实验1:DMS+S3+DyanamoDB
使用 DMS 将数据从 S3 加载到 DyanamoDB
- 我们模拟批量的已有数据导入,使用
lambda从互联网下载电影数据集,将其存放在S3,然后将使用DMS将数据加载到Dynamo DB。在企业中,类似的数据可能已经存在于某些RDS,NoSQL或数据仓库系统中。可以一次性将数据作为批处理或实时数据流摄取。
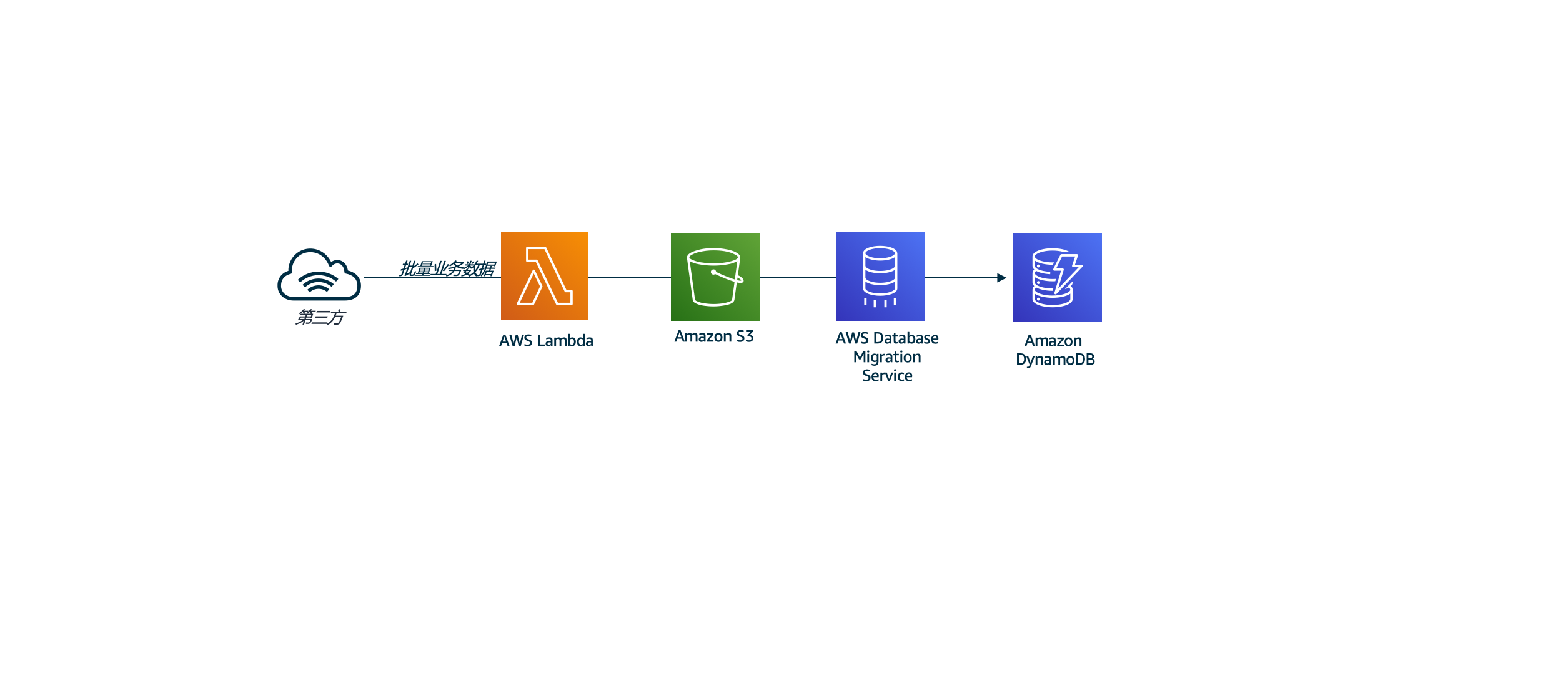
资源清单
我们将使用CloudFormation模板配置以下资源:
- Amazon S3存储桶,用于保存movielens数据。
- 提供访问数据库迁移服务的权限的IAM角色,以访问和供应其他AWS资源
- VPC,子网,Internet网关和安全组以支持DMS复制实例工作。
- DMS复制实例和DMS任务
- Lambda-1将电影数据从外部源复制到帐户的S3存储桶中。
- Lambda-2函数启动DMS任务复制。
实验选项:
如果您是一个人使用自己的AWS账户或是使用PSA导师发送的AWS Event Engine账号进行实验,建议您使用Cloudformation启动环境。而如果您是多人使用同一账户的不同IAM User进行实验,建议您手动搭建环境进行实验,并在必要时明确区别您和他人的资源命名,例如在任何资源名后加入-user1。
使用Cloudformation搭建环境
1.使用有效凭证登录AWS控制台
2.选择AWS区域。 此实验室的首选区域是中国宁夏。
- 您可以点击以下的 Launch Stack ,这样将直接跳转到首选区域的堆栈创建页面
| 账户所属 | 实验模板 |
|---|---|
| 中国区域账户 |  |
| 海外区域账户 | |
3.若您选择自定义的区域后,请导航到Cloudformation服务控制台。
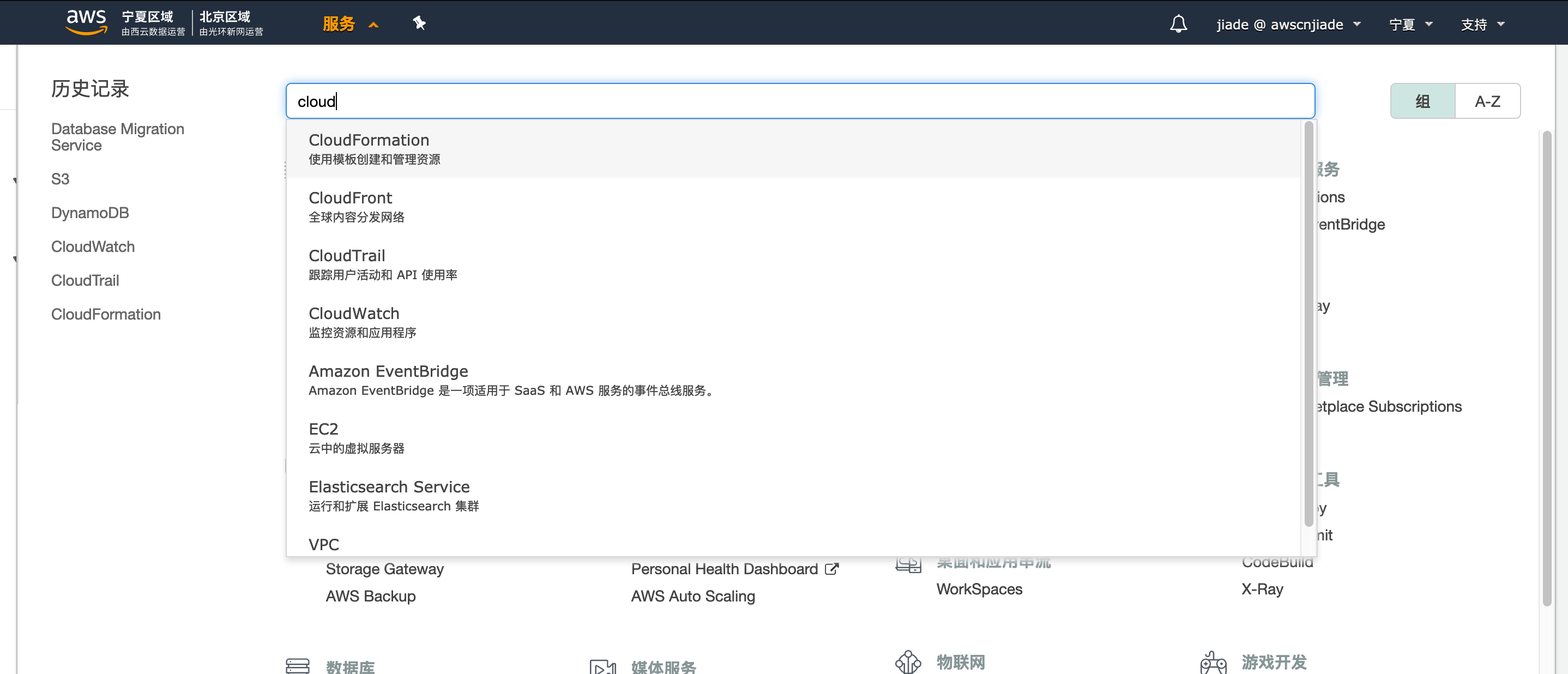 4.填写对应的堆栈URL,单击“创建堆栈”。
4.填写对应的堆栈URL,单击“创建堆栈”。
5.单击“启动堆栈”按钮以启动堆栈,然后单击“下一步”:
6.将堆栈名称指定为partner-workshop,然后单击“下一步”。
 7.单击“下一步”。
7.单击“下一步”。
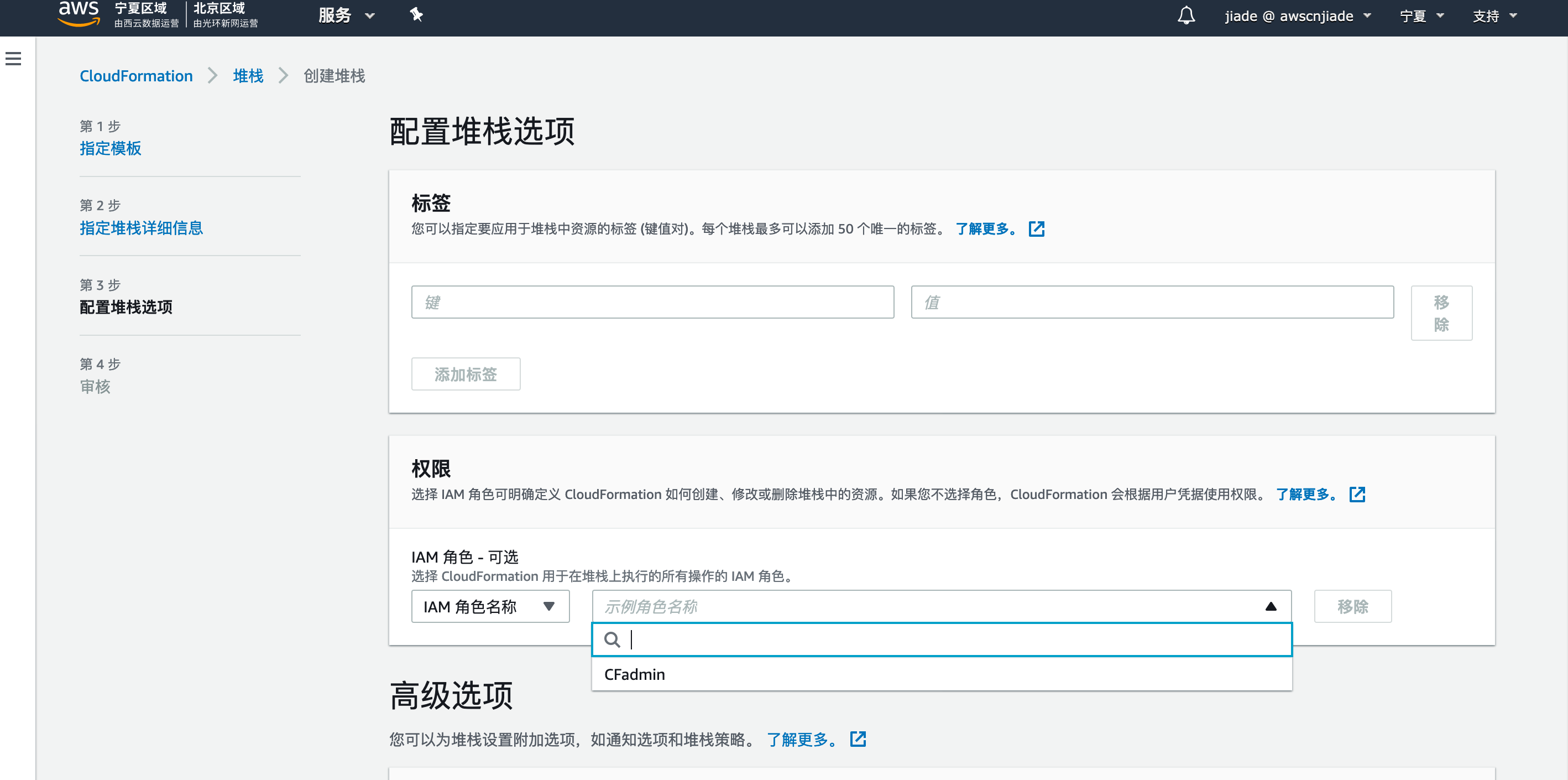 8.确认使用自定义名称创建IAM资源的权限,然后单击“创建”。
8.确认使用自定义名称创建IAM资源的权限,然后单击“创建”。
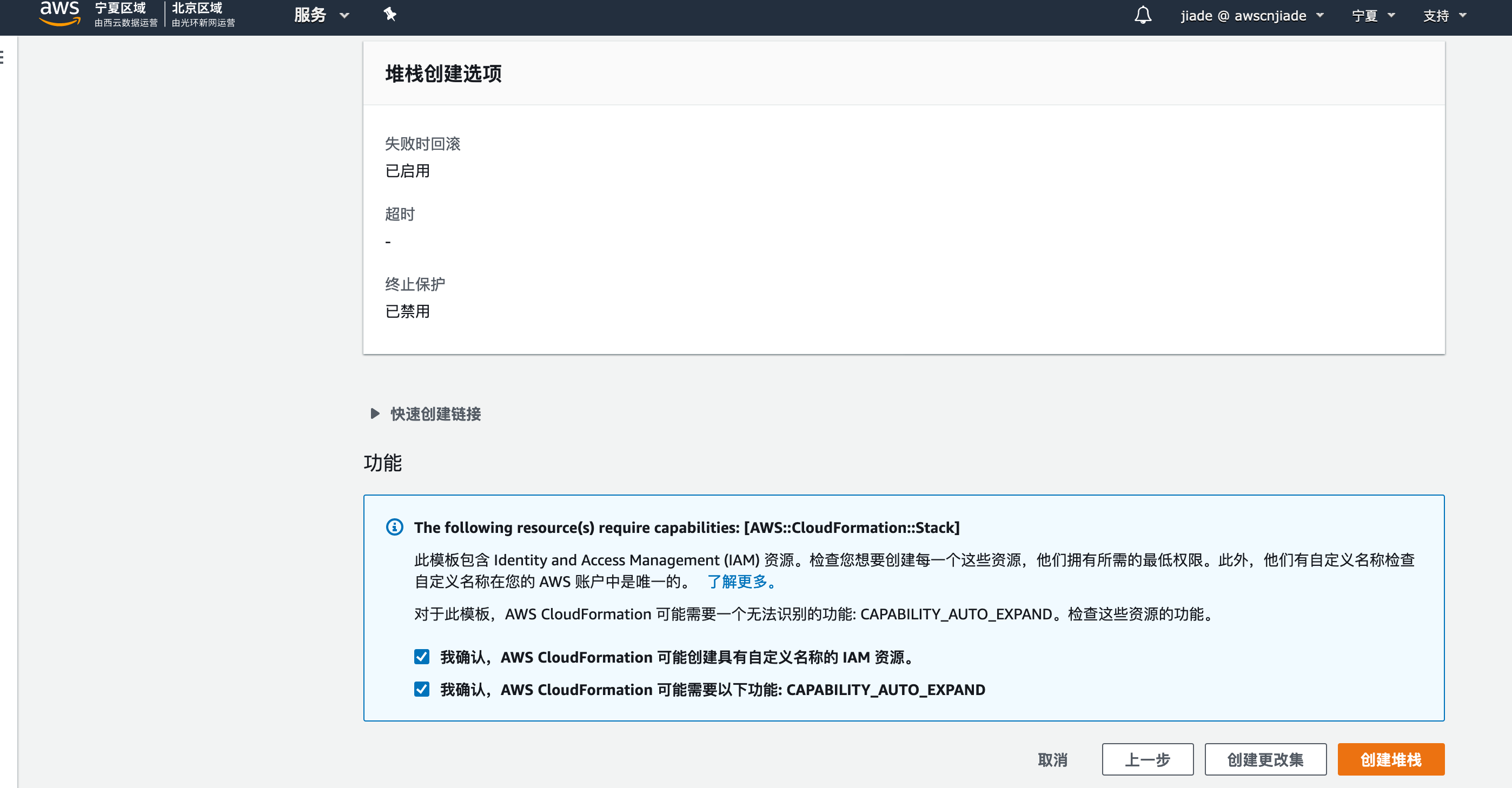 9.等待Cloudformation供应所有资源。 大约需要15分钟才能完成执行
9.等待Cloudformation供应所有资源。 大约需要15分钟才能完成执行
如果您遇到dms-vpc-role已存在的报错,可能是您在之前的使用中已经自动创建了这个角色,为保证实验的大众简便性请您到IAM控制台删除这个角色,重新运行Cloudformation将避免报错并再为您创建dms-vpc-role。
验证步骤
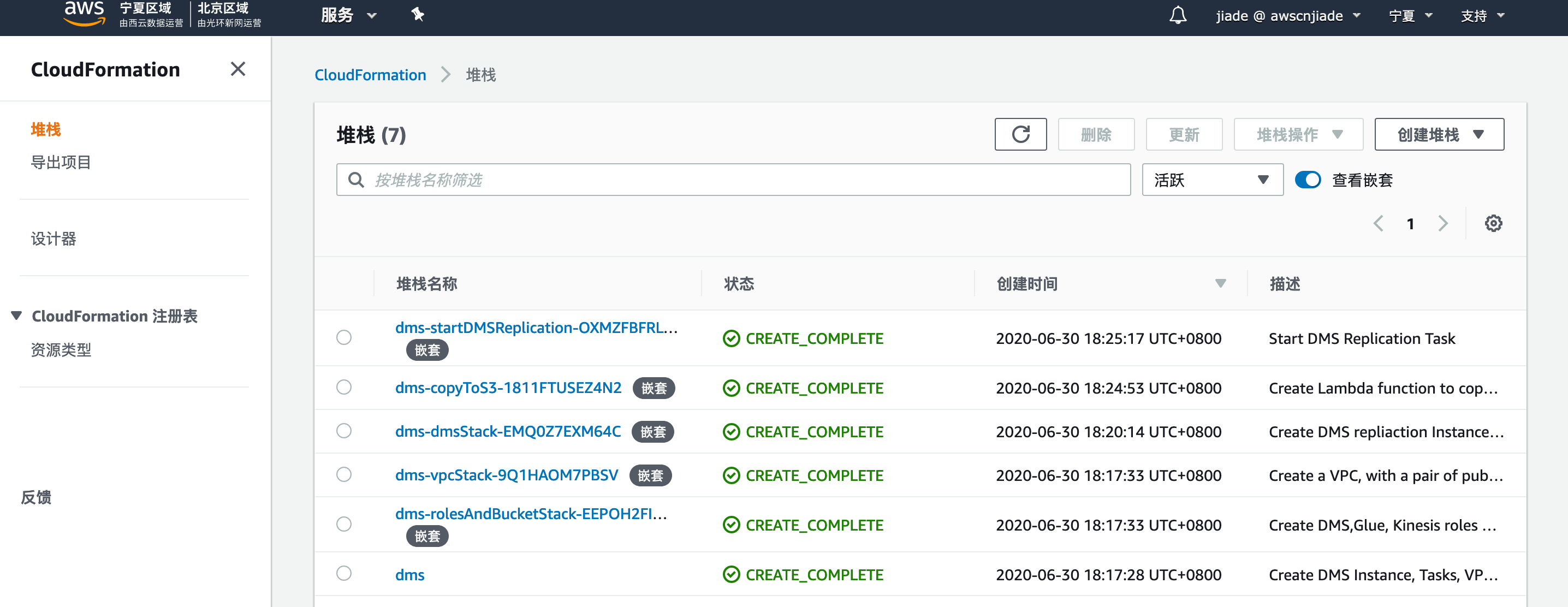
- 在CloudFormation控制台中验证DMS堆栈已成功创建。
- 单击服务,搜索DMS,然后单击数据库迁移服务。
- 点击“任务”。
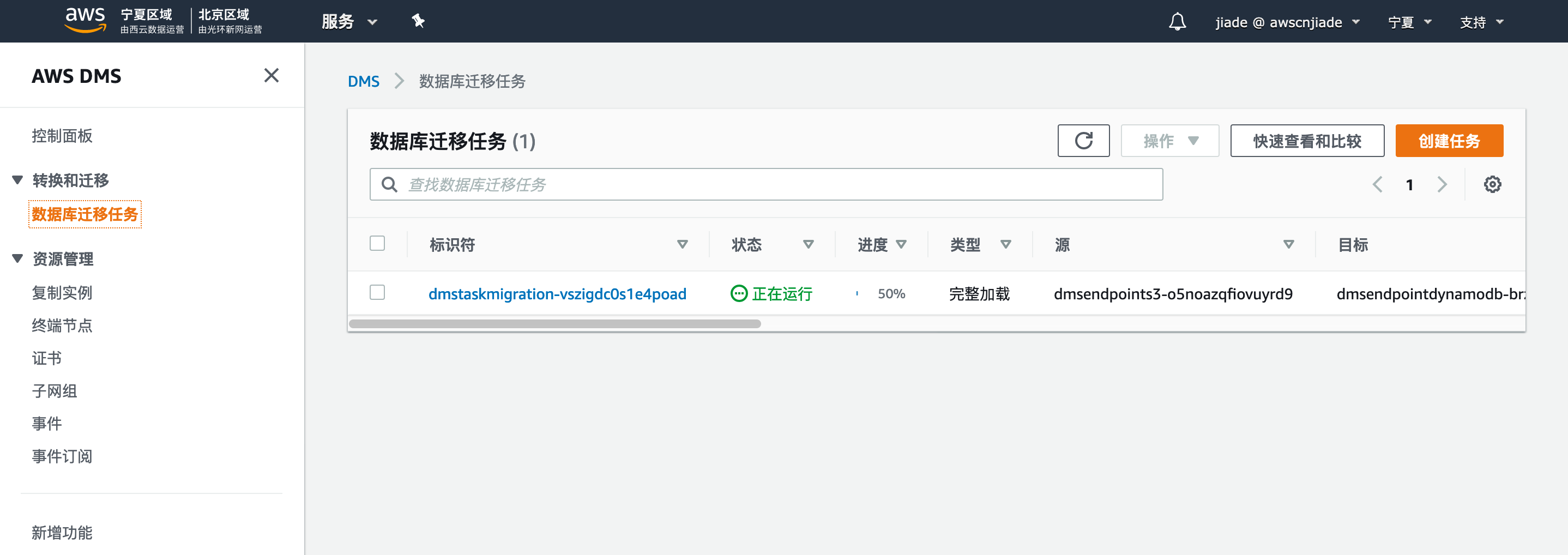
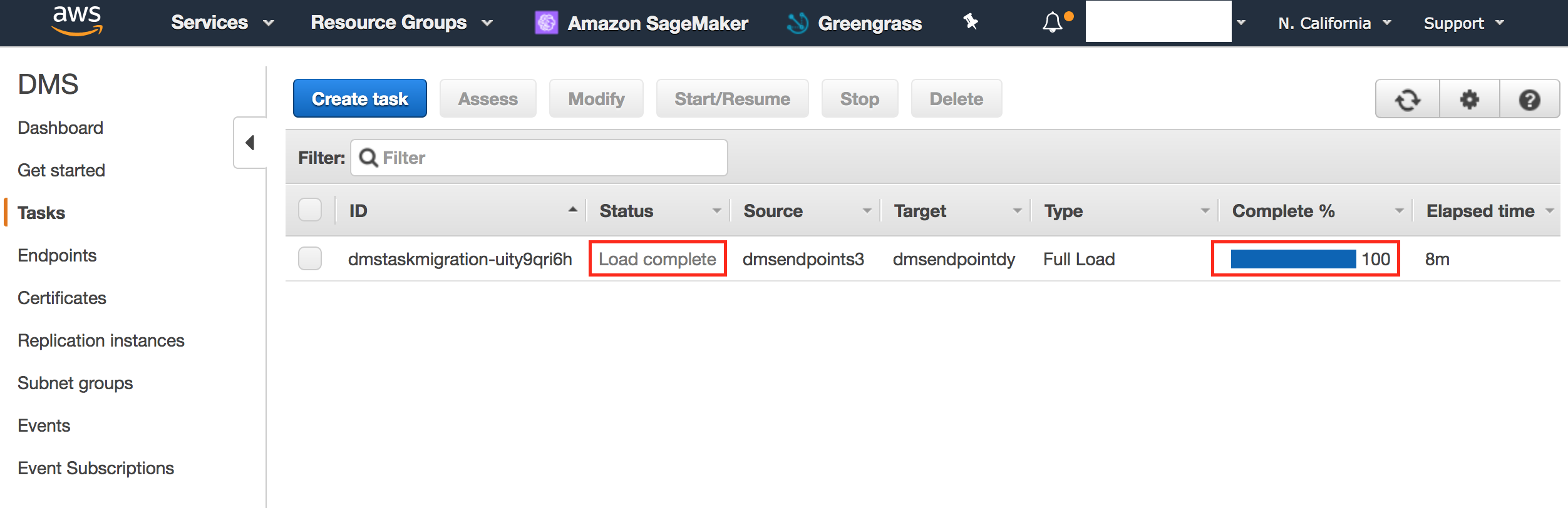
- 确认负载已完成100%,状态为“负载已完成”。
- 单击“服务”,搜索Dynamo,然后单击“ DynamoDb”。
- 点击“表格”。
