实验3: Glue catalog & Glue ETL
使用 AWS Glue 进行数据ETL
- 我们将使用Glue的
网爬程序和ETL jop对流式和批量加载到S3数据湖的数据进行ETL,在处理后的数据再保存到数据湖的另以位置。实验将形成处理后的数据和数据表结构,以便能提供给更高级别的深度学习和可视化报表使用。
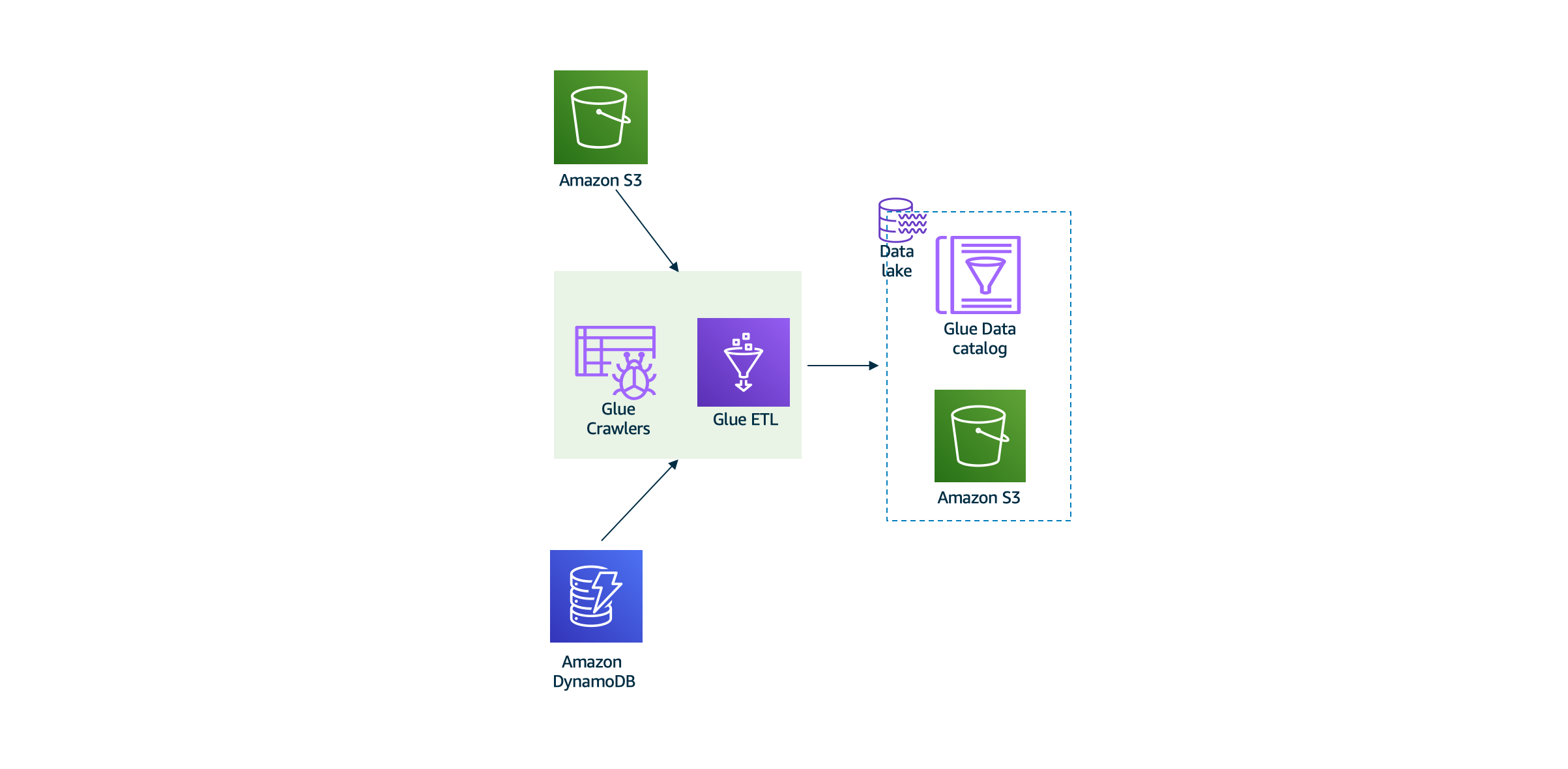
在实验2中,您使用Kinesis收集了实时收视率数据并将其存储到S3中。在本实验中,您将使用Glue数据目录在S3和DynamoDB中存储的数据上定义架构。您将对数据执行ETL,以准备将其用于机器学习和业务可视化分析。来自Glue的输出数据将在输入到Amazon Sagemaker笔记本和Athena中使用。
1.填充S3 Glue数据目录
1.AWS Glue数据目录(catalog)是数据路径,数据结构和数据分区的索引。它包含对数据的指引,这些数据用作AWS Glue中提取,转换和加载(ETL)作业的源和目标。数据目录是Apache Hive Meta-store的直接替代品,并提供了一个统一的存储库,不同的系统可以在其中存储和查找元数据以关联实际数据,并使用该元数据查询和转换数据。要获取数据目录,我们需要首先创建一个具有适当权限的角色,然后再创建一个爬网程序以读取S3存储桶和 DynamoDB 表中的数据。
2.登录到AWS管理控制台https://console.aws.amazon.com/。
3.在AWS管理控制台的右上角,确认您位于所需的AWS区域。
4.从所有服务列表中单击“Glue”。这将带您进入AWS Glue控制台页面。
5.单击左侧面板上的“爬网程序”,然后单击“添加爬网程序”
6.对于爬网程序名称名称,输入你自定义的名称,例如 catalog_kinesis。
7.单击下一步
