模块7:EMR上的近实时增量数仓
要完成整个实验,大约需要3小时。
Apache Hudi用于在Apache Hadoop分布式文件系统(HDFS)或Amazon S3云存储上使用流处理原语(例如插入更新和增量更改流)来管理PB级数据湖。Hudi数据湖提供了新鲜的数据,比传统批处理效率高一个数量级。 2020年6月,Apache Hudi正式成为Apache顶级项目。
在本动手训练营中,您将学习使用Apache Hudi和Amazon EMR增量处理Amazon S3 Data Lake上的数据,除了通过技术概念的解读,您还将进行以下实验:
1, 源数据库到数据湖的增量数据复制(CDC)
2, 在Hudi上消费流式的增量数据
3, 满足GDPR要求的客户数据删除


Apache Spark为提供了一个优秀的的框架,她可以帮助我们构建数据处理管道,该框架几乎可以作为任何数据处理工作负载的基础架构核心。而时至今日,我们的需求不能局限于传统的批流处理框架,我们开始考虑如何建设一个增量数据处理管道。例如,从联机事务处理(OLTP)数据库中提取的事务数据,为我们的业务展示近实时的数据指标。 在本研讨会中,我们将带您逐步构建和优化基于Apache Spark的数据处理管道,并在管道中使用Apache HUDI支撑增量数据的处理。我们从基本流程开始,然后通过实际示例逐步介绍每个新概念。请准备好您的笔记本电脑,以便您可以自己构建数据处理管道。
Apache Hudi(Incubating)是一个开源数据管理框架,用于简化增量数据处理和数据管道开发。 Apache Hudi使您能够在Amazon S3中以版本记录形式管理数据,以简化变更数据捕获(CDC)和流式数据提取,并提供了一个框架以版本记录的形式处理需要更新和删除的隐私数据。由Apache Hudi管理的数据集使用开放存储格式存储在S3中,并且与Presto,Apache Hive,Apache Spark和AWS Glue数据目录的集成使您可以使用熟悉的工具近乎实时地访问更新的数据。
什么是Apache Hudi