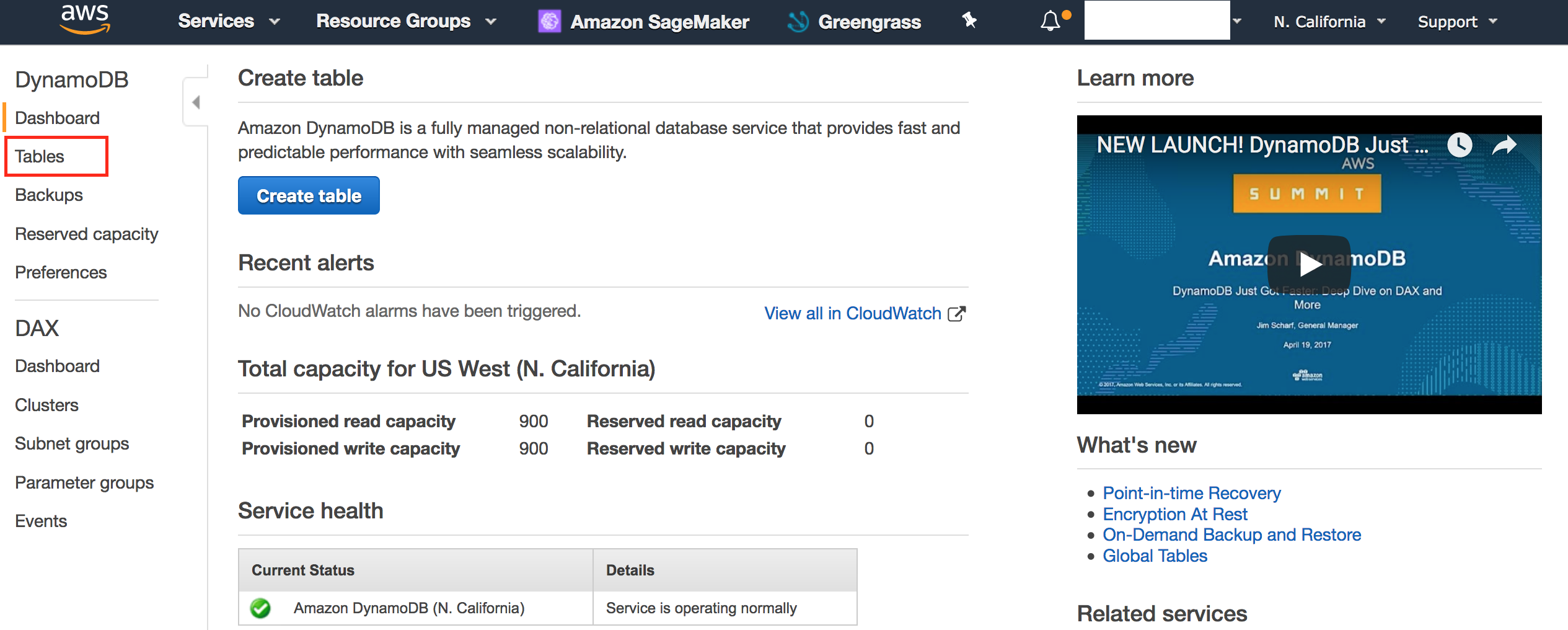
- 确认已创建5个表。
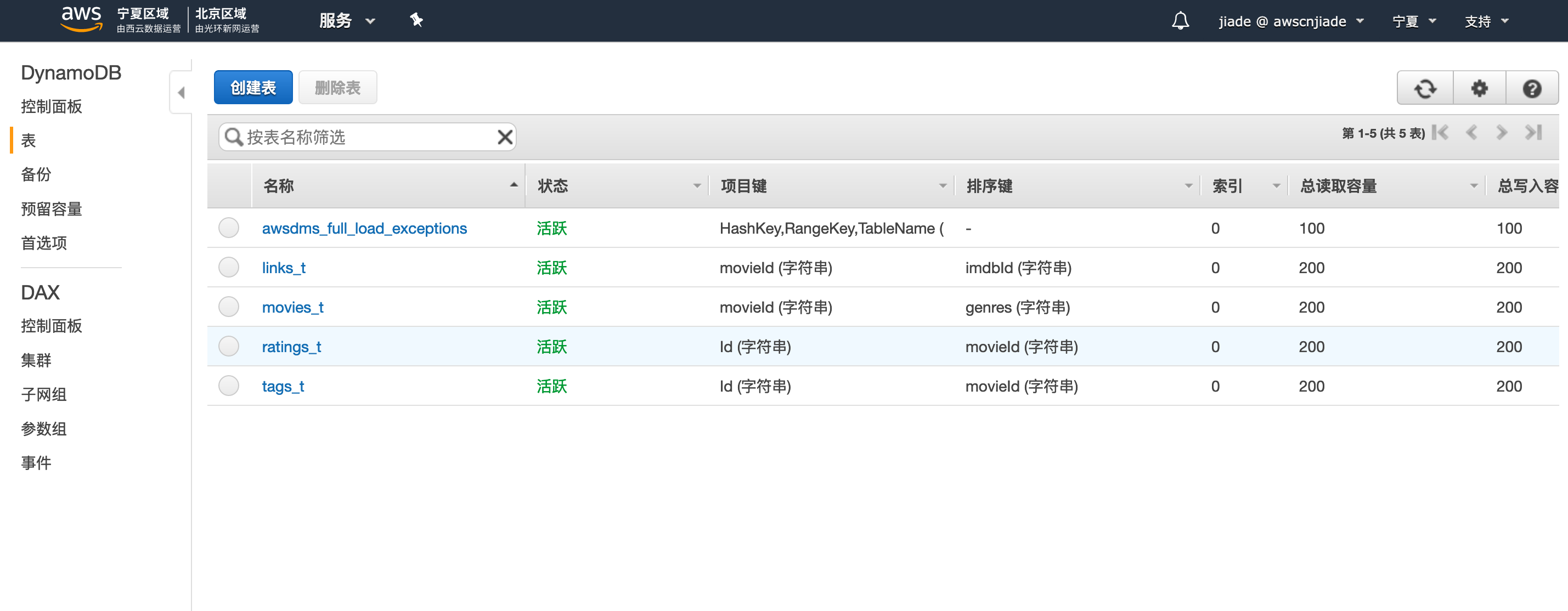
- 单击awsdms_full_load_exceptions表中有0个项目。
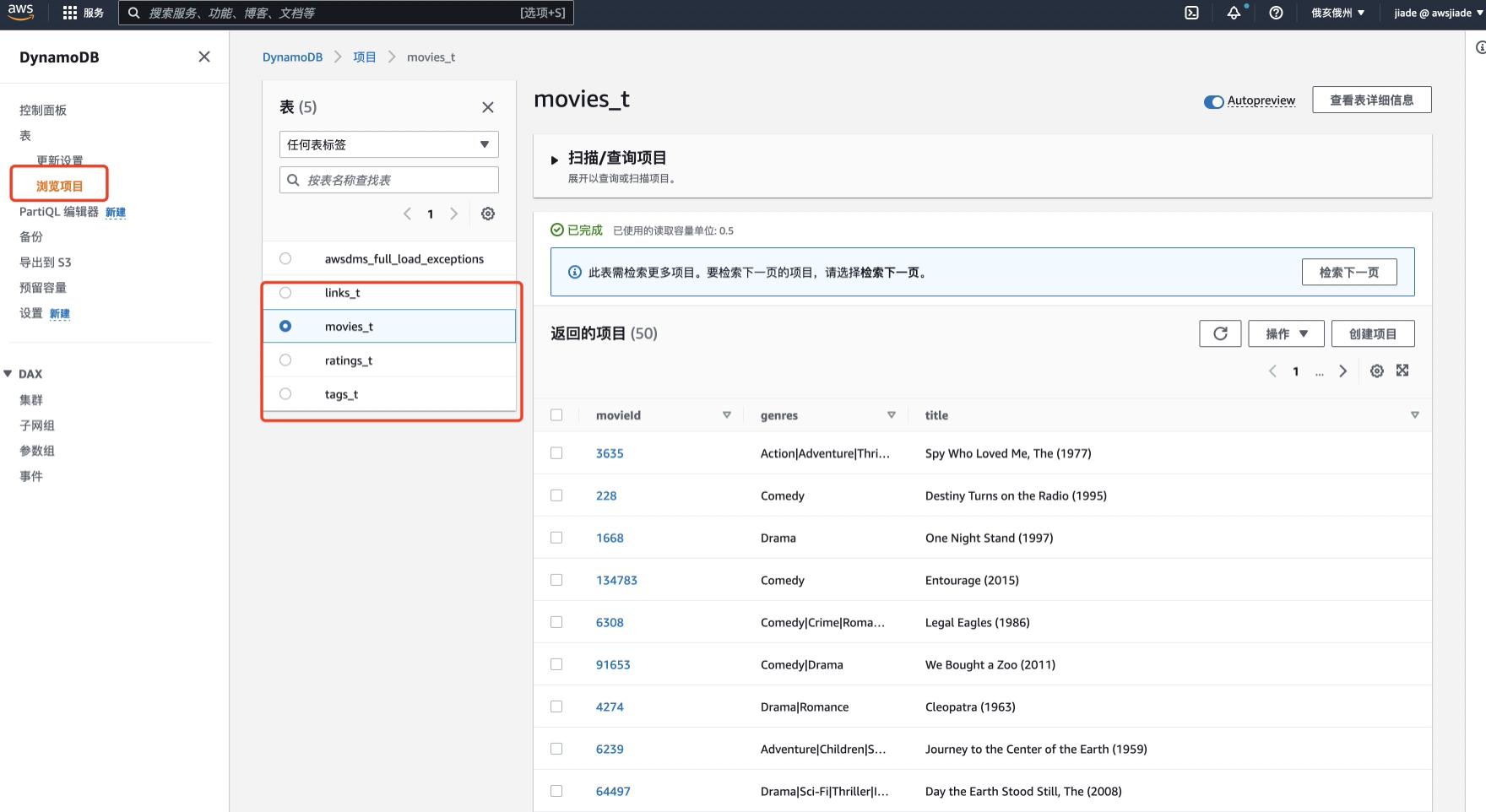
- 单击links_t表,并确认项目不为空。

- 单击movies_t表并确认项目不为空。

- 单击rating_t表并确认项目不为空。

- 单击tags_t表,并确认项目不为空。

恭喜!!您已成功完成实验 1
您可以到您的S3桶,lambda日志去检查数据和日志,以便理解我们的Cloudformation执行了如您所预想的工作
注意:在继续其他练习之前,请记下在练习1中创建的s3存储桶。
1.单击服务,搜索S3
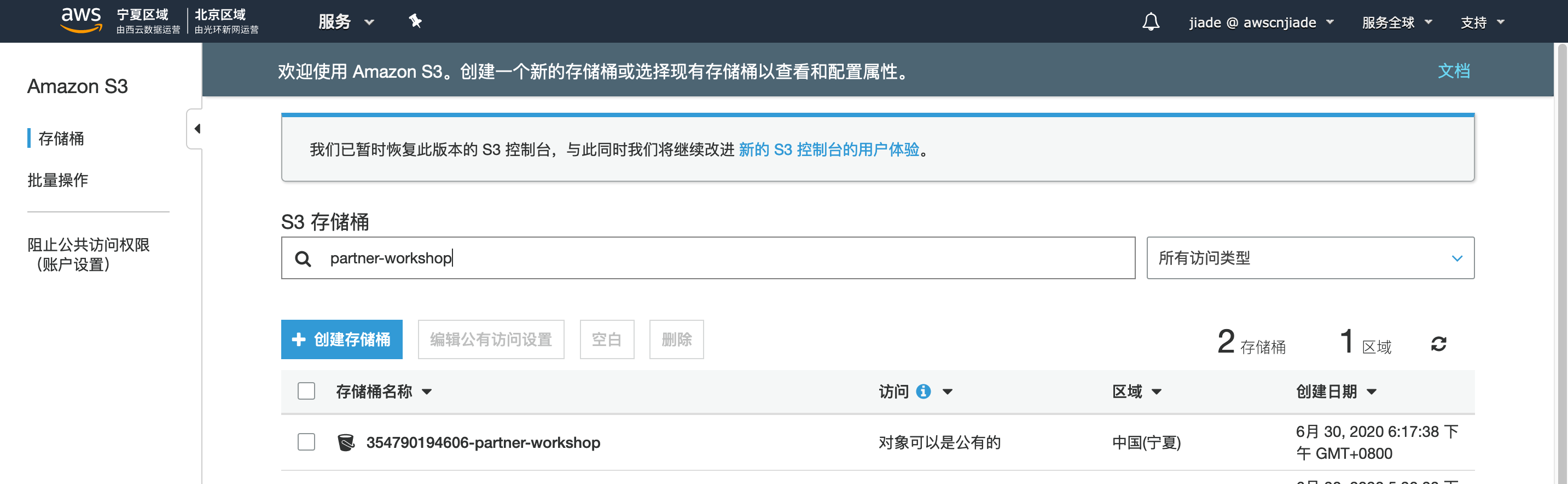
2.单击服务,搜索S3。 复制存储桶xxxx-partner-workshop的名称。 我们将在以后的实验中使用此名称。
以上,我们完成了实验1的内容, 我们的lambda从指定的网站下载了数据集,将数据集保存在s3中,dms将s3中的数据进行格式转换并存储在不同的dynamoDB表中。 现在,为了巩固理解,你可以到lambda,S3,DMS,dynamoDB控制台页面去查看,并对照试验架构图和Cloudformation、lambda代码思考,自动执行的整个流程是否如您计划
手动搭建环境
如果您已经使用Cloudformation成功创建环境,那么请跳过手动部署环境的环节,跳转至实验2.
如果您使用的是AWS Event Engine账号或是使用多个IAM账号在同一主账号下并行实验请按照以下指导进行实验。并行实验中还需要注意区分您与其他IAM账号的资源名称。
创建存储桶
1,登录至AWS控制台,选择您实验所在的区域,如宁夏.随后点击服务,输入S3,这将导航至S3控制台页面。
2,点击创建存储桶,输入您自定义的桶名称,例如354790194606-partner-workshop-user2。建议您使用账户ID-partner-workshop-您的名字这样的格式创建存储桶,以避免名称冲突的资源区分。
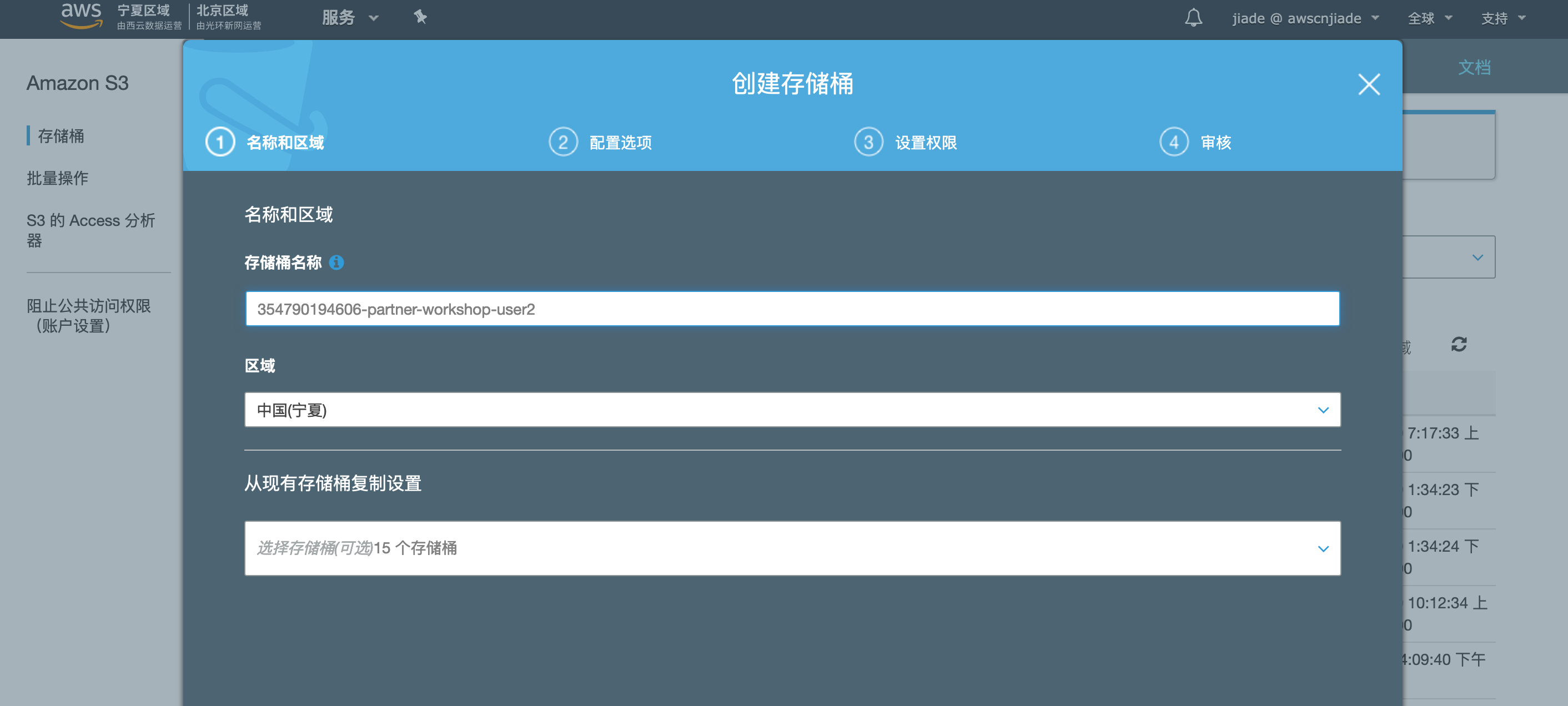
3,点击创建,确认存储桶创建完成。
创建角色
1,登录至AWS控制台,选择您实验所在的区域,如宁夏.随后点击服务,输入IAM,这将导航至IAM控制台页面。
2,点击角色,点击创建角色,这将导航至角色创建页面。
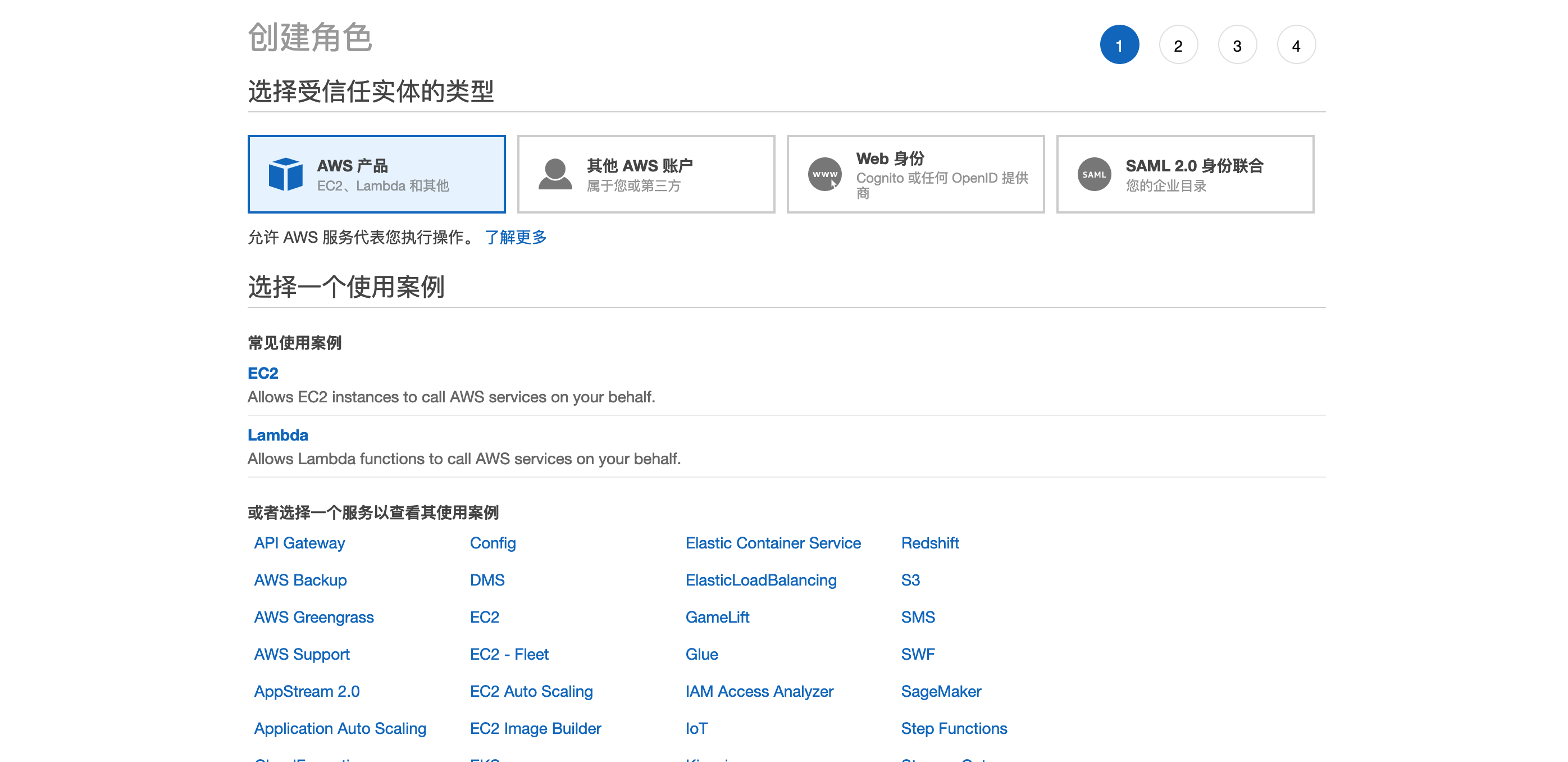
3,点击DMS,点击下一步,我们将创建DMS的角色。
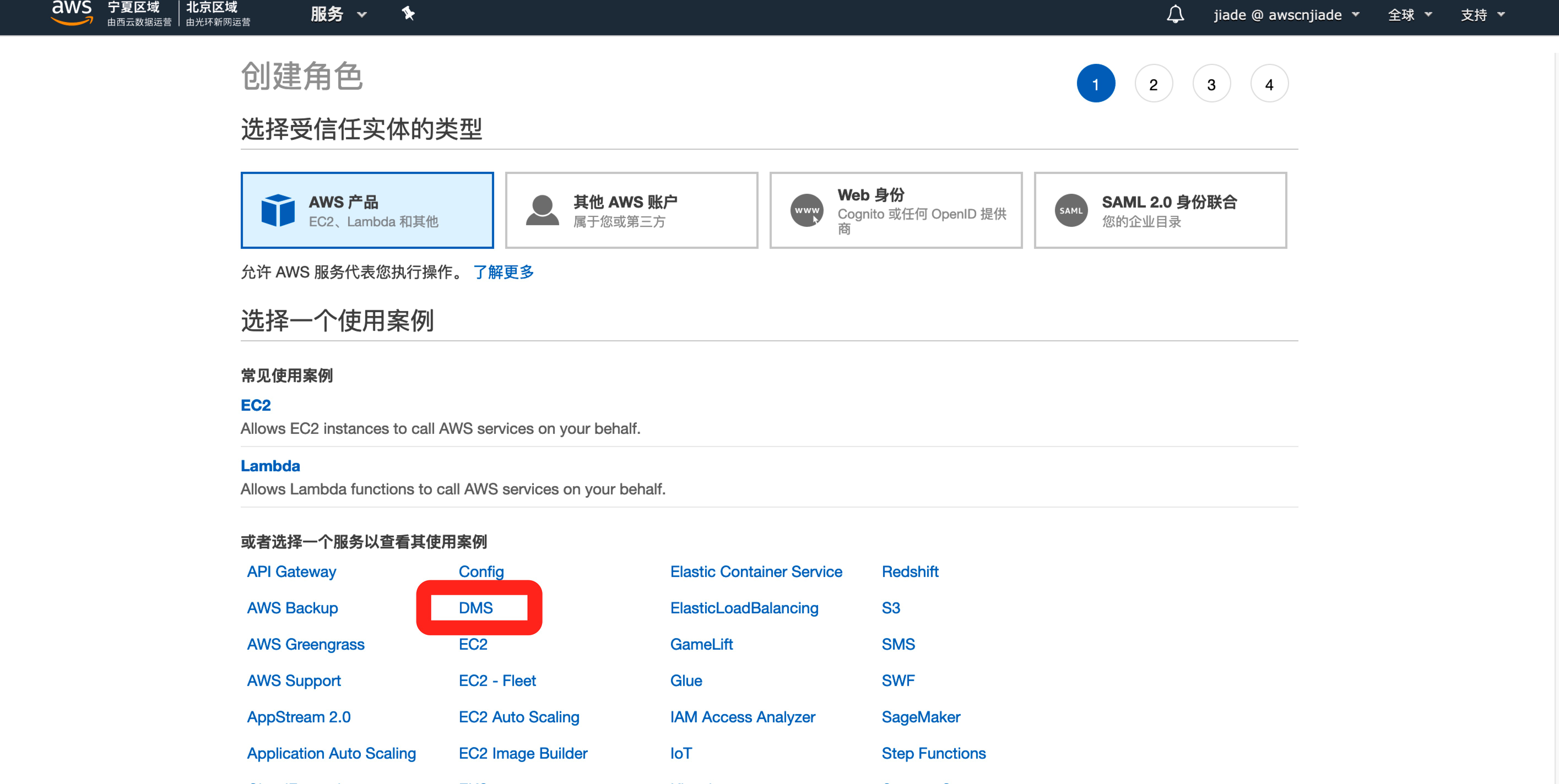
4,在筛选权限输入框,请输入AmazonS3FullAccess,然后打上勾,这样我们创建的角色将拥有读写S3存储的权限。
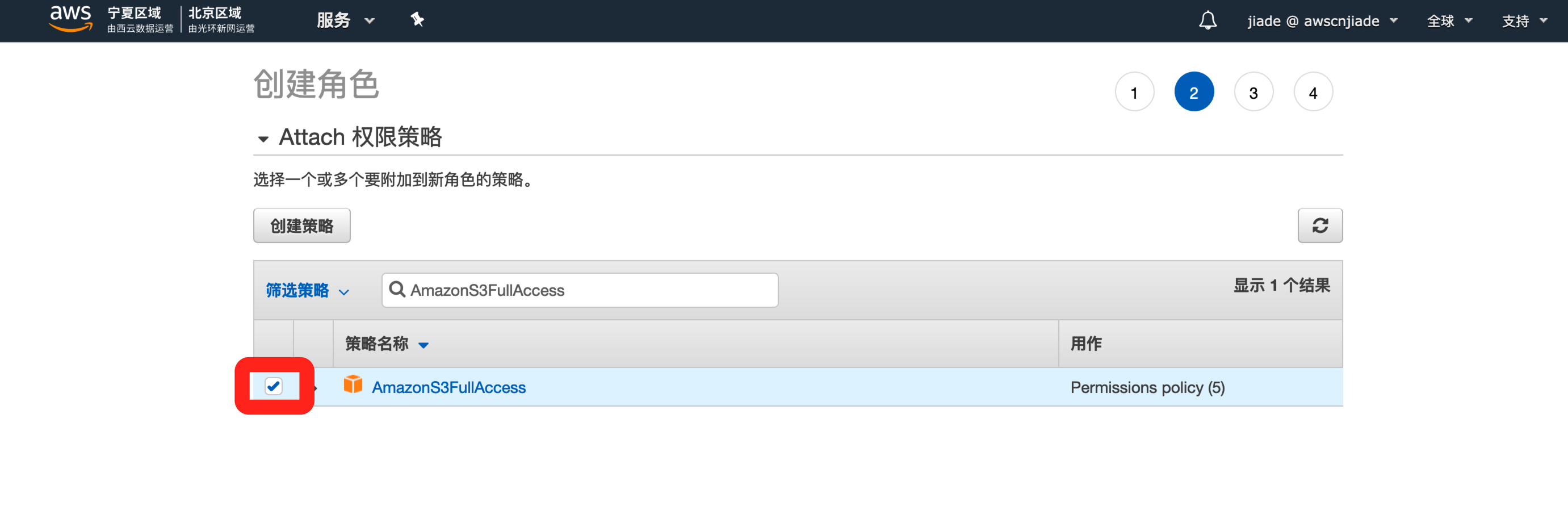 在我们的实验中,DMS除了需要S3读写权限外,还需要DynamoDB、DMSVPC、Cloudwatch的权限。我们依次在筛选权限输入框输入以下权限并勾选它。
在我们的实验中,DMS除了需要S3读写权限外,还需要DynamoDB、DMSVPC、Cloudwatch的权限。我们依次在筛选权限输入框输入以下权限并勾选它。AmazonDynamoDBFullAccess、AmazonDMSVPCManagementRole、AmazonDMSCloudWatchLogsRole,完成后点击下一步,可选输入标签,再点击下一步,来到审核页面。