8.对于数据存储,请确保已选择S3。浏览到在实验1中创建的存储桶(实验1中记录的存储桶)中的xxxxxx-Partner-works。单击选择,在点击到您自定义的firehose路径,如这里的firehose2022(如何您之前的firehose没有填写前缀,您的路径应该是年月日的年,如2022,这个路径是我们流式lambda通过管道产生的数据)。
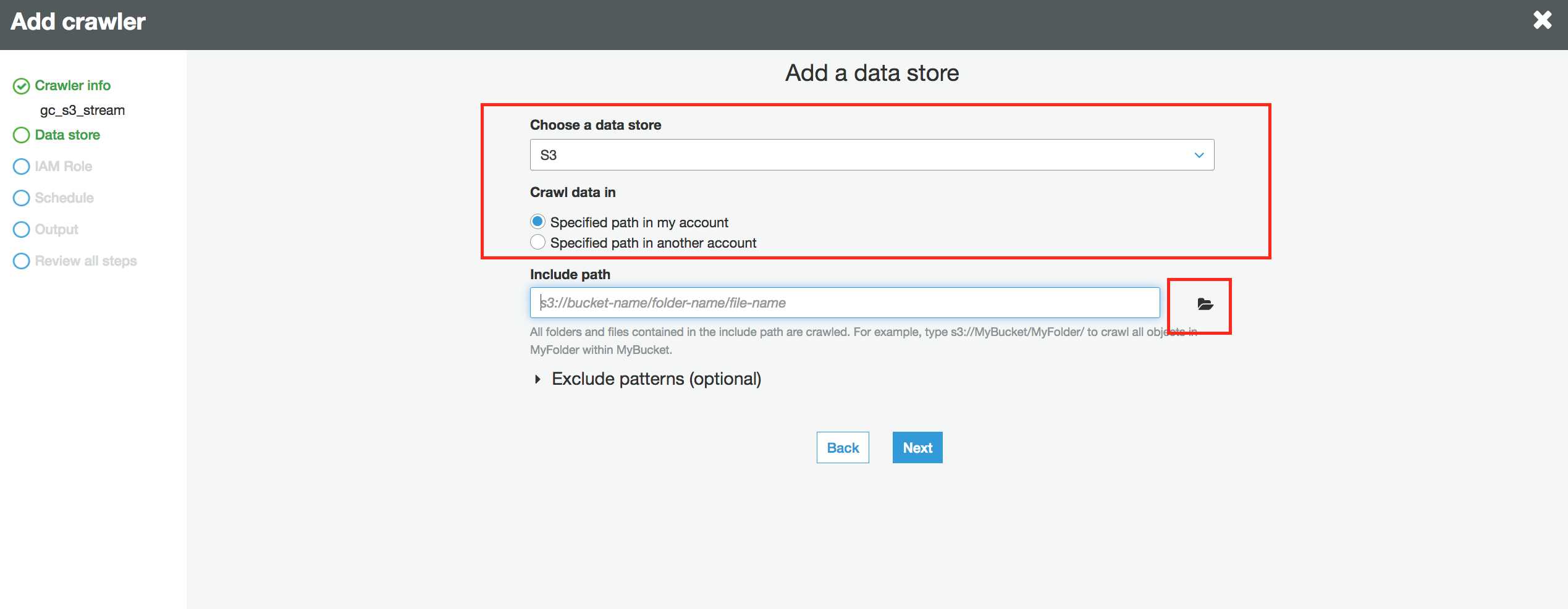
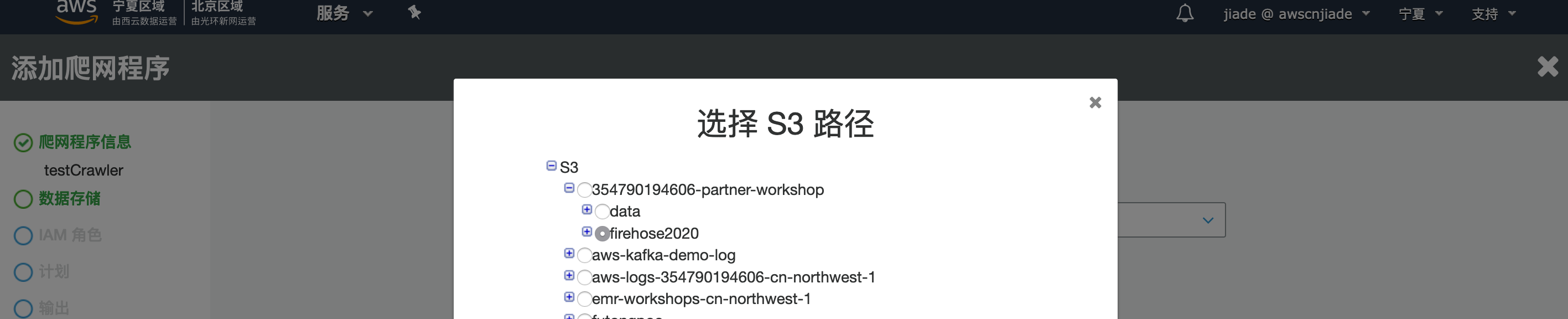
9.单击下一步
10.选择否以添加其他数据存储
11.单击下一步
12.选择一个现有的IAM角色,然后在下拉框中选择Glue-service-role,他应该具有读取S3的权限。
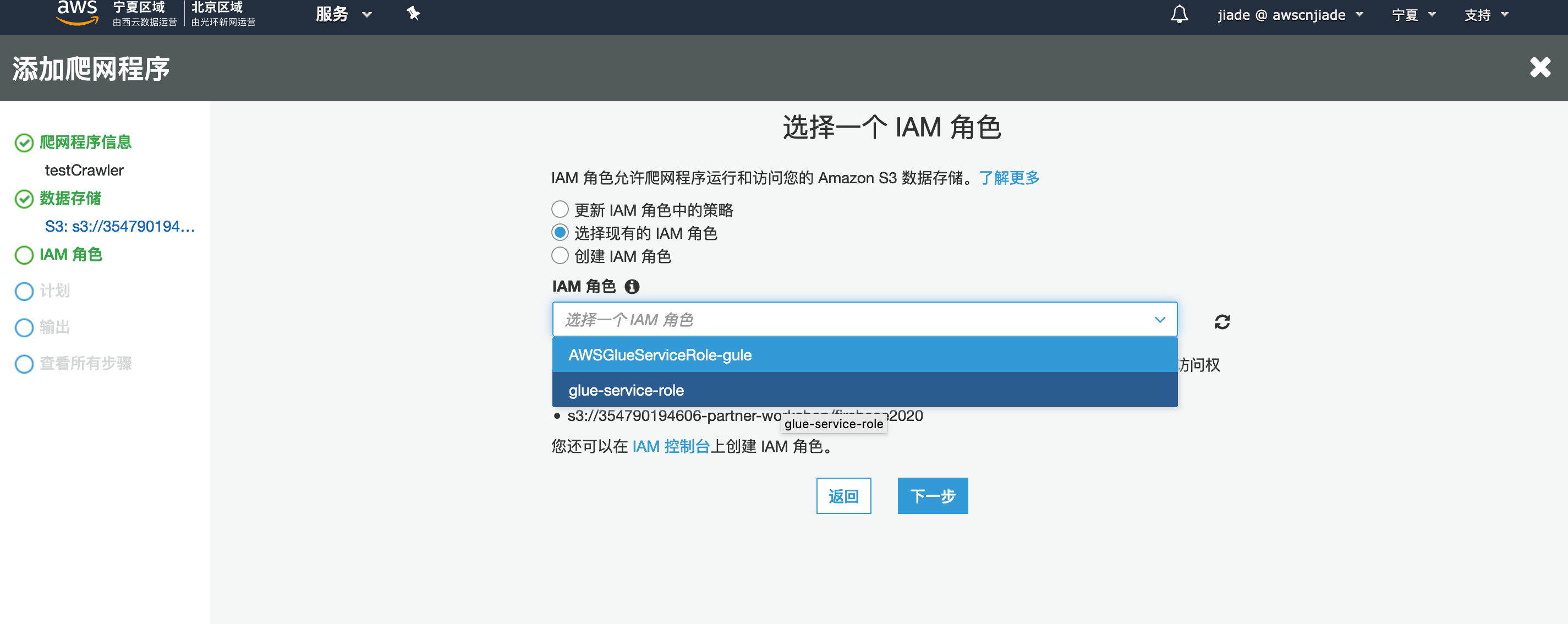
13.单击下一步
14.对于“频率”,选择“按需运行”,然后单击“下一步”。
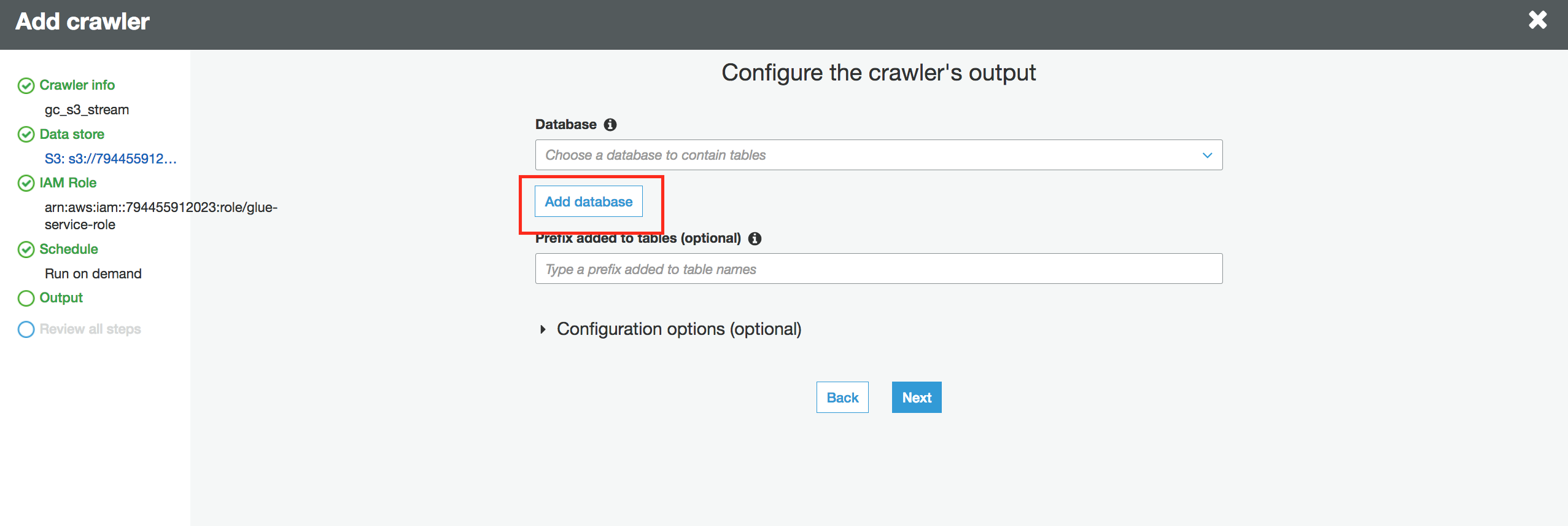
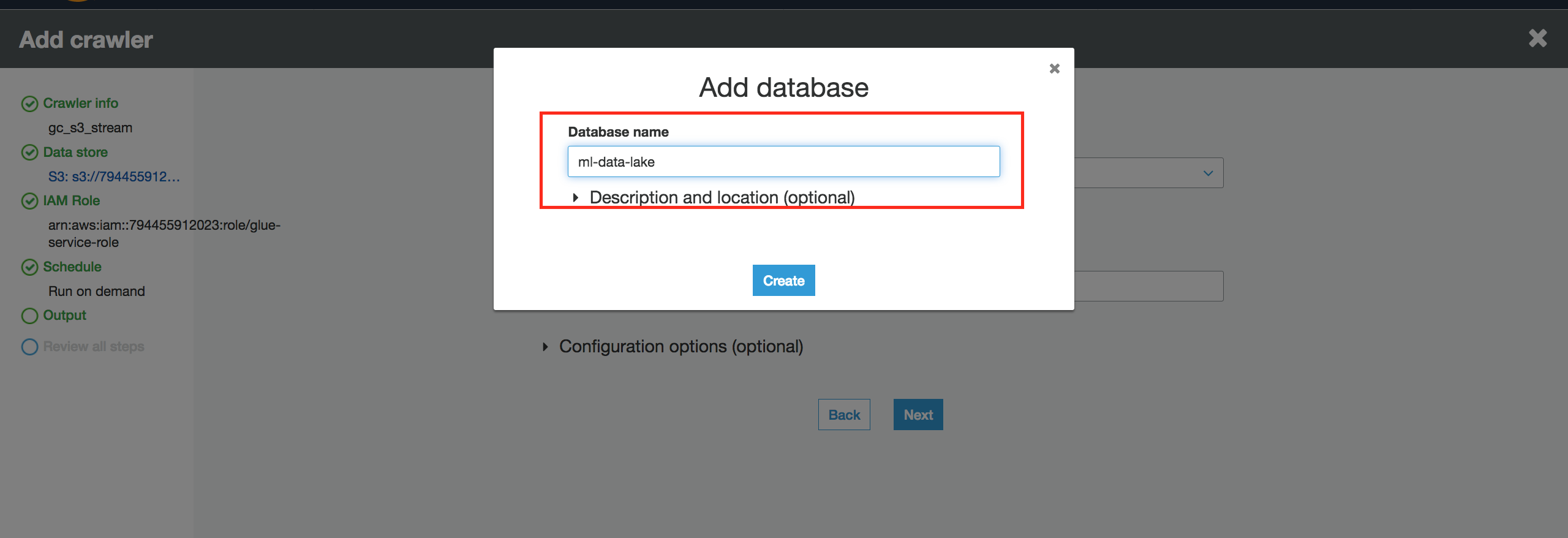
15.对于“数据库”,单击“添加数据库”,例如命名为“ml-data-lake”,然后单击“创建”。
16.单击下一步
17.查看配置,然后单击“完成”。
18.在“爬网程序”页面上,选中刚创建的爬网程序的复选框,然后单击“运行爬网程序”。
19.等待搜寻器完成。
20.单击左侧面板上的数据库,然后选中您自定义的数据库名称(如示例的ml-data-lake)数据库旁边的复选框,然后单击查看表。
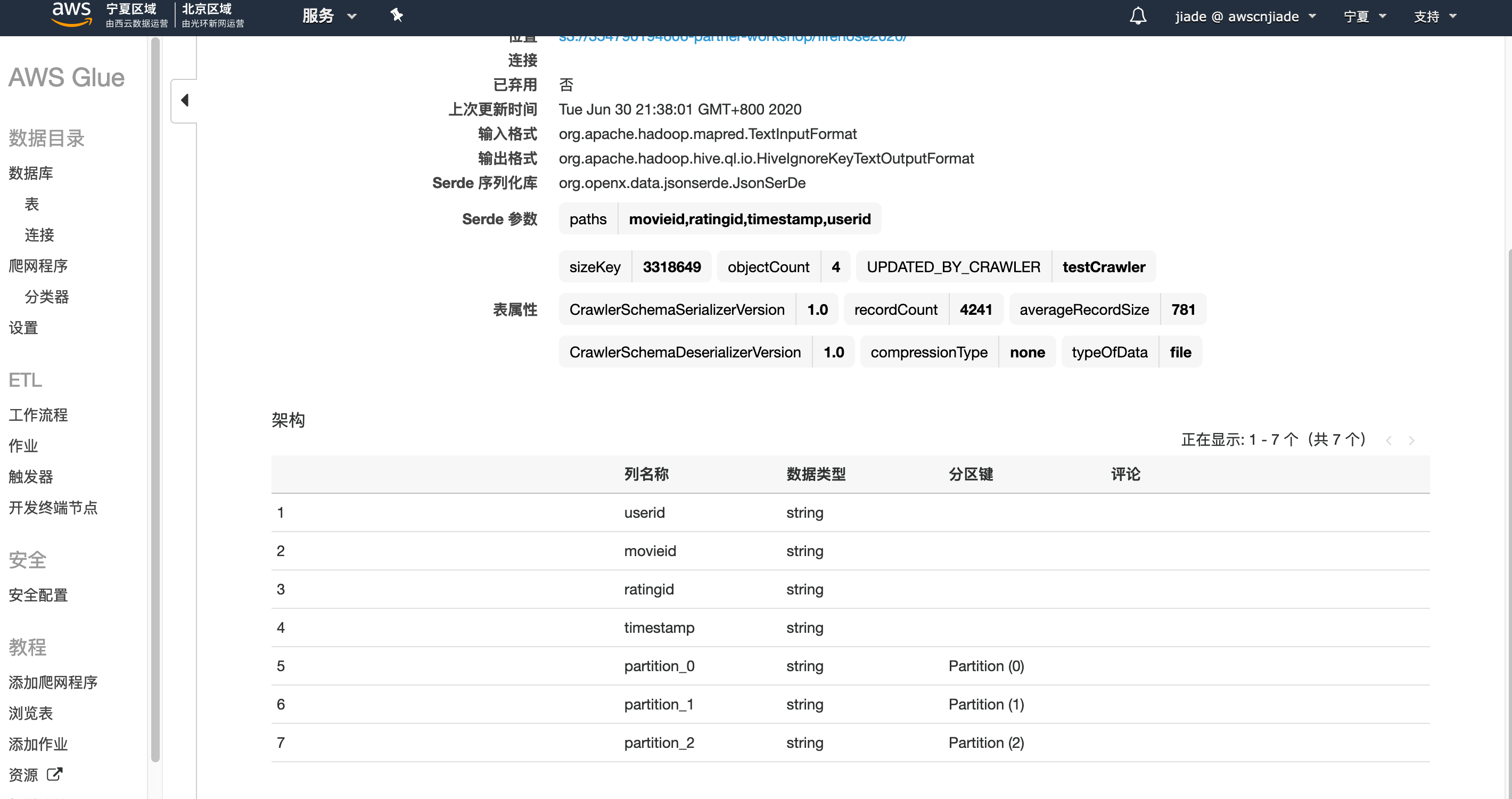
21.验证您的表是根据S3数据创建的。
2.获取DynamoDB Glue数据目录
1.还记得在实验1中lambda下载后被DMS转换到DynamoDB的表吗,它是我们批量摄取数据实验的输出,现在返回AWS管理控制台https://console.aws.amazon.com/。
2.在AWS管理控制台的右上角,确认您位于所需的AWS区域。
3.从所有服务列表中单击“Glue”。 这将带您进入AWS Glue页面。