Hudi与Apache Spark,Apache Hive和Presto集成在一起。在Amazon EMR 5.28.0版和更高版本中,Amazon EMR默认在安装Spark,Hive或Presto时安装Hudi组件。您可以使用Spark或Hudi DeltaStreamer实用程序来创建或更新Hudi数据集。您可以使用Hive,Spark或Presto交互式地查询Hudi数据集,也可以使用增量拉取构建数据处理管道。增量提取是指仅提取两次操作之间发生变化的数据的能力。 简单来说,Apache Hudi用于在Apache Hadoop分布式文件系统(HDFS)或云存储上使用流处理原语(例如插入更新和增量更改流)来管理PB级数据湖。Hudi数据湖提供了新鲜的数据,比传统批处理效率高一个数量级。核心功能包括:
-
可插拔式的索引支持快速Upsert / Delete。
-
事务提交/回滚数据。
-
支持捕获Hudi表的变更进行流式处理。
-
支持Apache Hive,Apache Spark,Apache Impala和Presto查询引擎。
-
内置数据提取工具,支持Apache Kafka,Apache Sqoop和其他常见数据源。
-
通过管理文件大小,存储布局来优化查询性能。
-
基于行存快速提取模式,并支持异步压缩成列存格式。
-
用于审计跟踪的时间轴元数据。
Hudi的应用场景
使用Hudi,您可以在S3上执行拥有版本记录的数据插入,更新和删除。创建数据集和表,然后Hudi管理基础数据格式。 Hudi使用Apache Parquet和Apache Avro进行数据存储,同时Hudi与Spark,Hive和Presto内置集成,使您能够使用正在使用的工具来查询Hudi数据集,几乎实时地访问新鲜的数据。这些功能使Hudi适用于以下用例:
-
使用来自传感器和其他需要特定数据插入和更新事件的物联网(IoT)设备的流数据。
-
选择删除用户部分隐私数据或修改其使用数据方式的应用程序,以便遵守数据隐私法规。
-
部署在变更数据获取(CDC)系统,使您可以随时间将更改应用于数据集。
随Amazon EMR 5.28.0默认安装的Hudi版本为0.5.0-incubating。
Hudi如何工作
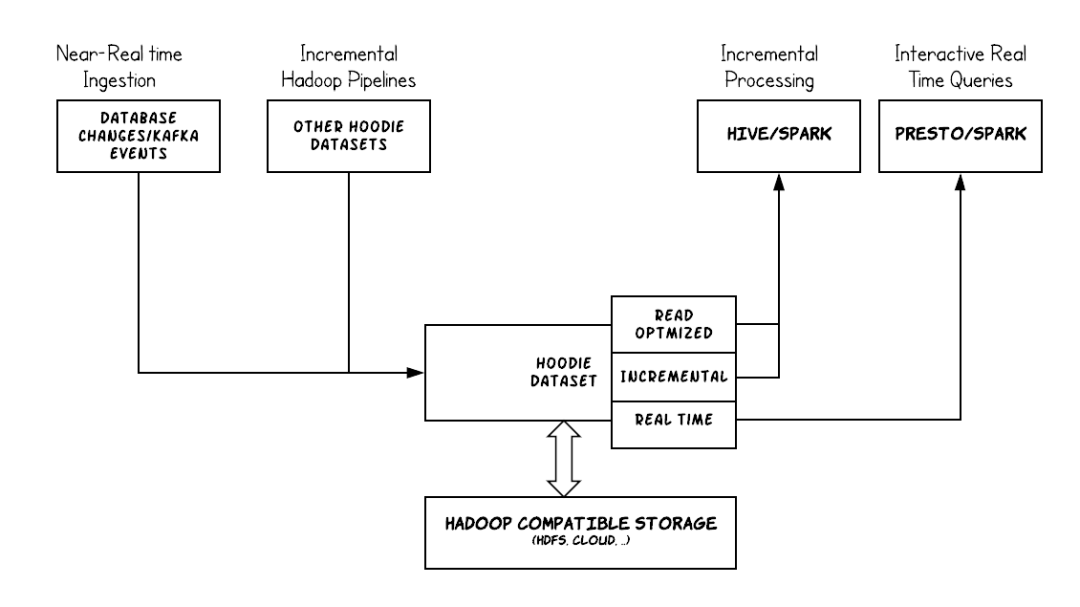