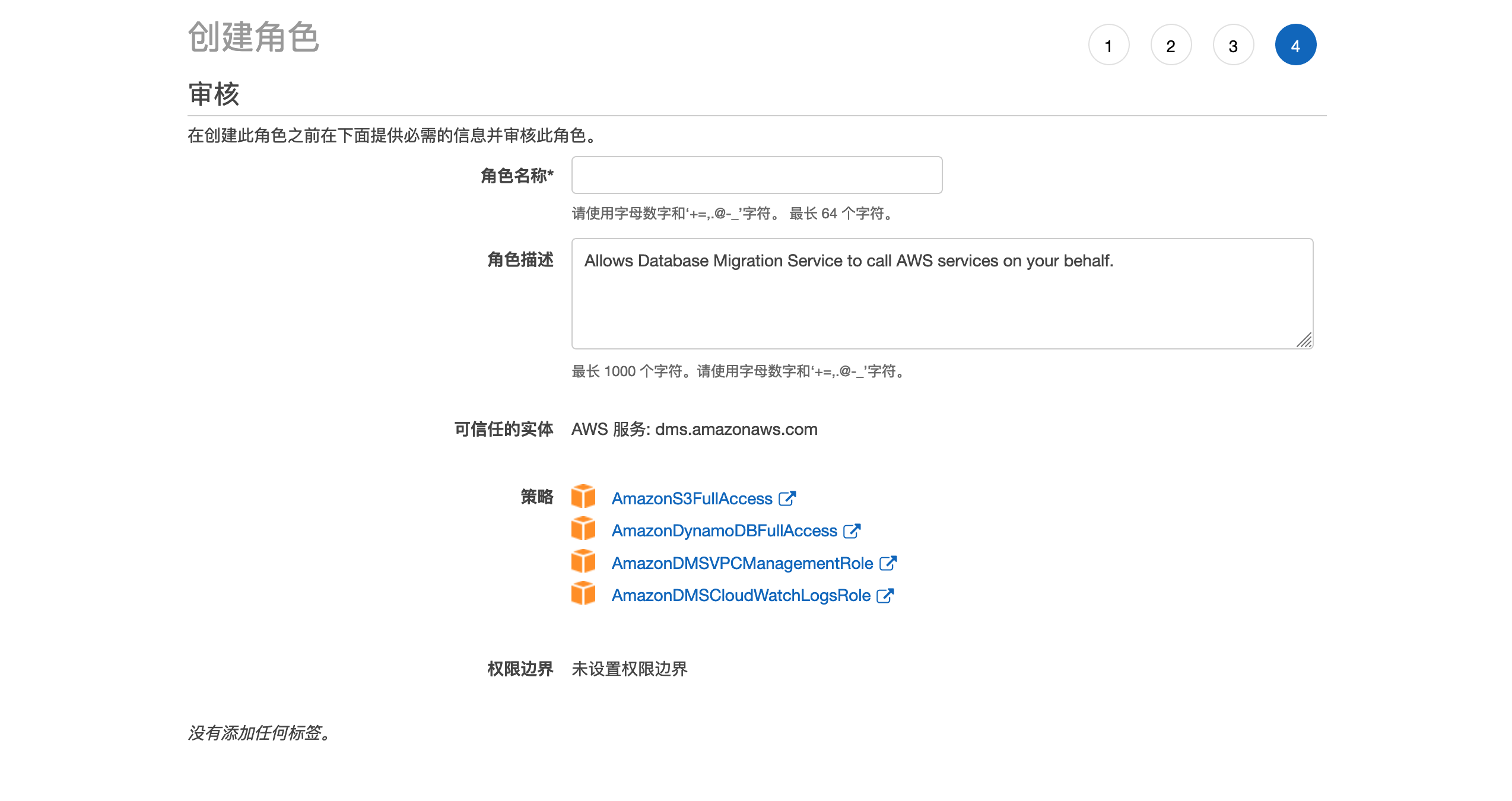
5,检查您的角色是否已经选择了以上4个策略,并在角色名称中输入dms-vpc-role,点击确认以创建角色。
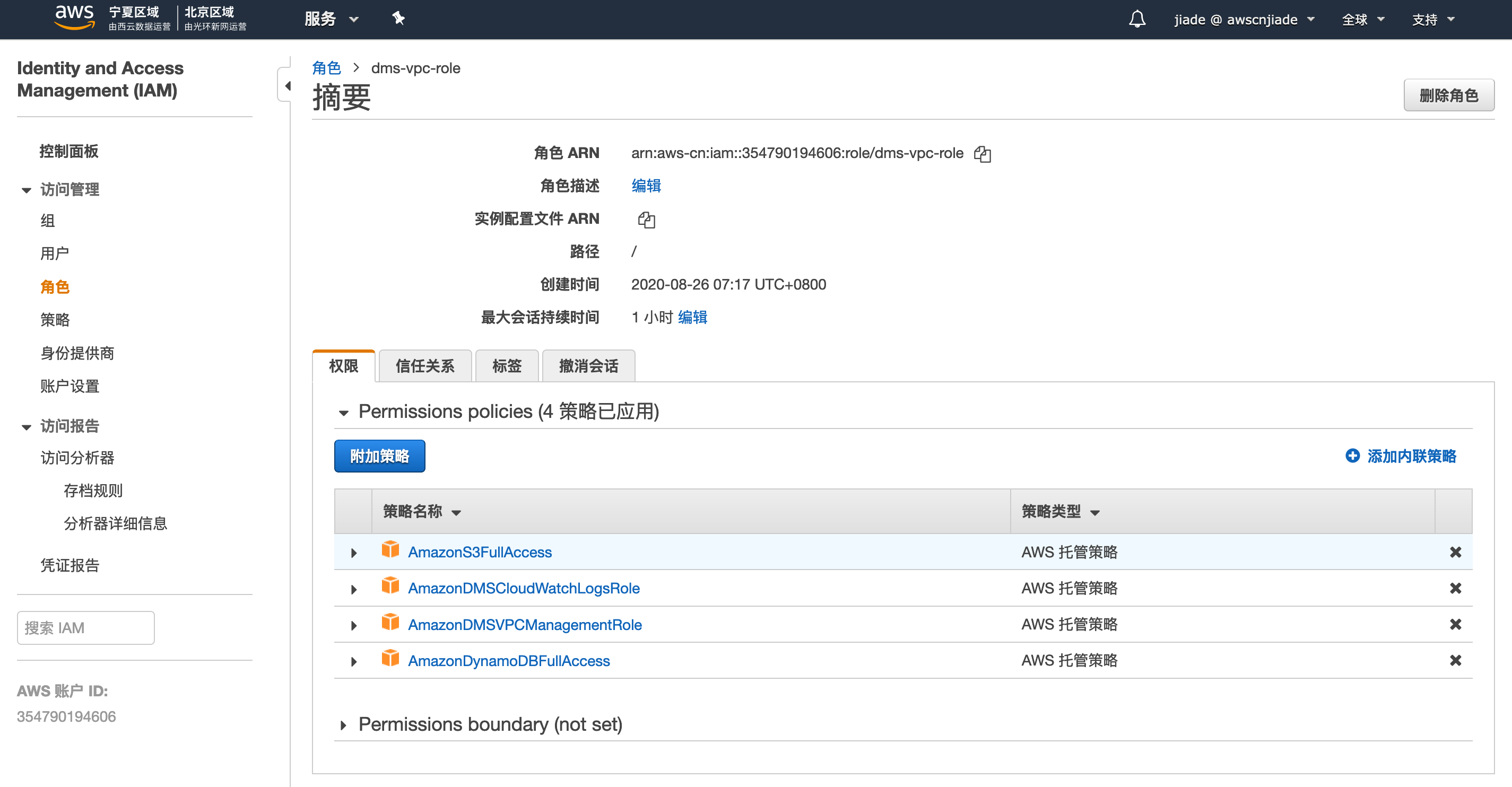
如果出现提示您角色已经存在,您可以回到角色页面查询该角色是否具备应有的权限。
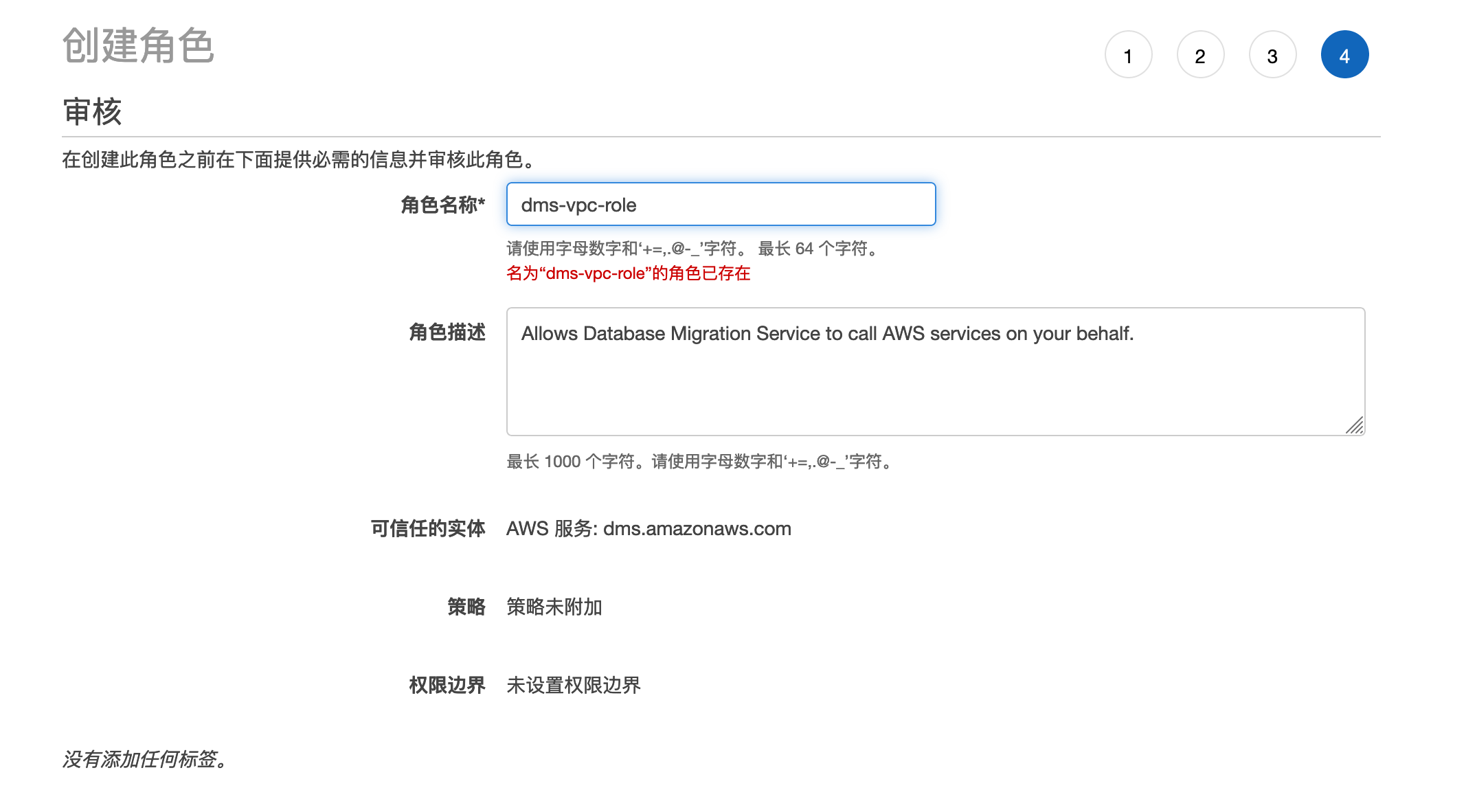
6,继续创建角色lambda-kinesis-role:服务选择Lambda,勾选AWSLambdaKinesisExecutionRole、AmazonKinesisFullAccess、AmazonS3FullAccess三个权限。角色命名为lambda-kinesis-role
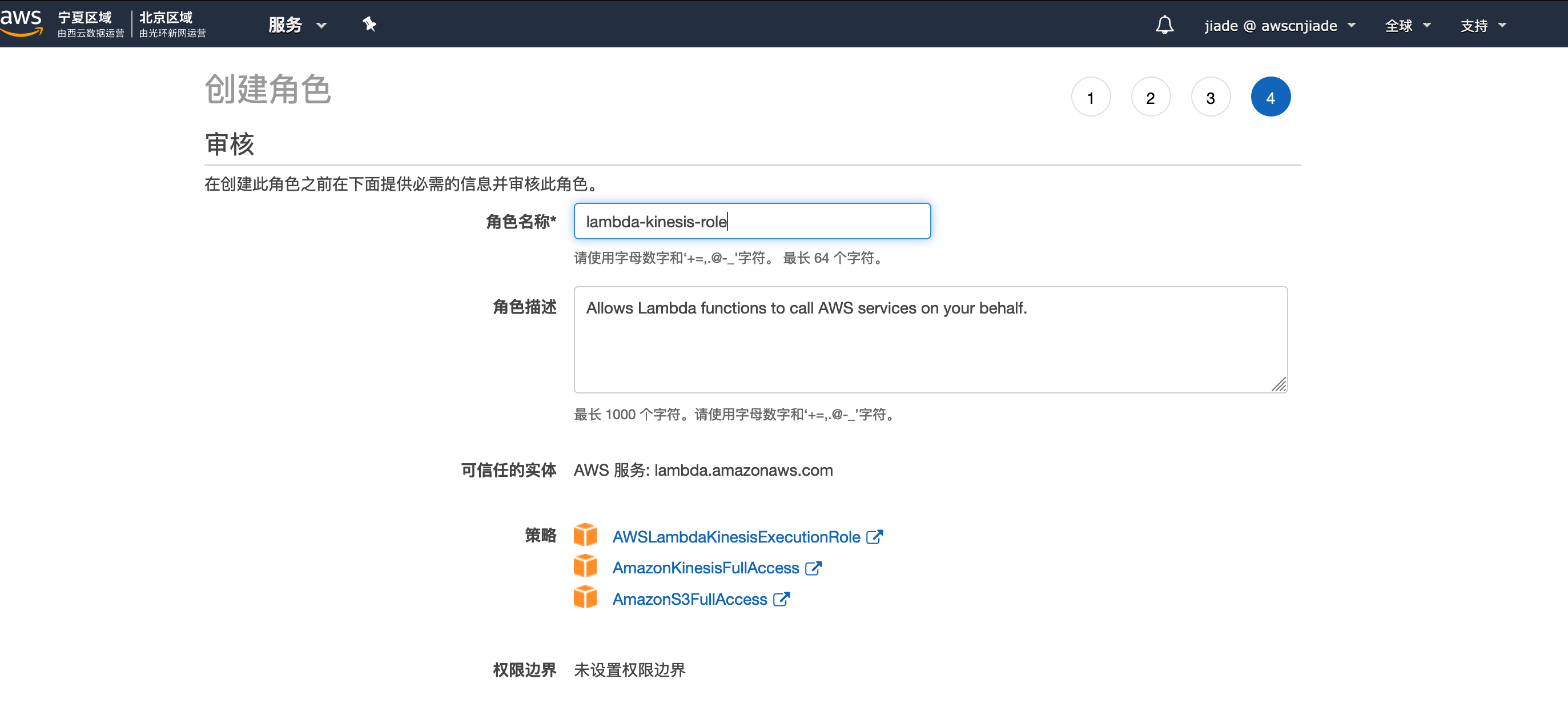
7,继续创建角色glue-service-role,服务选择Glue,勾选AWSLambdaKinesisExecutionRole、AWSGlueServiceNotebookRole、AmazonDynamoDBFullAccess、AWSGlueServiceRole、AmazonS3FullAccess五个权限。角色命名为glue-service-role
创建VPC
| 您可以使用Cloudformation创建,也可以手动创建。Cloudformation模板如下: | |
|---|---|
| 中国区域账户 | |
| 海外区域账户 | |
请注意在EnvironmentName输入您自定义的VPC名称,例如dms-vpc-user2。建议您使用dms-vpc-您的名字这样的格式创建VPC,以避免名称冲突的资源区分。
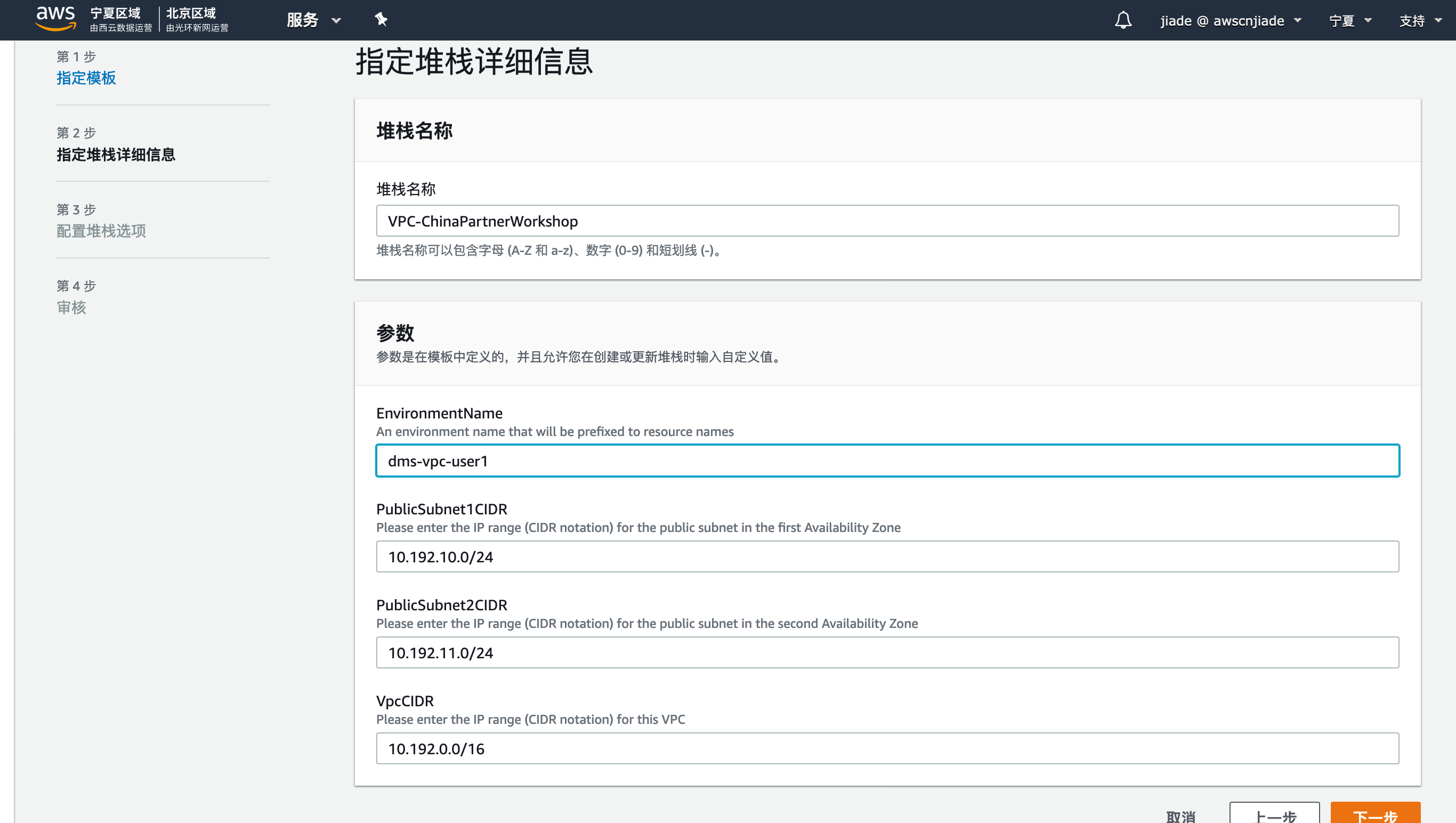
手动创建VPC
1,登录至AWS控制台,选择您实验所在的区域,如宁夏.随后点击服务,输入VPC,这将导航至VPC控制台页面。
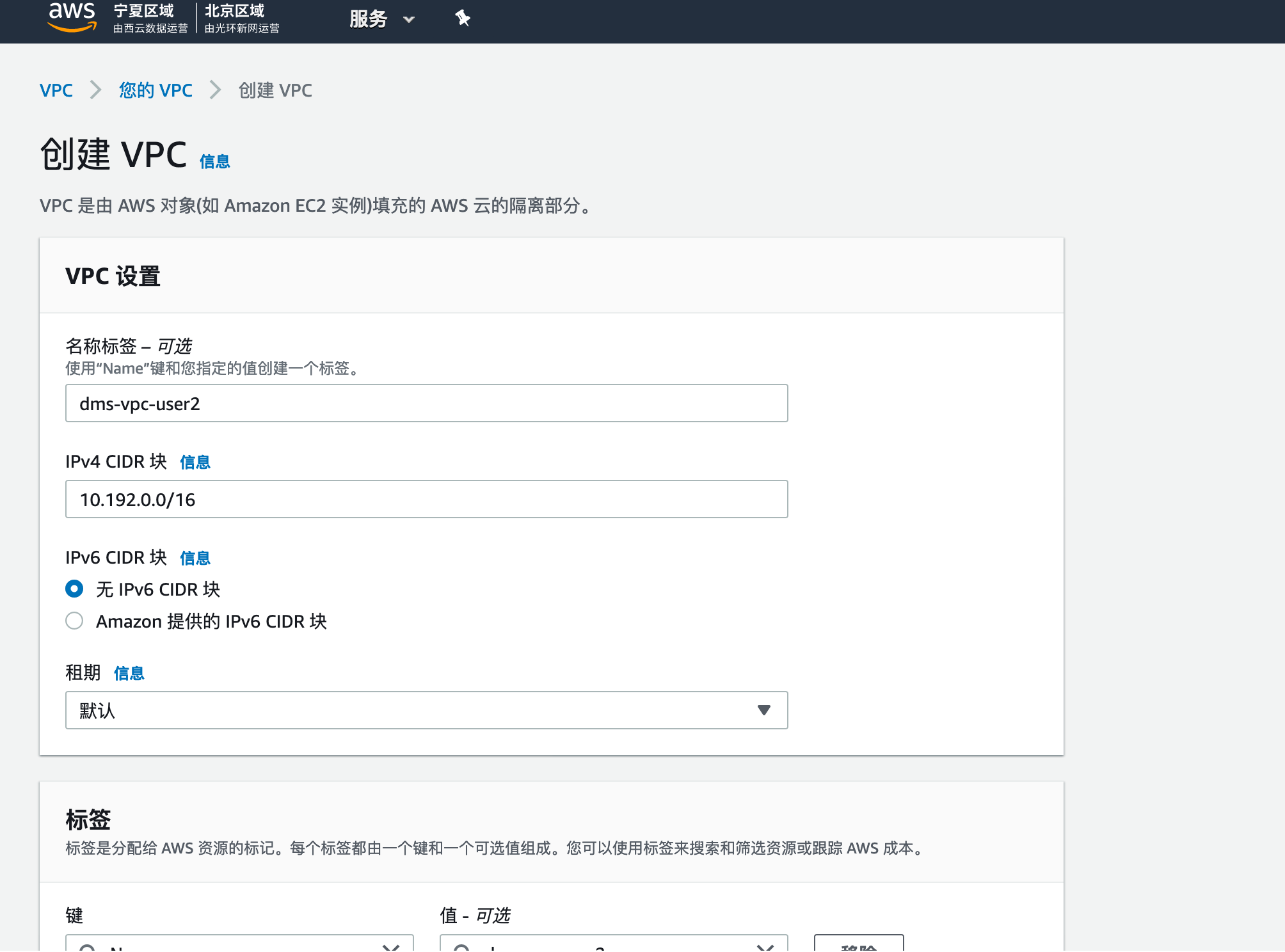
2,点击您的VPC,点击创建VPC,在创建页面,填入以下信息:
- VPC 名称: 输入您自定义的桶名称,例如
dms-vpc-user2。建议您使用dms-vpc-您的名字这样的格式创建VPC,以避免名称冲突的资源区分。 - IPv4 CIDR 块:
10.192.0.0/16 - 点击创建
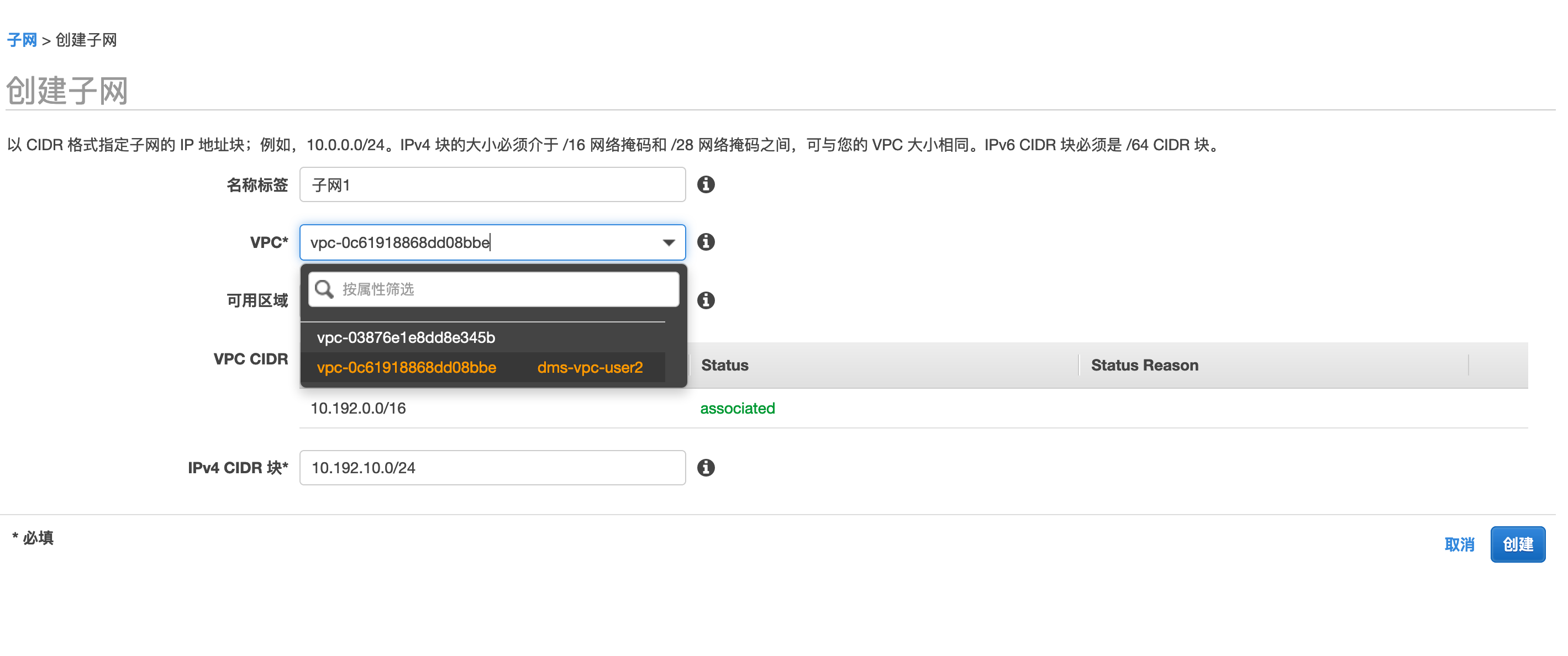
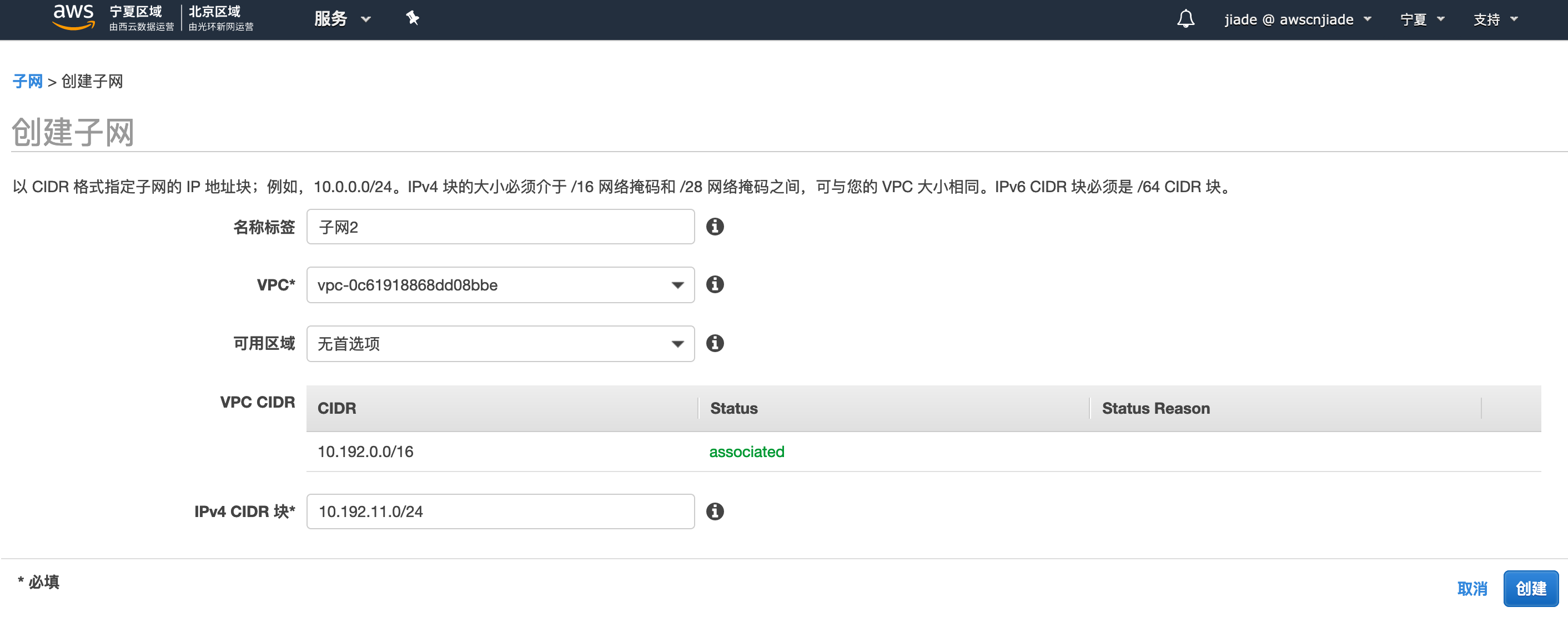
3,点击子网,点击创建子网,在创建页面,填入以下信息:
- 名称标签: 输入您自定义的桶名称,例如
子网1。 - VPC: 选择您刚刚创建的实验VPC例如
dms-vpc-user2 - IPv4 CIDR 块:
10.192.10.0/24 - 可用区域 : 指定任意一个可用区,如
cn-northwest-1a - 点击创建
同样的方法我们在创建一个子网2,点击子网,点击创建子网,在创建页面,填入以下信息:
- 名称标签: 输入您自定义的桶名称,例如
子网2。 - VPC: 选择您刚刚创建的实验VPC例如
dms-vpc-user2 - IPv4 CIDR 块:
10.192.11.0/24 - 可用区域 : 指定有别于上一子网任意可用区,如
cn-northwest-1b - 点击创建
4,创建互联网关,将互联网关附加到您创建的VPC:
- 导航至VPC控制台左侧的
互联网网关,点击创建互联网网关,可选输入名称和标签,点击创建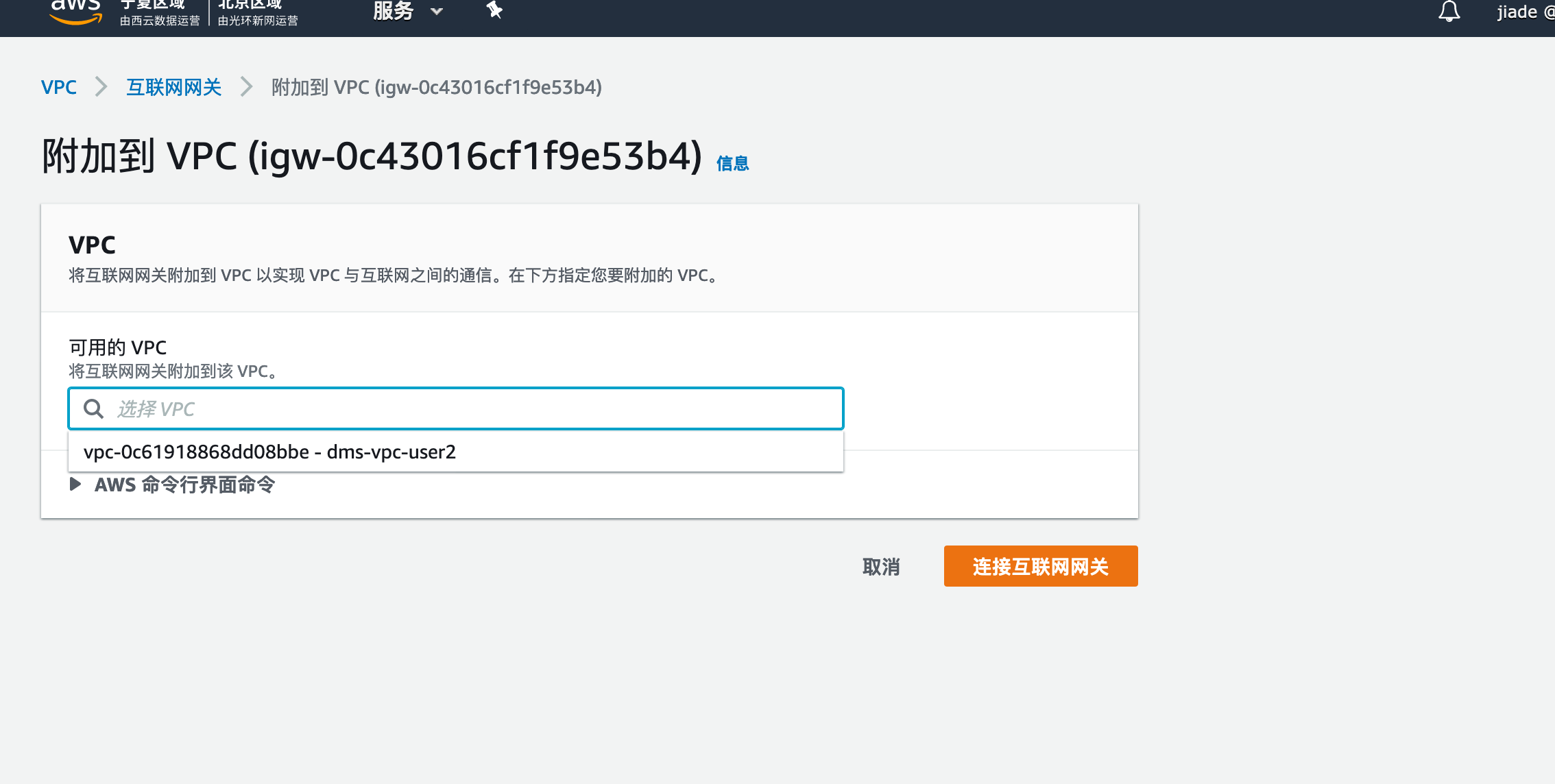