4.单击左侧面板上的爬网程序,然后单击添加爬网程序
5.对于爬网名称名称,输入你自定义名称, 例如 catalog_dynamodb。
7.单击下一步
8.对于数据存储,请确保已选择DynamoDB。 选择movies_t表,然后单击下一步。
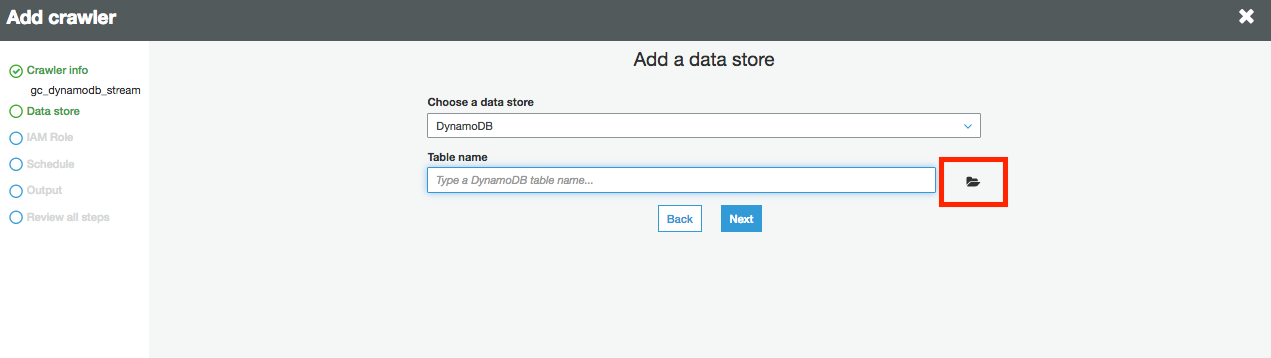
9.单击下一步
10.选择是,添加另一个数据存储
11.对于数据存储,请确保已选择DynamoDB。选择links_t表,然后单击下一步。
12.选择是,添加另一个数据存储
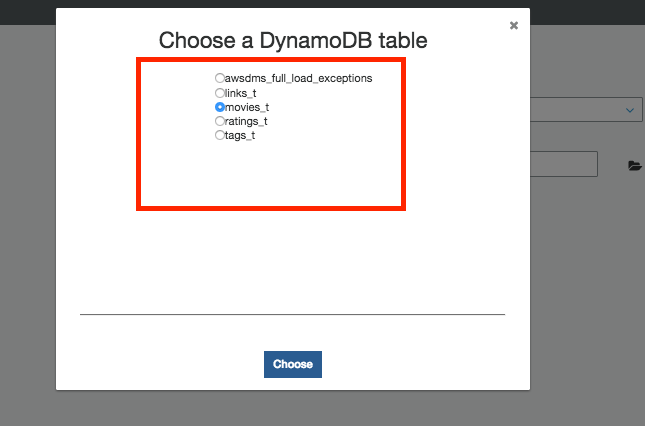
13.对于数据存储,请确保已选择DynamoDB。选择rating_t表,然后单击下一步。现在,您已经选择了在Lab1中创建的3个DynamoDB表。
14.单击下一步
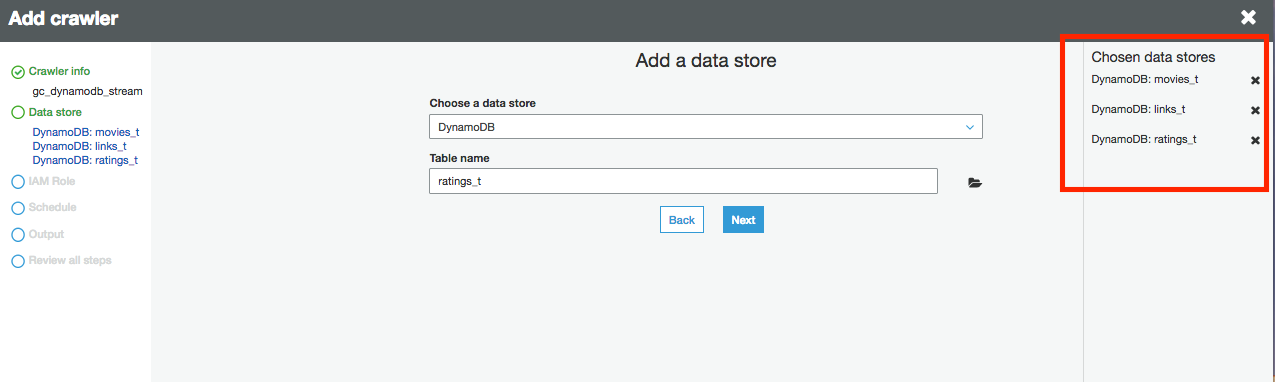
15.选择否以添加其他数据存储
16.选择一个现有的IAM角色,然后在下拉框中选择Glue-service-role 角色。
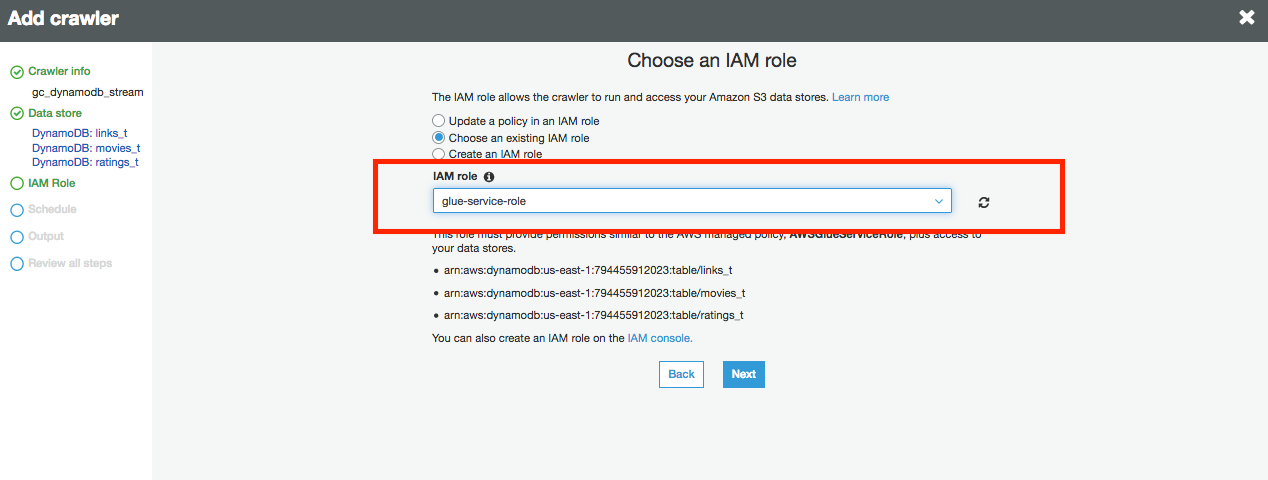
17.单击下一步
18.对于“频率”,选择“按需运行”,然后单击“下一步”。
19.对于数据库,单击选择在上面创建的数据路库,例如ml-data-lake,然后单击创建。
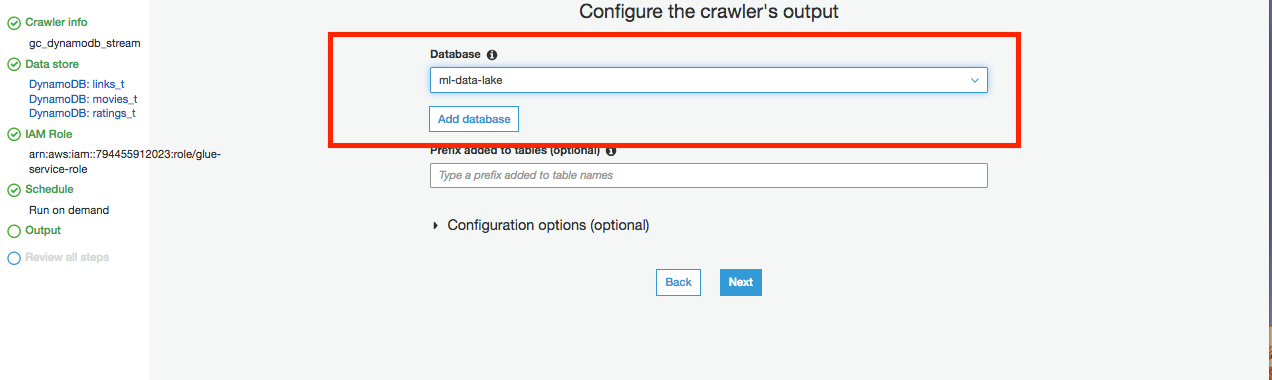
20.单击下一步
21.查看配置,然后单击“完成”。
22.在“爬网程序”页面上,选中刚创建的爬网程序的复选框,然后单击“运行爬网程序”。
22.等待爬虫完成。
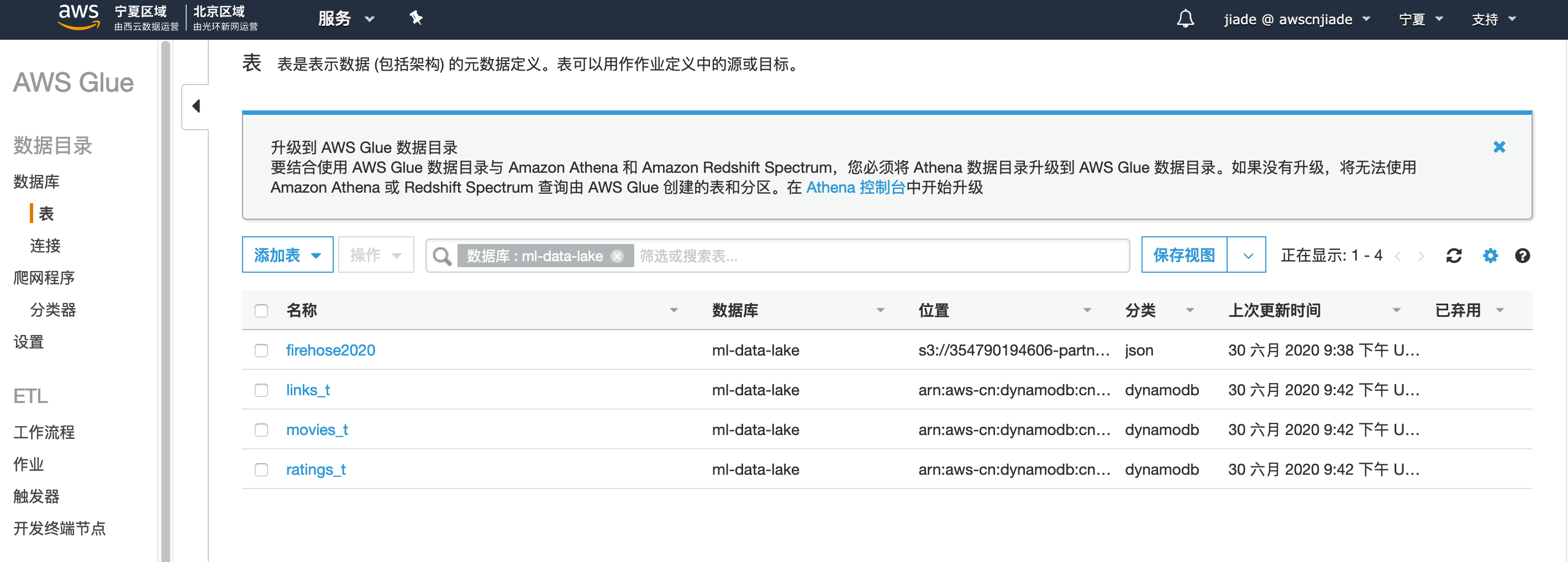
23.单击左侧面板上的数据库,然后选中ml-data-lake数据库旁边的复选框,然后单击查看表。
24.验证是否创建了3个表,这些表存储有关DynamoDB中数据的元数据信息。
3.从Glue转换数据