将Hudi与Amazon EMR结合使用时,可以使用Spark Data Source API或Hudi DeltaStreamer程序将数据写入数据集中。 Hudi将数据集调度存放到类似于传统Hive表的基本路径下的分区目录结构中。在这些目录中的文件中,数据的布局方式具体取决于您选择的数据集类型。您可以选择写入时复制(CoW)或读取时合并(MoR)。
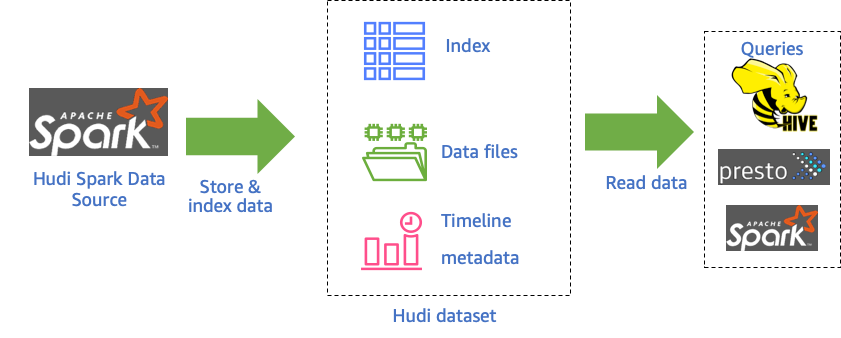
无论数据集的类型是哪种,数据集中的每个分区均由其基本路径的partitionpath作为唯一标识。在每个分区内,记录被分布到多个数据文件中。 Hudi中的每个动作都有一个相应的提交,该提交由提交时瞬间的时间戳以递增的形式进行标识。 Hudi会将一系列在数据集上执行的所有动作作为时间轴保留。 Hudi依靠时间轴在读取器和写入器之间提供快照隔离,并能够回滚到上一个时间点。有关Hudi记录的操作以及操作状态的更多信息,请参阅Apache Hudi文档中的时间轴。
Hudi的存储类型
创建Hudi数据集时,您可以指定该数据集是写入时复制还是读取时合并
-
写入时复制(CoW)–数据以列格式(Parquet)存储,并且每次更新都会在写入过程中创建文件的新版本。 CoW是默认存储类型。 -
读取时合并(MoR)–数据使用列式(Parquet)和基于行(Avro)格式的组合存储。更新记录到基于行的增量文件中,并根据需要进行压缩以创建列文件的新版本。
对于CoW数据集,每次对记录进行更新时,都会使用更新后的值来重写包含记录的文件。对于MoR数据集,每次更新时,Hudi都只为更改的记录写行。 MoR更适合读取次数少的写入或更改繁重的工作负载。 CoW更适合于频繁更改数据的读取繁重的工作负载。

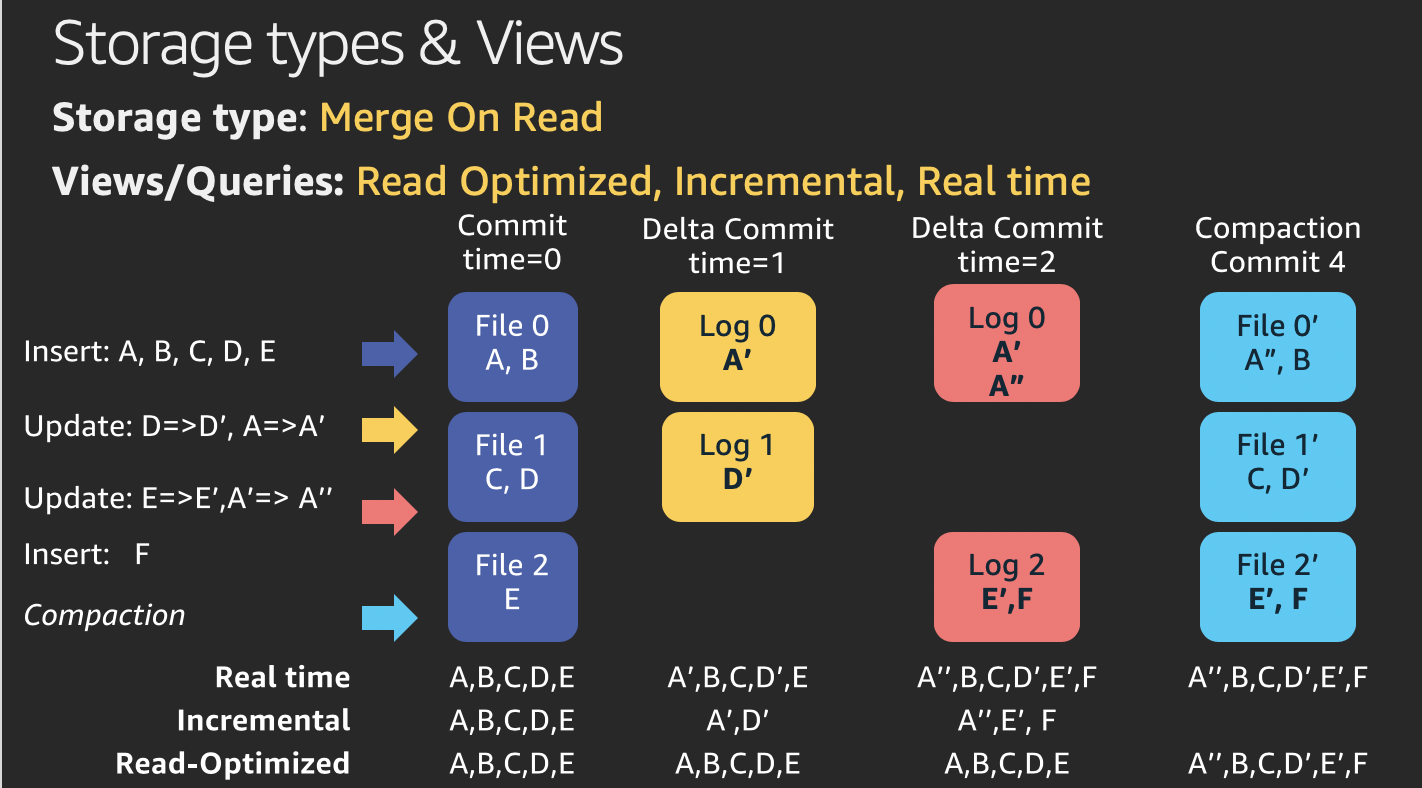
Hudi的视图
Hudi提供了三种逻辑视图来访问数据
-
读优化视图–提供CoW表中最新的提交数据集和MoR表中最新的压缩数据集。 -
增量视图–提供CoW数据集中两个动作之间的变化流,以馈送下游作业以及提取,转换,加载(ETL)工作流。 -
实时视图–通过内联合并基于列和基于行的文件,从MoR表中提供最新提交的数据