- 勾选您创建的网关,点击操作,选择
附加到VPC,选择您刚刚创建的VPC,点击连接互联网网关。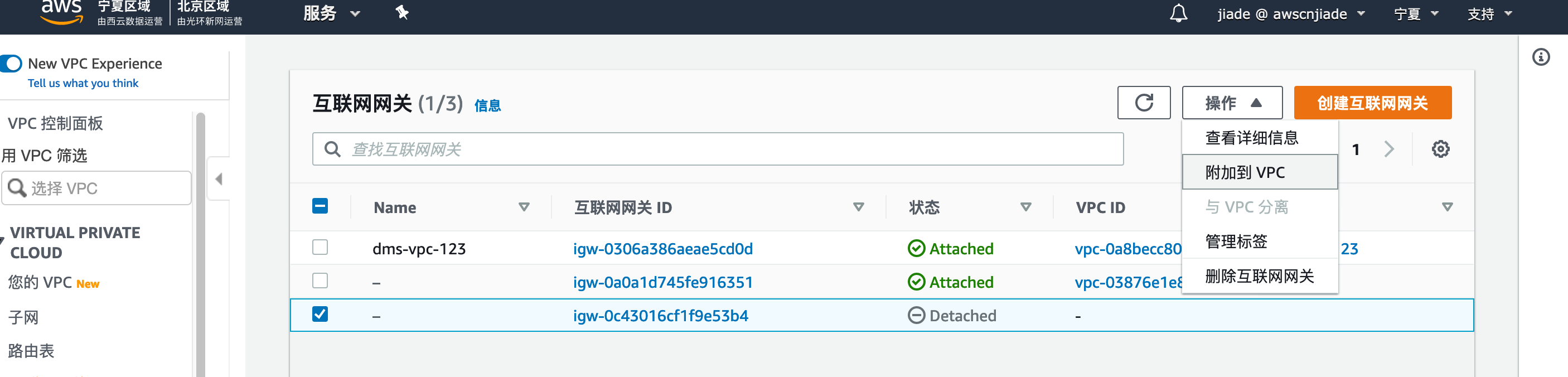
创建DMS任务
1,登录至AWS控制台,选择您实验所在的区域,如宁夏.随后点击服务,输入DMS,这将导航至DMS控制台页面。

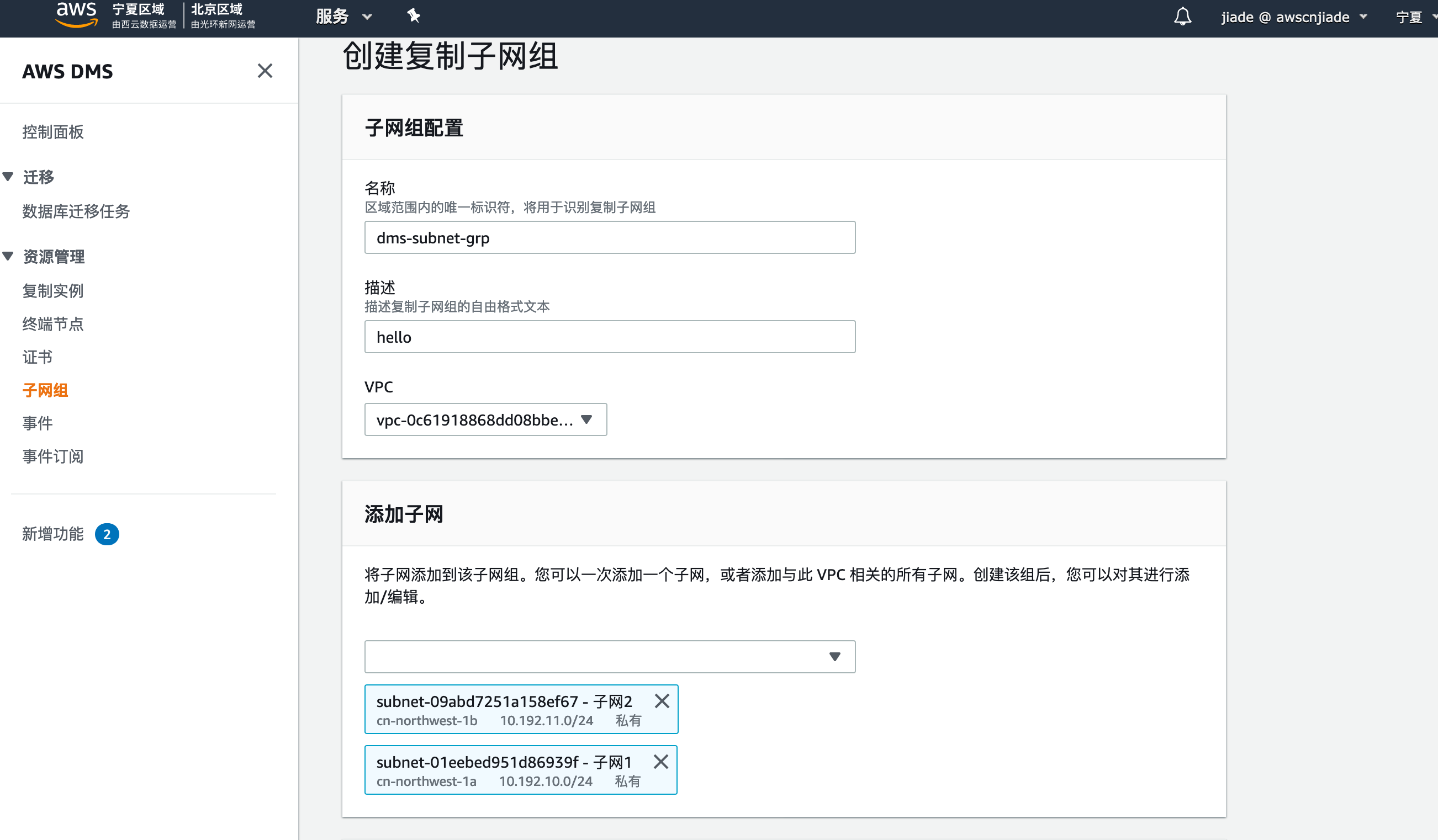
2,创建DMS子网组,点击子网组,点击创建子网组,在创建页面,填入以下信息:
- 名称标签: 输入您自定义的桶名称,例如
dms-subnet-grp - 描述:任意自定义字符
- VPC: 选择您刚刚创建的实验VPC例如
dms-vpc-user2 - 添加子网: 选择您在VPC内创建的两个子网,如
subnet-01eebed951d86939f - 子网1/subnet-09abd7251a158ef67 - 子网2 - 点击创建
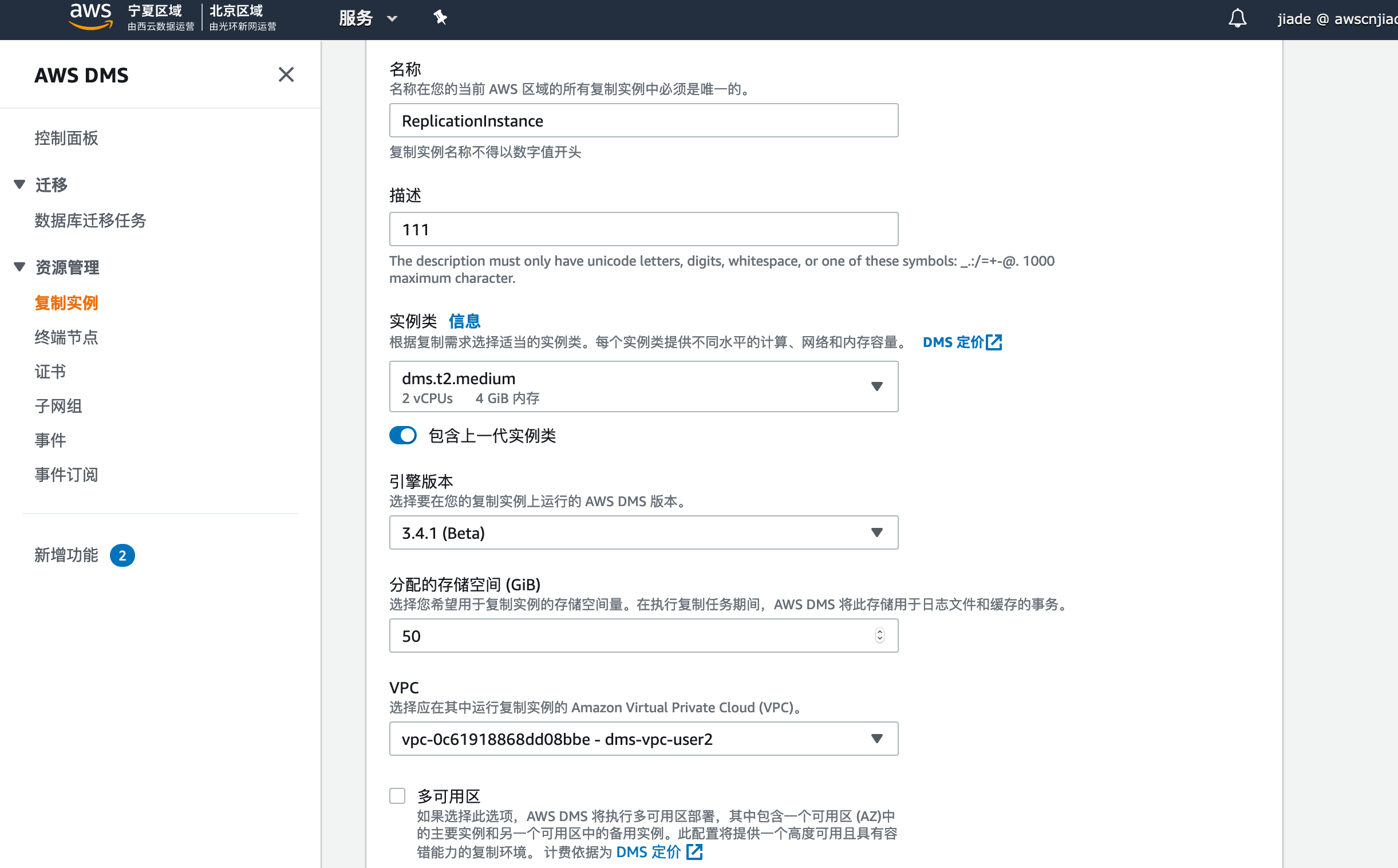
3,创建DMS复制实例,点击复制实例,点击创建复制实例,在创建页面,填入以下信息:
- 名称标签: 输入您自定义的名称,例如
ReplicationInstance - 描述:任意自定义字符
- 实例类:现在合适的实例类型,实验中选择较小的类型即可,例如:
dms.t2.medium - VPC: 选择您刚刚创建的实验VPC例如
dms-vpc-user2 - 其他项均可保持默认
- 点击创建
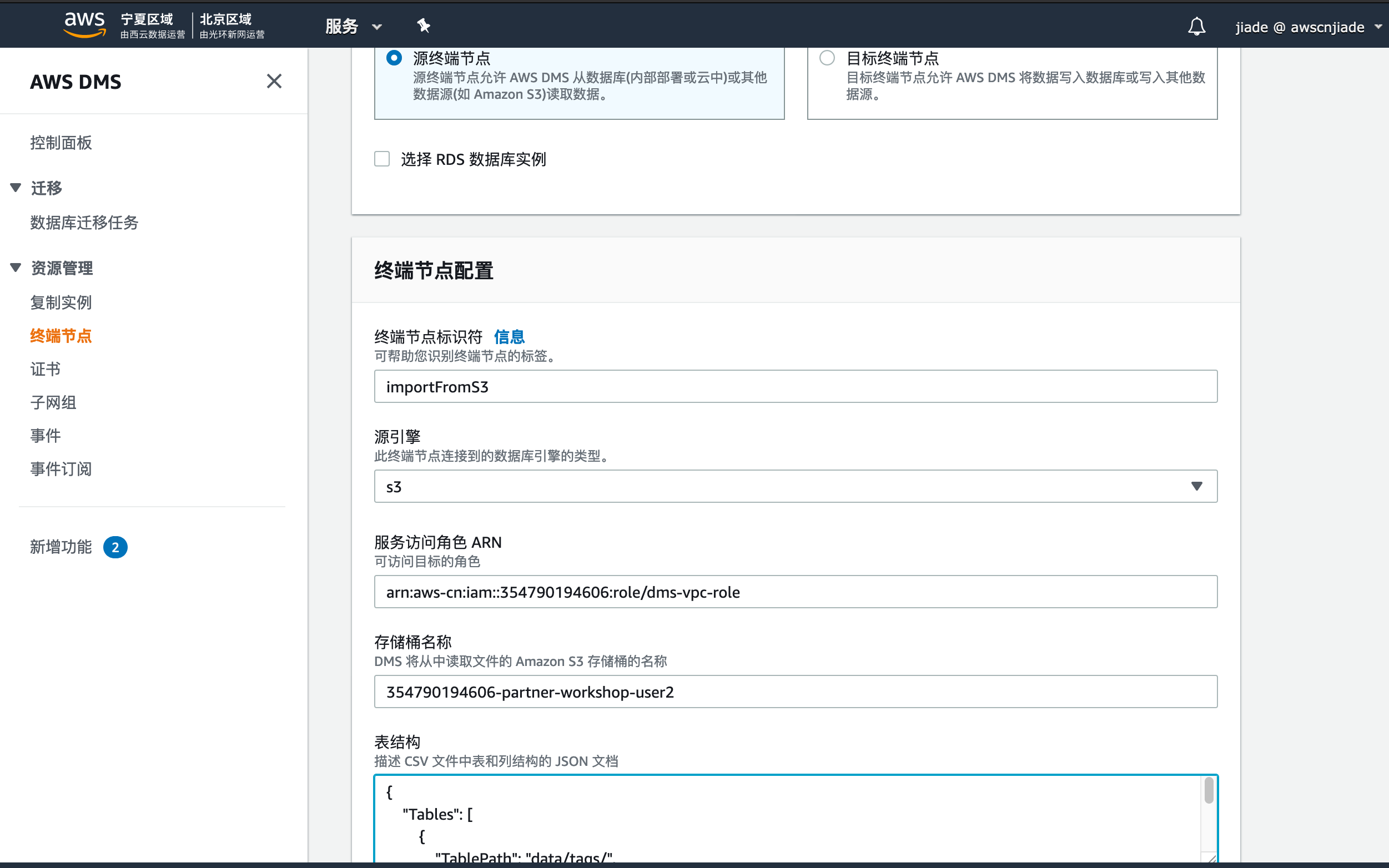
4,创建终端节点,点击终端节点,点击创建终端节点,在创建页面,填入以下信息:
- 终端节点类型:选择
源终端节点,稍后也将创建目标终端节点。(我们的实验将使用DMS将S3数据导至DynamoDB) - 终端节点标识符: 输入您自定义的名称,例如
importFromS3 - 源引擎:选择
S3 - 服务访问角色 ARN:导航至IAM页面,查看您刚刚创建的dms-vpc-role的ARN信息,例如:
arn:aws-cn:iam::354790194606:role/dms-vpc-role(如果你的实验账户是全球区域账户,ARN应为arn:aws:iam::xxxx:role/dms-vpc-role) - 存储桶名称: 选择您刚刚创建的实验S3桶例如
354790194606-partner-workshop-user2 - 表结构,复制粘贴以下信息:
{
"Tables": [
{
"TablePath": "data/tags/",
"TableColumnsTotal": "4",
"TableOwner": "data",
"TableName": "tags",
"TableColumns": [
{
"ColumnName": "userId",
"ColumnIsPk": "true",
"ColumnNullable": "false",
"ColumnType": "STRING",
"ColumnLength": "20"
},
{
"ColumnName": "movieId",
"ColumnNullable": "false",
"ColumnType": "STRING",
"ColumnLength": "20"
},
{
"ColumnName": "tag",
"ColumnType": "STRING",
"ColumnLength": "255"
},
{
"ColumnName": "timestamp",
"ColumnType": "STRING",
"ColumnLength": "20"