1.登录到AWS管理控制台https://console.aws.amazon.com/。
2.在AWS管理控制台的右上角,确认您位于所需的AWS地区。
3.从所有服务列表中单击“Glue”。 这将带您进入AWS Glue仪表板页面。
4.单击左侧面板上的 作业。
5.单击添加作业。
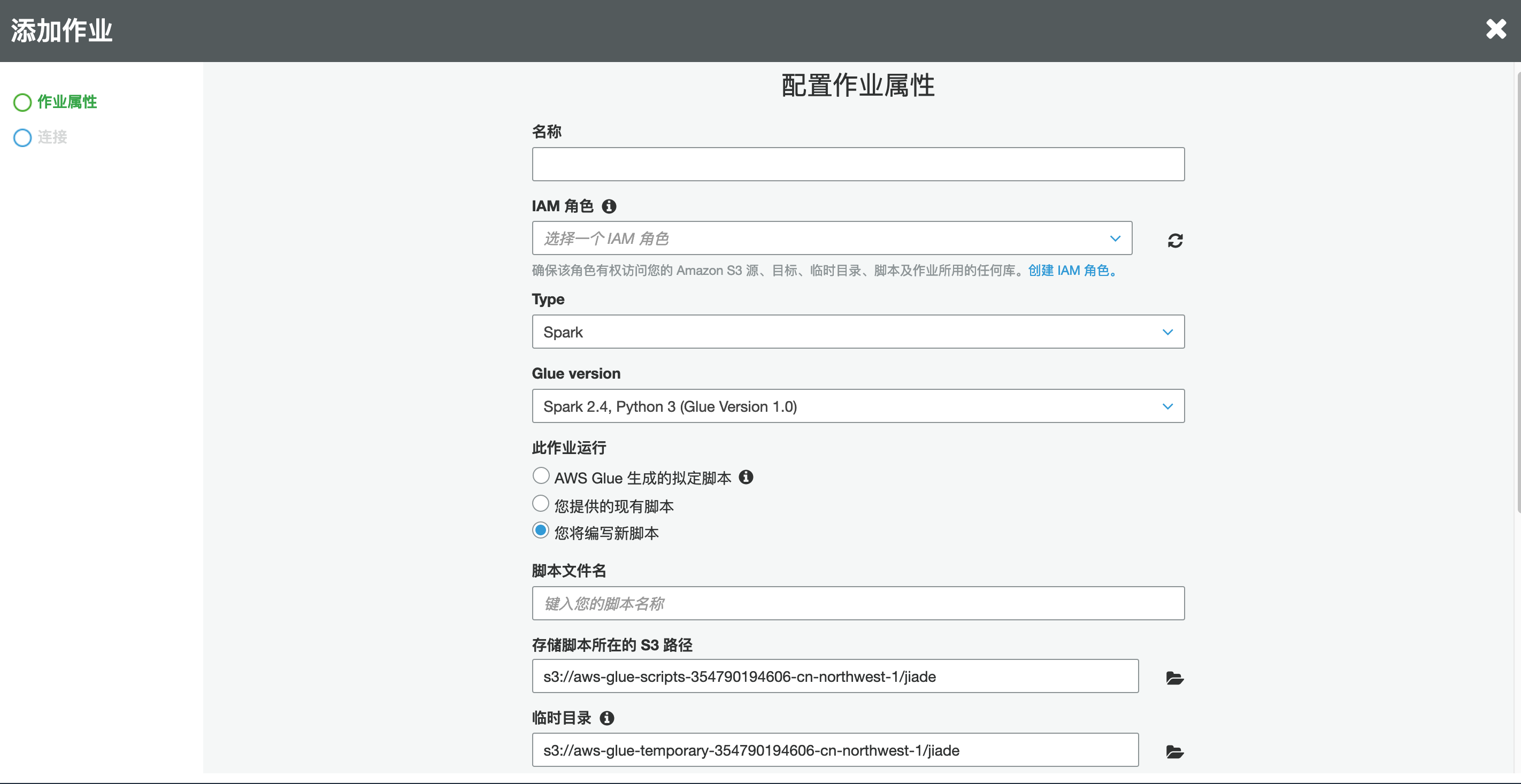
6.在“作业属性”页面中,输入以下内容
名称: 你自定义一个名称,例如“Glue_ETL”
IAM 角色: glue-service-role
Type: Spark
Glue version:Spark 2.4
此作业运行:您将编写新脚本
脚本名称:你自定义一个名称
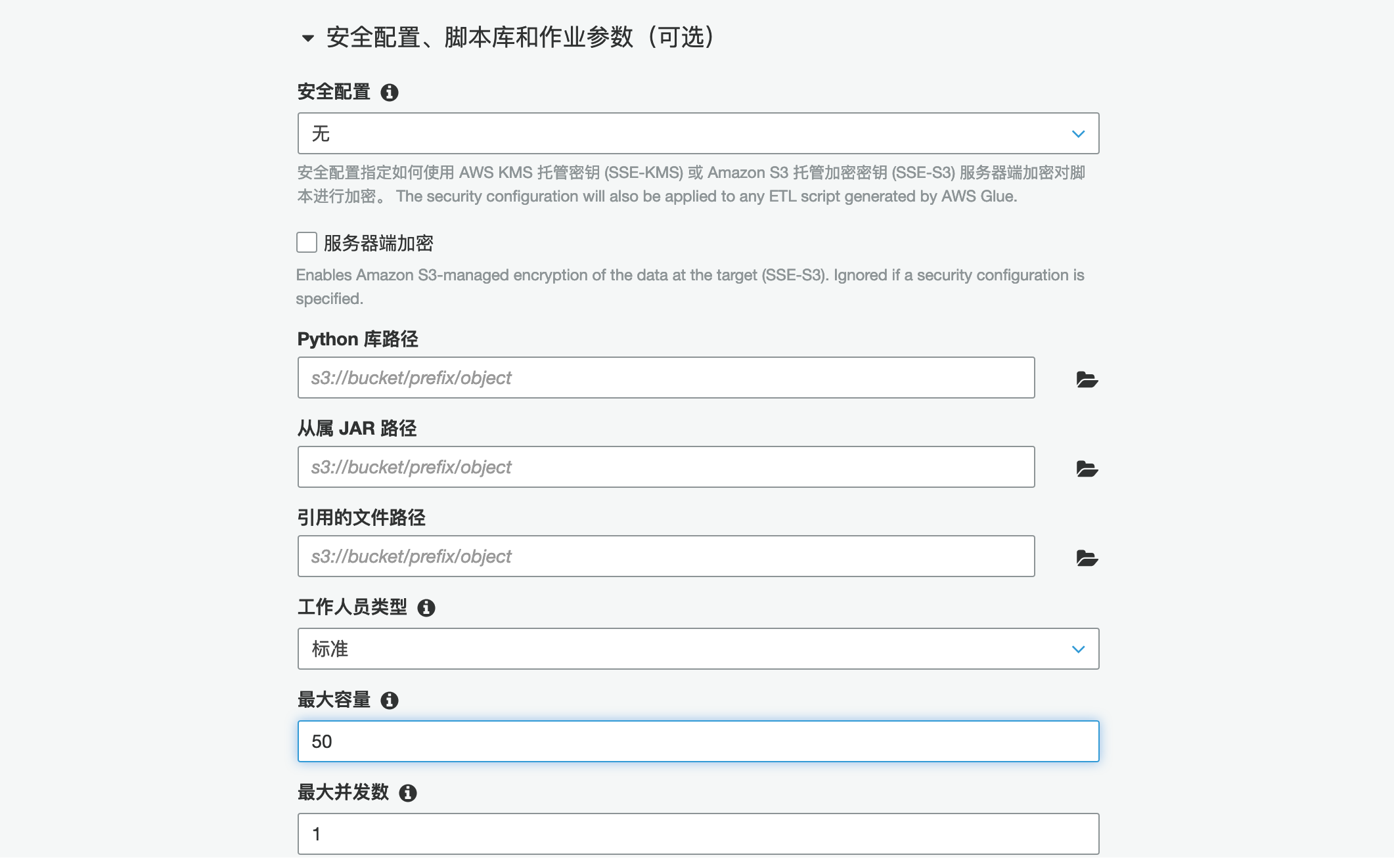
可选:展开脚本库和作业参数部分,并将 作业的并行度 DPU从10更改为50。理解在生成环境中数据量庞大时这将有助于加快转换过程。
9.单击下一步
10.跳过输出表选择,然后单击下一步。 单击保存作业并编辑脚本。
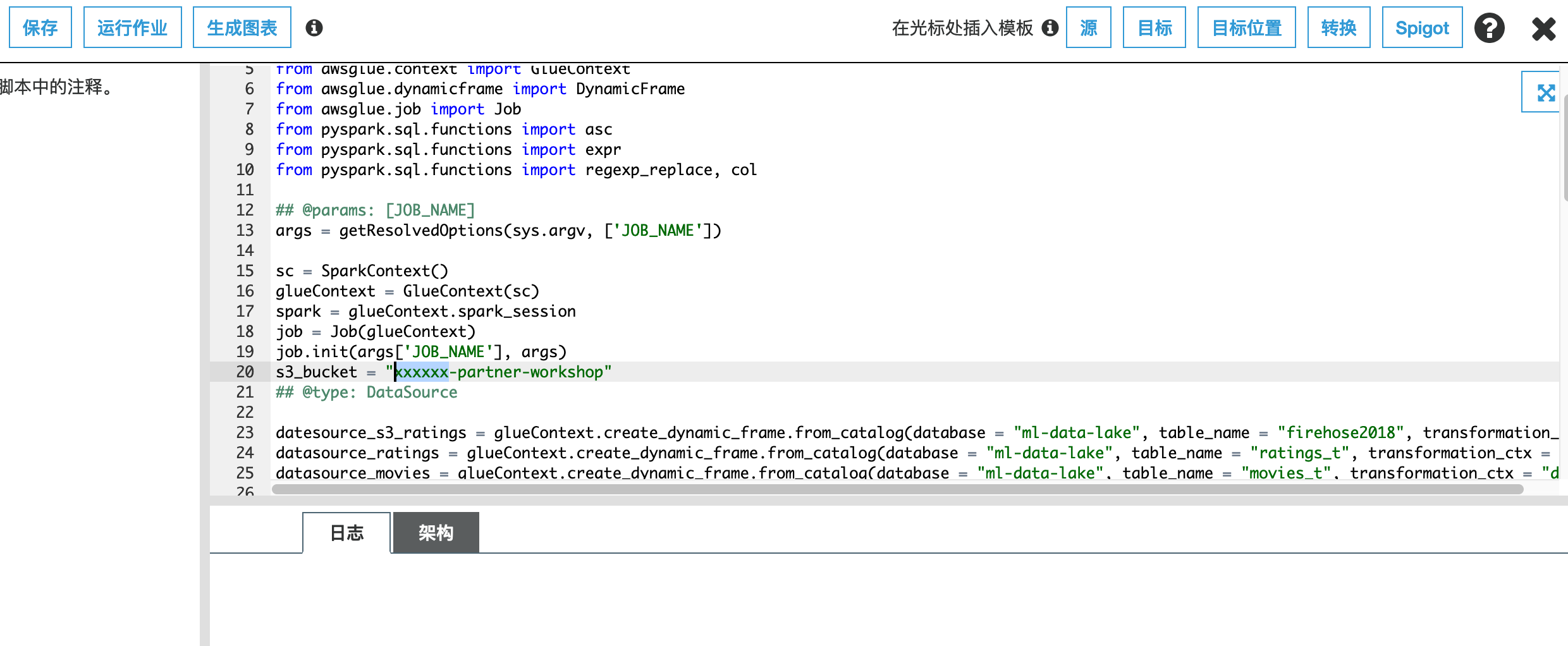
11.在脚本页面中,将该下面的脚本复制到您的Glue编辑器中。 将常量定义s3_bucket更改为您创建的S3存储桶名称,将常量定义database更改为您创建的Glue元数据数据库的名称,将常量定义table_name更改为您创建的Glue元数据表的名称。如以下的xxxxxx-partner-workshop、ml-data-lake、firehose2022、ratings_t….
import sys
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from pyspark.context import SparkContext
from awsglue.context import GlueContext
from awsglue.dynamicframe import DynamicFrame
