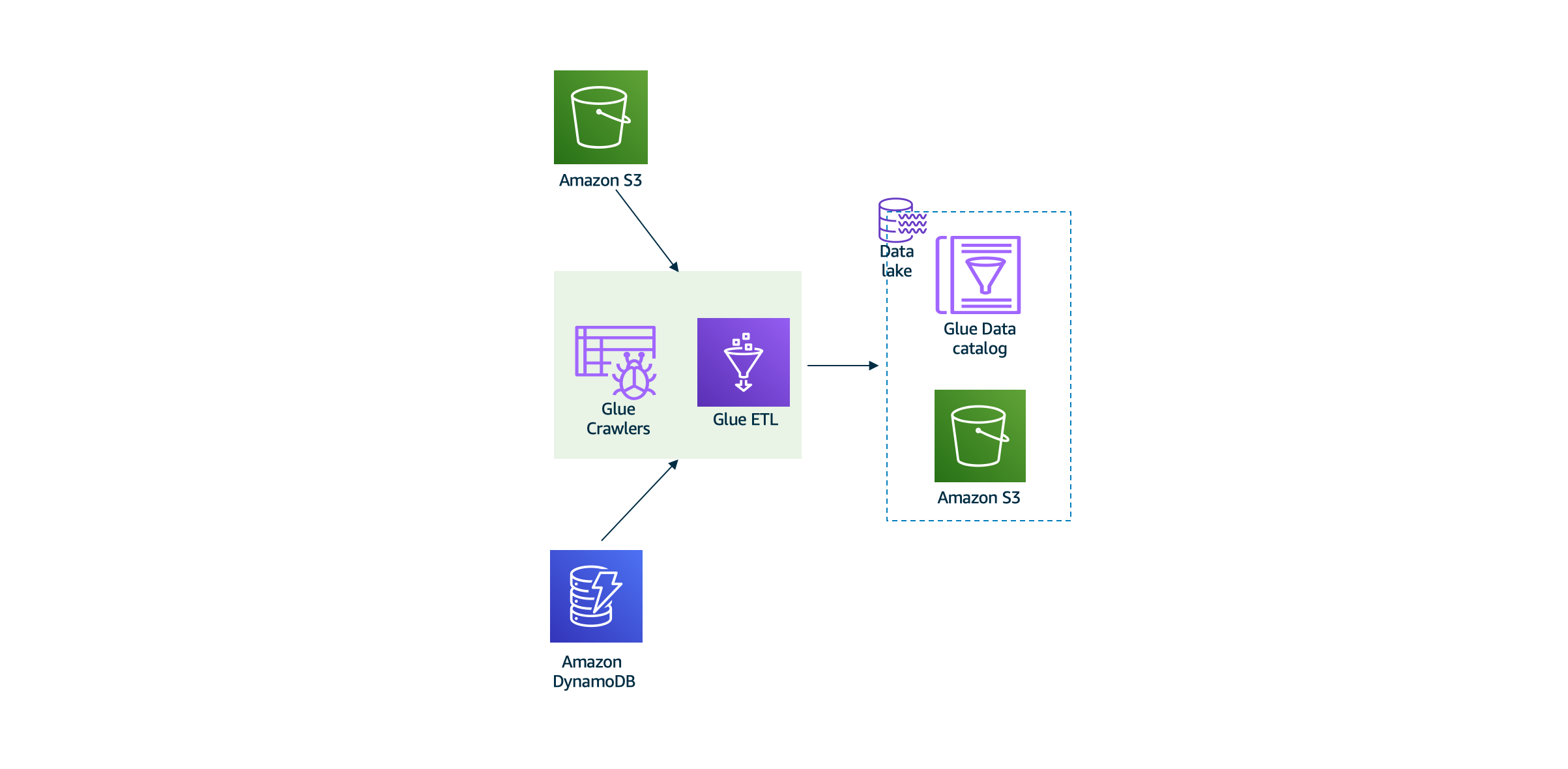
3, 使用 AWS Glue 进行数据ETL
- 我们将使用Glue的网爬程序和ETL jop对上面两个实验加载到S3数据湖的数据进行ETL,将处理后的数据再保存到数据湖的另一位置。本环节将形成处理后的数据和数据表结构,以便能提供给更高级别的深度学习和可视化报表使用。
4, 使用superset和Athena进行数据可视化
- 针对处理后的数据,我们将使用Athena读取Glue中的表结构,读取S3中的数据进行SQL查询,再使用superset进行可视化的展示。
5, 使用sagemaker进行数据湖上的机器学习
- 该环节将使用Sagemaker的Jupyter notebook组件进行模型训练和推理,最终实现电影推荐模型的API可对外服务。
进阶内容
可选练习
除了标准课程中的内容,我们准备了6项进阶课程作为训练营的可选内容,例如EMR上spark hive 作业的参数调优、使用Spot构建workflow、Hudi实现增量数仓等等。您可以根据自身情况选择有兴趣的内容进行学习和实验。这些进阶内容将在大数据领域的一些细化场景进行深入。合作伙伴架构师将提供帮助和指导,同时可能将根据当日训练营的学习进度组织定向的拓展学习:
| 预计完成用时 | 课题 | 实验组件 |
|---|---|---|
| 120 mins | 模块6: 合作伙伴产品及流行的开源组合 | 实验6: Airflow & Amazon EMR spot |
| 160 mins | 模块7: 使用EMR上的近实时增量数据 | 实验7: EMR Spark Streaming & Apach Hudi & AWS MSK |
| 160 mins | 模块8: EMR上的hive和spark作业调优实践 | 实验8: TPC-DS Hive & spark 调参与最佳实践 |
| 120 mins | 模块9: 自动化弹性的数据分析平台 | 实验9: EMR auto scaling |
| 120 mins | 模块10: 无服务器查询引擎 | 实验10: Athena联邦查询和用户自定义函数 |
| 160 mins | 模块11: 数据湖安全与权限管理 | 实验11: EMR multi-tenant & Ranger |
- 按需定制的数据流–Airflow & EMR spot
- EMR上的近实时增量数仓–EMR Spark & Hudi & MSK
- Hive/Spark on EMR最佳实践–Hive/Spark作业调参
- 自动化弹性的数据分析平台–EMR auto scaling
- Athena高级功能–Athena Federation/UDF/ML Query
- 数据湖安全与权限管理– Kerberos, EMRFS & Ranger
![]()