}
]
},
{
"TablePath": "data/ratings/",
"TableColumnsTotal": "4",
"TableOwner": "data",
"TableName": "ratings",
"TableColumns": [
{
"ColumnName": "userId",
"ColumnIsPk": "true",
"ColumnNullable": "false",
"ColumnType": "STRING",
"ColumnLength": "20"
},
{
"ColumnName": "movieId",
"ColumnNullable": "false",
"ColumnType": "STRING",
"ColumnLength": "20"
},
{
"ColumnName": "rating",
"ColumnType": "STRING",
"ColumnLength": "5"
},
{
"ColumnName": "timestamp",
"ColumnType": "STRING",
"ColumnLength": "20"
}
]
},
{
"TablePath": "data/links/",
"TableColumnsTotal": "3",
"TableOwner": "data",
"TableName": "links",
"TableColumns": [
{
"ColumnName": "movieId",
"ColumnIsPk": "true",
"ColumnNullable": "false",
"ColumnType": "STRING",
"ColumnLength": "20"
},
{
"ColumnName": "imdbId",
"ColumnType": "STRING",
"ColumnLength": "20"
},
{
"ColumnName": "tmdbId",
"ColumnType": "STRING",
"ColumnLength": "20"
}
]
},
{
"TablePath": "data/movies/",
"TableColumnsTotal": "3",
"TableOwner": "data",
"TableName": "movies",
"TableColumns": [
{
"ColumnName": "movieId",
"ColumnIsPk": "true",
"ColumnNullable": "false",
"ColumnType": "STRING",
"ColumnLength": "20"
},
{
"ColumnName": "title",
"ColumnType": "STRING",
"ColumnLength": "255"
},
{
"ColumnName": "genres",
"ColumnType": "STRING",
"ColumnLength": "255"
}
]
}
],
"TableCount": "4"
}
- 其他项均可保持默认
- 点击创建
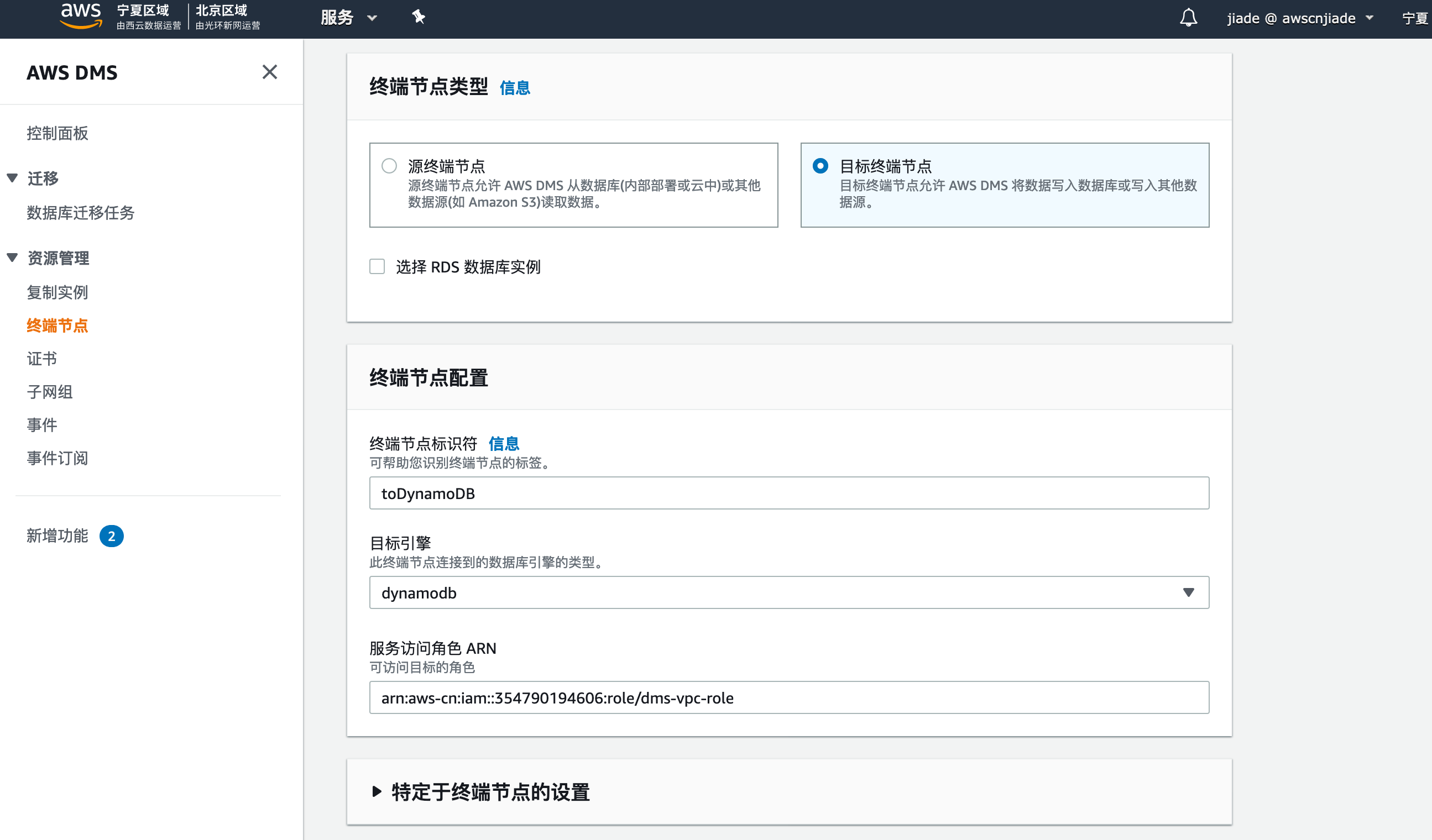
类似的操作,我们再创建目标终端节点。
点击终端节点,点击创建终端节点,在创建页面,填入以下信息:
- 终端节点类型:选择
目标终端节点,稍后也将创建目标终端节点。(我们的实验将使用DMS将S3数据导至DynamoDB) - 终端节点标识符: 输入您自定义的名称,例如
toDynamoDB - 源引擎:选择
dynamodb - 服务访问角色 ARN:导航至IAM页面,查看您刚刚创建的dms-vpc-role的ARN信息,例如:
arn:aws-cn:iam::354790194606:role/dms-vpc-role - 其他保持默认即可
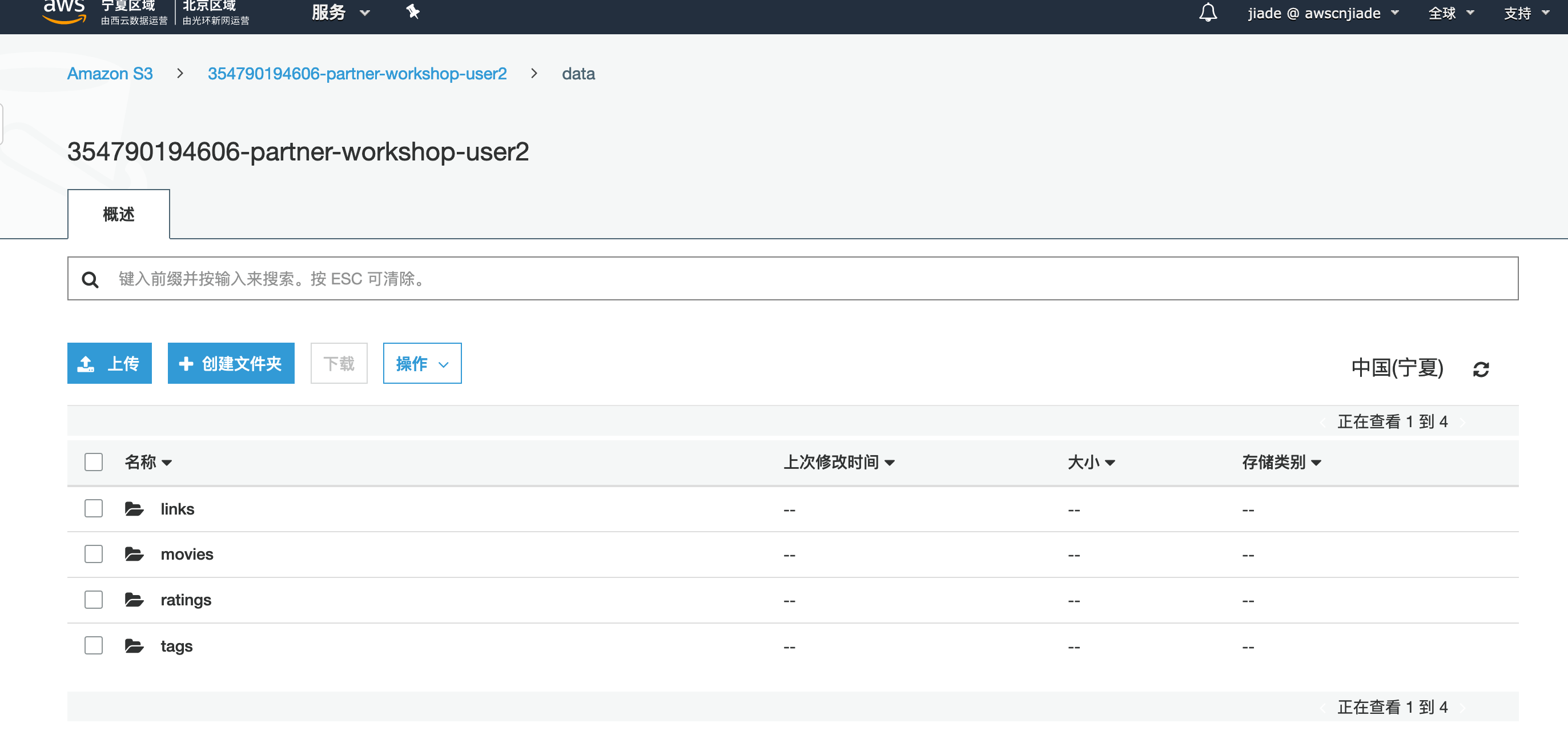
5,上传数据至S3 在使用Cloudformation进行的实验中,我们使用了Lambda上传数据并将它们上传到指定的存储桶,在手动环节中我们可以通过控制台直接上传以简化实验步骤。 点击下载下列压缩包,并解压至您的本地存储 https://awspsa-quickstart.s3.cn-northwest-1.amazonaws.com.cn/bigdata/data/data.zip
- 导航进行S3控制台页面,点击您创建的存储桶,例如
354790194606-partner-workshop-user2 - 点击
上传,或是将文件拖动到浏览器窗口将刚刚下载并解压的data文件夹上传至您的桶根目录
6,导航进行DMS控制台页面,点击左侧数据库迁移任务,点击创建任务.在创建页面,填入以下信息:
- 任务标识符:输入您自定义的名称,例如
full-load - 复制实例: 选择您创建的复制示例(如果您是多个IAM用户共用一个AWS账号进行实验,可以选择同一个复制示例以节省成本)
- 源数据库终端节点:选择您创建的源字段节点名称,例如
importFromS3 - 目标数据库终端节点:选择您创建的源字段节点名称,例如
toDynamoDB - 迁移类型,选择:
迁移现有数据 - 下拉至
表映像栏位,点击JSON编辑器,复制填入以下内容:
{
"rules": [
{
"rule-type": "selection",
"rule-id": "1",
"rule-action": "include",
"object-locator": {
"schema-name": "data",
"table-name": "%"
},
"rule-name": "1"
},
{
"rule-action": "map-record-to-record",
"object-locator": {
"schema-name": "data",
"table-name": "tags"
},
"target-table-name": "tags_t",
"rule-name": "2",
"rule-type": "object-mapping",
"rule-id": "2",
"mapping-parameters": {
"attribute-mappings": [
{
"attribute-type": "scalar",
"attribute-sub-type": "string",
"target-attribute-name": "Id",
"value": "${userId}X${movieId}"
},
{
"attribute-type": "scalar",
"attribute-sub-type": "string",
"target-attribute-name": "userId",
"value": "${userId}"
},
{
"attribute-type": "scalar",
"attribute-sub-type": "string",
"target-attribute-name": "movieId",
"value": "${movieId}"
},
{
"attribute-type": "scalar",
"attribute-sub-type": "string",
"target-attribute-name": "tags",
"value": "${tags}"
},
{