from awsglue.job import Job
from pyspark.sql.functions import asc
from pyspark.sql.functions import expr
from pyspark.sql.functions import regexp_replace, col
## @params: [JOB_NAME]
args = getResolvedOptions(sys.argv, ['JOB_NAME'])
sc = SparkContext()
glueContext = GlueContext(sc)
spark = glueContext.spark_session
job = Job(glueContext)
job.init(args['JOB_NAME'], args)
s3_bucket = "xxxxxx-partner-workshop"#<--- 调整为你创建的桶的名称
## @type: DataSource
datesource_s3_ratings = glueContext.create_dynamic_frame.from_catalog(database = "ml-data-lake", table_name = "2022", transformation_ctx = "datesource_s3_ratings")
datasource_ratings = glueContext.create_dynamic_frame.from_catalog(database = "ml-data-lake", table_name = "ratings_t", transformation_ctx = "datasource_ratings")
datasource_movies = glueContext.create_dynamic_frame.from_catalog(database = "ml-data-lake", table_name = "movies_t", transformation_ctx = "datasource_movies")
datasource_links = glueContext.create_dynamic_frame.from_catalog(database = "ml-data-lake", table_name = "links_t", transformation_ctx = "datasource_links")
#<--- 以上的4个database和table_name名字,如果您在Glue database中进行了自定义命名请替换为你的命名
#s3_ratings
datasource0 = datesource_s3_ratings.toDF()
datasource0 = datasource0.withColumn("userid", expr("CAST(userid AS INTEGER)"))
datasource0 = datasource0.withColumn("movieid", expr("CAST(movieid AS INTEGER)"))
datasource0 = datasource0.select(["userid", "movieid", "ratingid", "timestamp"])
datasource0 = datasource0.filter(datasource0["userid"].isNotNull())
#ratings
datasource1 = datasource_ratings.toDF()
datasource1 = datasource1.withColumn("timestamp_c",regexp_replace("timestamp_c", "\"", ""))
datasource1 = datasource1.withColumn("userid", expr("CAST(userid AS INTEGER)"))
