批量数据处理
大多数分析类应用程序都需要频繁的批处理过程,例如使用预先汇总的结果更新数据存储,以使最终用户的表查询操作变得更快、更简单。批处理系统必须能够根据数据规模进行灵活伸缩,并与待处理数据集的大小等比例增长。 数据源的扩张速度极快,因此我们需要建立一套数据批处理系统,在保证灵活性的同时又不致违反合规要求。从业务需求的角度来看,批处理数据作业可能受到SLA(服务水平协议)的约束,或者需要考虑一定的预算阈值。这些要求的具体情况,将直接决定整个批处理架构的实际特征。
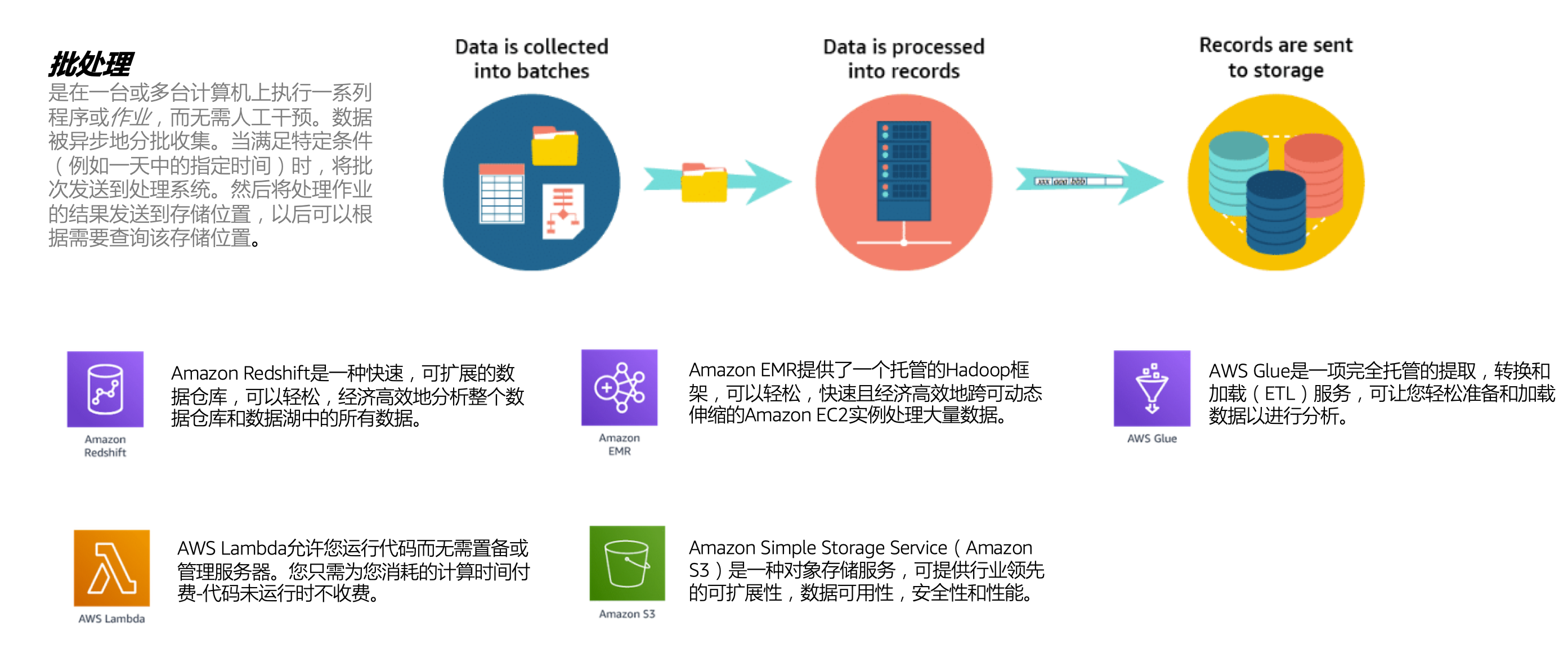
在AWS中,包括Amazon EMR、AWS Glue及AWS Batch在内的多项服务,都能帮助用户以可动态伸缩的方式通过EC2实例或全托管环境运行分布式计算框架。在批处理环境中,Amazon EMR能够面向Amazon S3、NoSQL on DynamoDB、SQL on Amazon RDS、Amazon Redshift、Hadoop分布式文件系统(HDFS)等进行数据读写操作。此外,您还可以选择Spark、MapReduce及Flink等流行框架将工作负载分发至多个动态扩展集群当中。AWS Batch可利用部署在动态可扩展容器计算基础设施上的Docker容器运行独立作业或作业阵列。使用AWS Glue,您可以直接运行Spark作业而无需管理任何EC2实例。
通过独立于批处理计算环境之外的外部来源进行数据读取与写入,系统得以将存储资源与计算资源明确拆分开来。以此为基础,您只需要在当前作业调度完成之后检查正在运行的Amazon EMR、AWS Batch以及AWS Glue资源。这种特征,也标志着批处理系统的传统范式开始发生转变。现在,系统只会在计算资源实际处理数据时,才临时运行批处理程序。Amazon EMR与AWS Batch等服务也与EC2竞价实例高度集成,您可以按需求选择EC2竞价实例,借此获得远低于EC2按需实例的资源使用成本。
特点
- 您希望创建一套批量数据处理系统,且将集群与计算资源的管理开销控制在最低水平。
- 您希望缩短业务或最终用户在运行洞见查询时所花费的时间,同时帮助他们更好地理解数据内容。
- 您希望仅在必要时通过批量系统处理计算资源,并在不需要时立即将其关闭。
参考架构
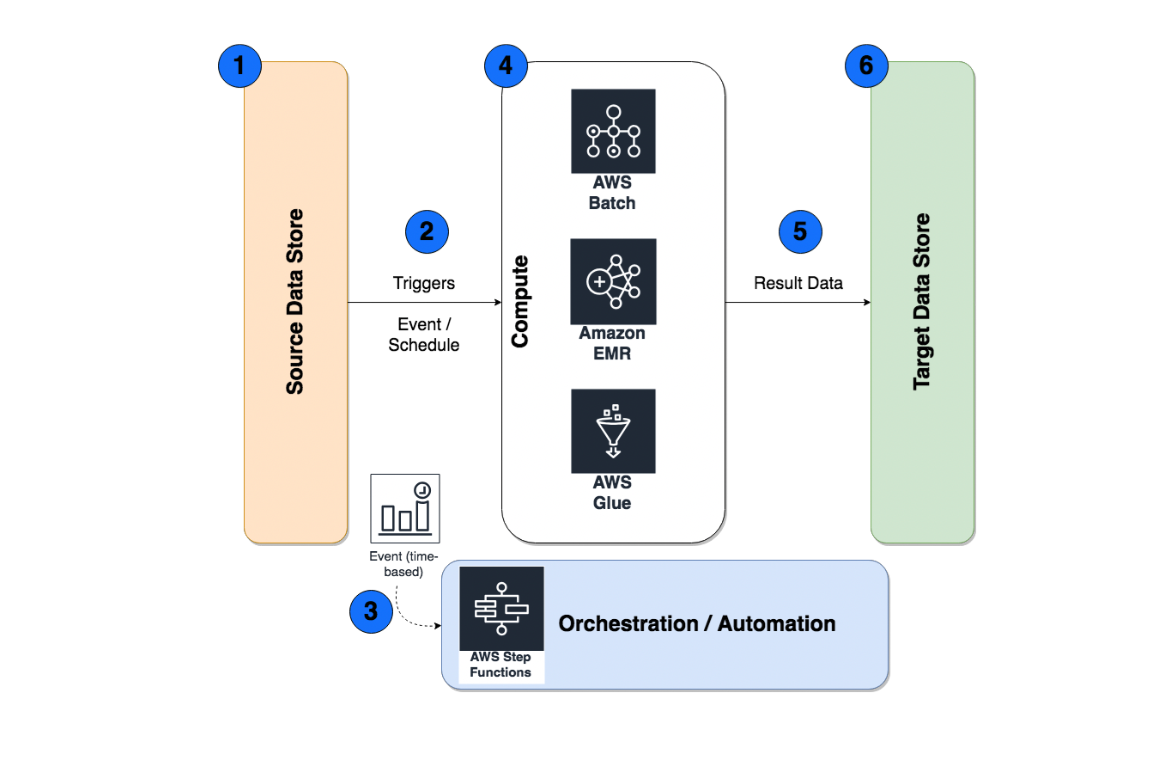
-