"attribute-type": "scalar",
"attribute-sub-type": "string",
"target-attribute-name": "timestamp_c",
"value": "${timestamp}"
}
],
"exclude-columns": [
"userId",
"movieId",
"tags",
"timestamp"
],
"partition-key-name": "Id",
"sort-key-name": "movieId"
}
},
{
"rule-action": "map-record-to-record",
"object-locator": {
"schema-name": "data",
"table-name": "ratings"
},
"target-table-name": "ratings_t",
"rule-name": "3",
"rule-type": "object-mapping",
"rule-id": "3",
"mapping-parameters": {
"attribute-mappings": [
{
"attribute-type": "scalar",
"attribute-sub-type": "string",
"target-attribute-name": "Id",
"value": "${userId}X${movieId}"
},
{
"attribute-type": "scalar",
"attribute-sub-type": "string",
"target-attribute-name": "userId",
"value": "${userId}"
},
{
"attribute-type": "scalar",
"attribute-sub-type": "string",
"target-attribute-name": "movieId",
"value": "${movieId}"
},
{
"attribute-type": "scalar",
"attribute-sub-type": "string",
"target-attribute-name": "rating",
"value": "${rating}"
},
{
"attribute-type": "scalar",
"attribute-sub-type": "string",
"target-attribute-name": "timestamp_c",
"value": "${timestamp}"
}
],
"exclude-columns": [
"userId",
"movieId",
"rating",
"timestamp"
],
"partition-key-name": "Id",
"sort-key-name": "movieId"
}
},
{
"rule-action": "map-record-to-record",
"object-locator": {
"schema-name": "data",
"table-name": "movies"
},
"target-table-name": "movies_t",
"rule-name": "4",
"rule-type": "object-mapping",
"rule-id": "4",
"mapping-parameters": {
"attribute-mappings": [
{
"attribute-type": "scalar",
"attribute-sub-type": "string",
"target-attribute-name": "movieId",