datasource1 = datasource1.withColumn("movieid", expr("CAST(movieid AS INTEGER)"))
datasource1 = datasource1.select(["userid", "movieid", "rating", "timestamp_c"])
datasource1 = datasource1.filter(datasource1["userid"].isNotNull())
#聚合ratings和s3_ratings写为rating.csv
dfUnion = datasource1.union(datasource0).sort(asc("userid"),asc("movieid"))
dfUnion.coalesce(1).write.option("header", "true").csv("s3://" + s3_bucket + "/ml/trainingdata/rating")
#movies
datasource2 = datasource_movies.toDF()
datasource2 = datasource2.withColumn("movieid", expr("CAST(movieid AS INTEGER)"))
datasource2 = datasource2.withColumn("genres",regexp_replace("genres", "\"", ""))
datasource2 = datasource2.withColumn("title",regexp_replace("title", "\"", ""))
datasource2 = datasource2.select(["movieid", "title", "genres"]).sort(asc("movieid"))
datasource2 = datasource2.filter(datasource2["movieid"].isNotNull())
datasource2.coalesce(1).write.option("header", "true").csv("s3://" + s3_bucket + "/ml/trainingdata/movies")
#links
datasource3 = datasource_links.toDF()
datasource3 = datasource3.withColumn("movieid", expr("CAST(movieid AS INTEGER)"))
datasource3 = datasource3.withColumn("tmdbid",regexp_replace("tmdbid", "\"", ""))
datasource3 = datasource3.select(["movieid", "imdbid", "tmdbid"]).sort(asc("movieid"))
datasource3 = datasource3.filter(datasource3["movieid"].isNotNull())
datasource3.coalesce(1).write.option("header", "true").csv("s3://" + s3_bucket + "/ml/trainingdata/links")
job.commit()
12.单击运行作业,在新版本的GlueETL中,底层使用容器进行计算,因此作业大约在1分钟之内完成。
13.如代码所示,作业读取并转换了三张表,分别是 评分,电影,链接 ,评分表为聚合ratings和s3_ratings写为rating.csv,电影和链接表既是由DynamoDB转换来的csv,当前保存在S3。作业完成后,请前往S3桶验证" s3://您的账号+partner-workshop/ml/trainingdata/“里面将生成三张表的数据。
以上,我们完成了实验3的内容。请您思考并讨论,在实际的生产环境中如何定义自动化的工作流让这些批量处理工作自动进行。