批量数据处理系统往往需要使用持久性存储以存储源数据,这一点对于提升系统可靠性非常重要。将源数据集保存在持久存储内时,您可以在发生故障后重试处理作业,并在后续随时查询数据集以进一步挖掘数据价值。在AWS上,我们为您提供丰富的源数据存储选项。作为托管数据库与存储服务,Amazon S3、Amazon RDS、Amazon DynamoDB、Amazon EFS、Amazon Elasticsearch Service、Amazon Redshift以及Amazon Neptune都可以作为源数据存储方案使用。此外,您还可以选择在Amazon EC2或EBS上运行自己的数据库或存储解决方案。关于这些选项的更多详细信息,请参阅“数据湖”与“为分析类负载构建高效存储层”部分的内容。
-
批量数据处理系统应该实现自动化,并通过调度保证可靠性、性能效率与成本优化。您可以使用Amazon CloudWatch Events根据计划(例如每天一次)或者事件(例如新文件的上传时间)触发对应的下游作业。
-
批量数据处理作业通常涉及多个步骤——其中某些步骤可能按序进行,也可能并行执行。通过编排服务(例如AWS Step Functions),您可以轻松针对或简单、或复杂的处理作业建立起自动化工作流。AWS Step Functions可通过可视化工作流构建起分布式数据处理应用。在AWS Step Functions工作流中,您可以使用Lambda函数与原生服务集成在Amazon EC2或本地设施上触发Amazon EMR步骤、AWS Glue ETL作业、AWS Batch作业、Amazon SageMaker作业以及其他自定义作业。
-
AWS Batch、AWS Glue以及Amazon EMR为您的特定用例提供适合的批处理作业托管服务与框架。根据实际作业类型,您可以选择不同选项。对于能够在Docker容器中运行的简单作业(例如视频媒体处理、机器学习训练以及文件压缩),AWS Batch可帮助用户轻松快捷地将作业以Docker容器的形式提交至Amazon EC2上的容器计算基础设施。对于PySPark或者Scala中的Apache Spark作业,您可以使用AWS Glue,此服务可在全托管Spark环境中运行各类Spark作业。对于其他规模较大的并行处理作业,您可以选择Amazon EMR,它能够在VPC内的Amazon EC2实例之上运行Spark、MapReduce、Hive、Presto、Flink以及Tez等多种流行框架。
-
与源数据存储类似,批处理作业也需要可靠的存储以保存作业输出及结果。您可以使用AWS SDK与Amazon S3及DynamoDB进行交互,并使用通用文件协议及JDBC连接将结果存储在文件系统或者数据库当中。