"value": "${movieId}"
},
{
"attribute-type": "scalar",
"attribute-sub-type": "string",
"target-attribute-name": "title",
"value": "${title}"
},
{
"attribute-type": "scalar",
"attribute-sub-type": "string",
"target-attribute-name": "genres",
"value": "${genres}"
}
],
"exclude-columns": [
"movieId",
"title",
"genres"
],
"partition-key-name": "movieId",
"sort-key-name": "genres"
}
},
{
"rule-action": "map-record-to-record",
"object-locator": {
"schema-name": "data",
"table-name": "links"
},
"target-table-name": "links_t",
"rule-name": "5",
"rule-type": "object-mapping",
"rule-id": "5",
"mapping-parameters": {
"attribute-mappings": [
{
"attribute-type": "scalar",
"attribute-sub-type": "string",
"target-attribute-name": "movieId",
"value": "${movieId}"
},
{
"attribute-type": "scalar",
"attribute-sub-type": "string",
"target-attribute-name": "imdbId",
"value": "${imdbId}"
},
{
"attribute-type": "scalar",
"attribute-sub-type": "string",
"target-attribute-name": "tmdbId",
"value": "${tmdbId}"
}
],
"exclude-columns": [
"movieId",
"imdbId",
"tmdbId"
],
"partition-key-name": "movieId",
"sort-key-name": "imdbId"
}
}
]
}
- 其他项保持默认即可,点击创建
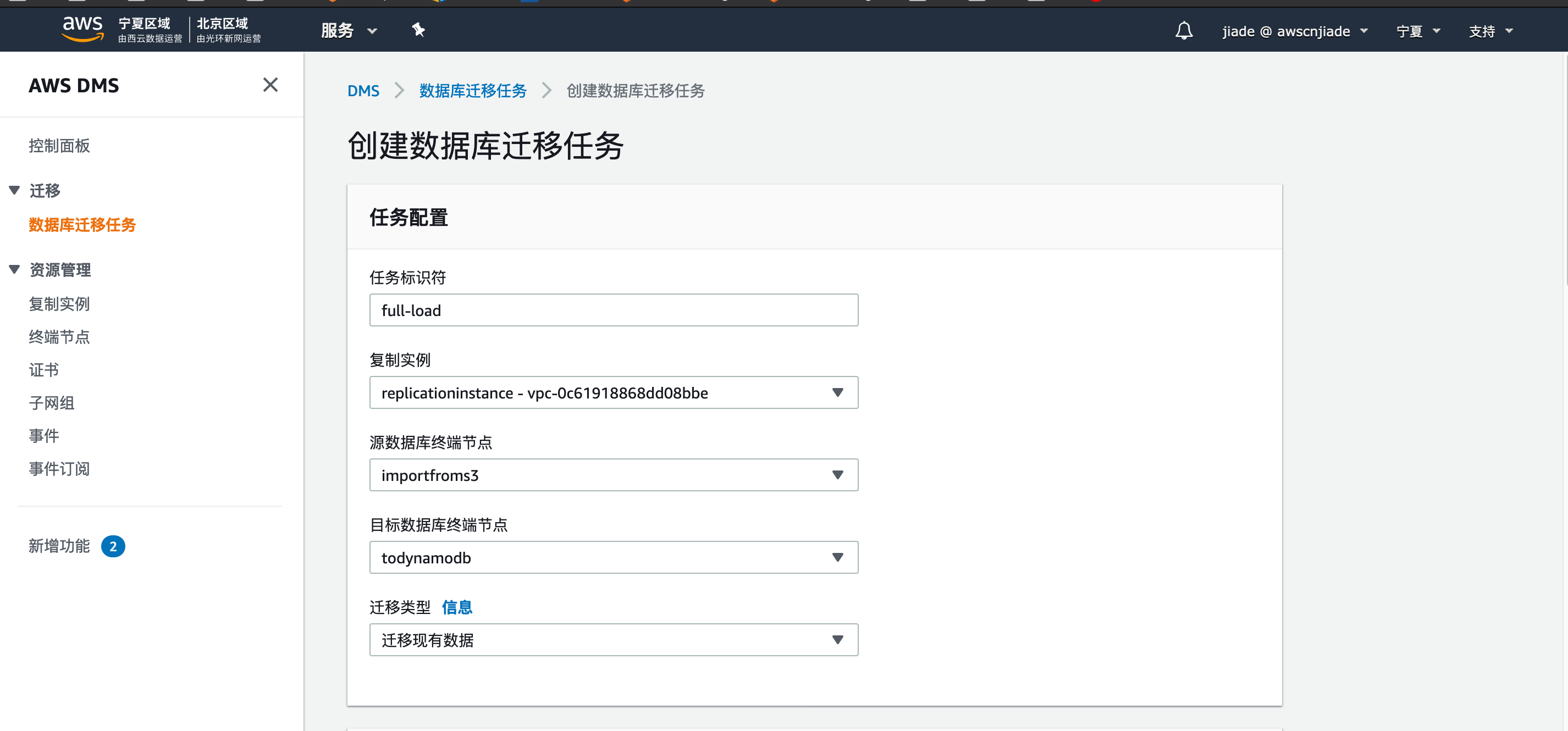
稍等2分钟左右,您创建的DMS任务将经历正在创建,正在启动,正在运行,加载完成几个阶段。你可以在进度50%之后及去查看您看DynamoDB表是否被DMS创建出来。
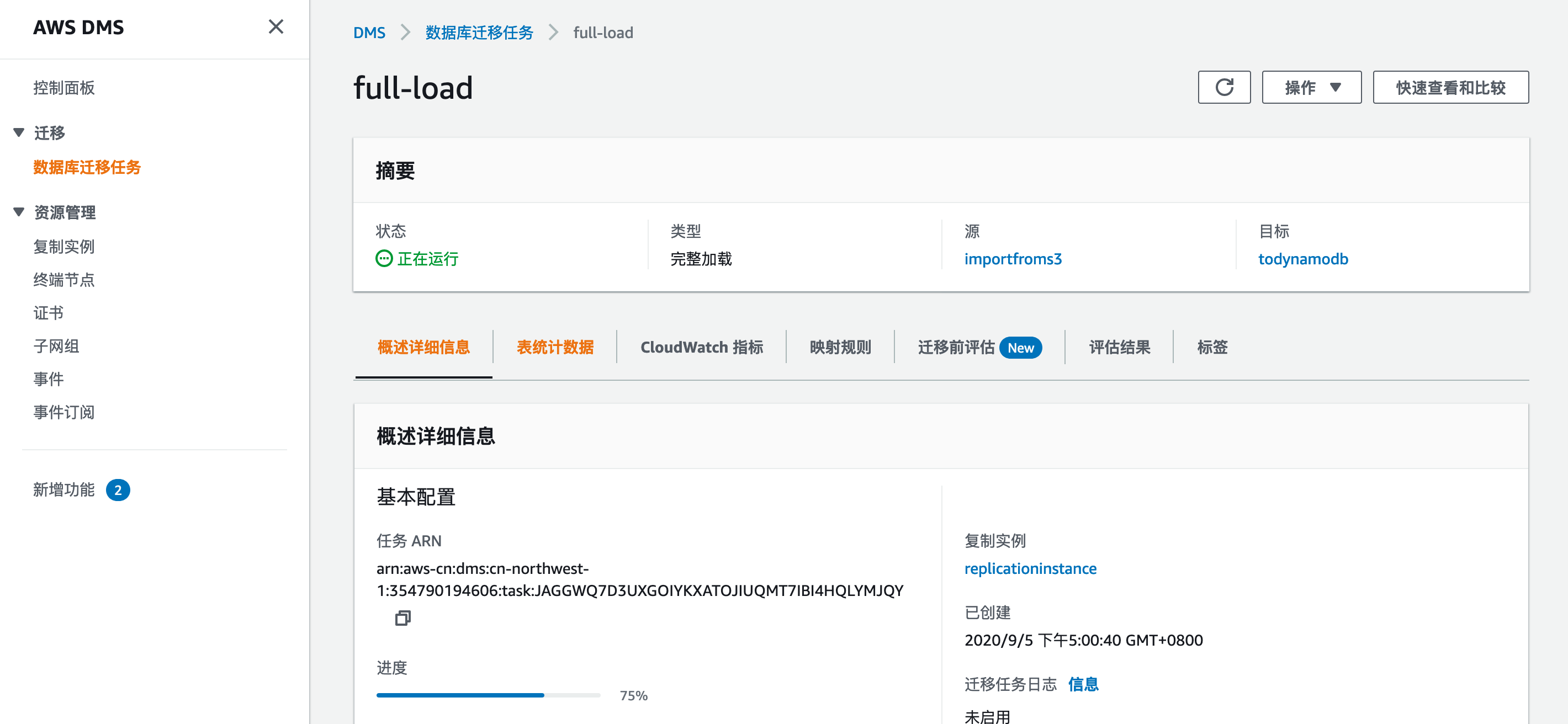
7,查看DynamoDB表
- 单击“服务”,搜索Dynamo,然后单击“ DynamoDb”。
- 点击“表格”。
- 确认已创建5个表。
- 单击浏览项目,awsdms_full_load_exceptions表中有0个项目,links_t、movies_t、rating_t、tags_t四张表均有丰富的数据。
恭喜你,您完成了模拟场景中数据批量导入的模拟实验,这家电影网站已经一批第三方数据下载至S3,并将这些第三方的csv格式的历史数据从S3导入至您的dynamodb表中。 您可以与小组成员或与您的导师讨论,DMS是否也可以用与流数据的摄取?