-
结果数据集往往也需要持久保存,以备后续通过可视化工具(例如Amazon QuickSight、API以及基于搜索的查询)进行访问。根据访问模式的不同,您可以选择最适合当前用例的数据存储解决方案。关于这些选项的更多详细信息,请参阅“数据湖”与“为分析类负载构建高效存储层”部分的内容。
配置说明
-
通过批处理作业准备出大规模批量数据集,以供下游分析使用。对于体量极大且高度复杂的数据集,您可能需要简化实际查询方式,帮助最终用户与分析师更轻松地获取数据内容。如若不然,用户可能会在查找简单聚合的操作中,发现原始数据的查询难度过大。例如,您可能需要提前将前一天的销售数据整理为每日销售摘要视图。这类经过整理的表往往包含相对较少的行与列,可帮助业务用户轻松便捷地完成数据查询。
-
避免将批处理直接迁移至AWS。如果直接将传统批处理系统迁移至AWS,可能导致Amazon EC2实例的资源出现过度配置问题。例如,本地部署中的传统Hadoop集群往往被过度配置且长期处于空闲状态。您应使用AWS托管服务(例如AWS Glue、Amazon EMR以及AWS Batch)简化佻的架构,借此消除集群及分布式环境管理等繁重的日常工作。 利用现代批处理架构,您可以利用AWS提供的各项服务将存储与计算资源剥离开来,借此消除闲置计算资源或未得到充分利用的磁盘存储空间,最终显著降低运营成本。此外,使用针对特定批处理任务进行优化的EC2实例类型(而非通用型持久集群),您也可以进一步提升性能表现。
-
尽可能使用自动化与编排工具。在传统批量数据处理环境中,系统最佳实践往往要求自动实现作业的执行与调度。在AWS中,您同样需要实现批量数据处理作业的自动化与编排,结合AWS API以启动及关闭整个计算环境,确保仅为实际使用的计算服务资源付费。例如,在作业编排完成后,您可以在工作流服务(例如AWS Step Functions)中使用AWS SDK配置新的EMR集群、提交作业并在任务完成后关闭该集群。
-
使用竞价实例保存较为灵活的批处理作业。对于相对较为灵活(可以随时重试)的批处理作业,您可以选择竞价实例并将数据与计算资源拆分开来。使用EMR与AWS Batch中的Spot Fleet、EC2 Fleet以及竞价实例等功能管理竞价型实例。
-
持续监控并改进批处理系统。随着数据源数量的增加,批处理系统需要快速发展、创造新的批处理作业,并启动新的批处理框架。通过指标、超时与警报,您将更从容地对作业进行检测、获取运行状态与分析洞见,并最终为批量数据处理系统的进一步改进做出明智决策。