实验5:SageMaker
使用sagemaker进行数据湖上的机器学习 本环节我们学习如何使用Sagemaker的Jupyter notebook组件进行模型训练和推理,最终实现电影推荐模型的API对外服务。
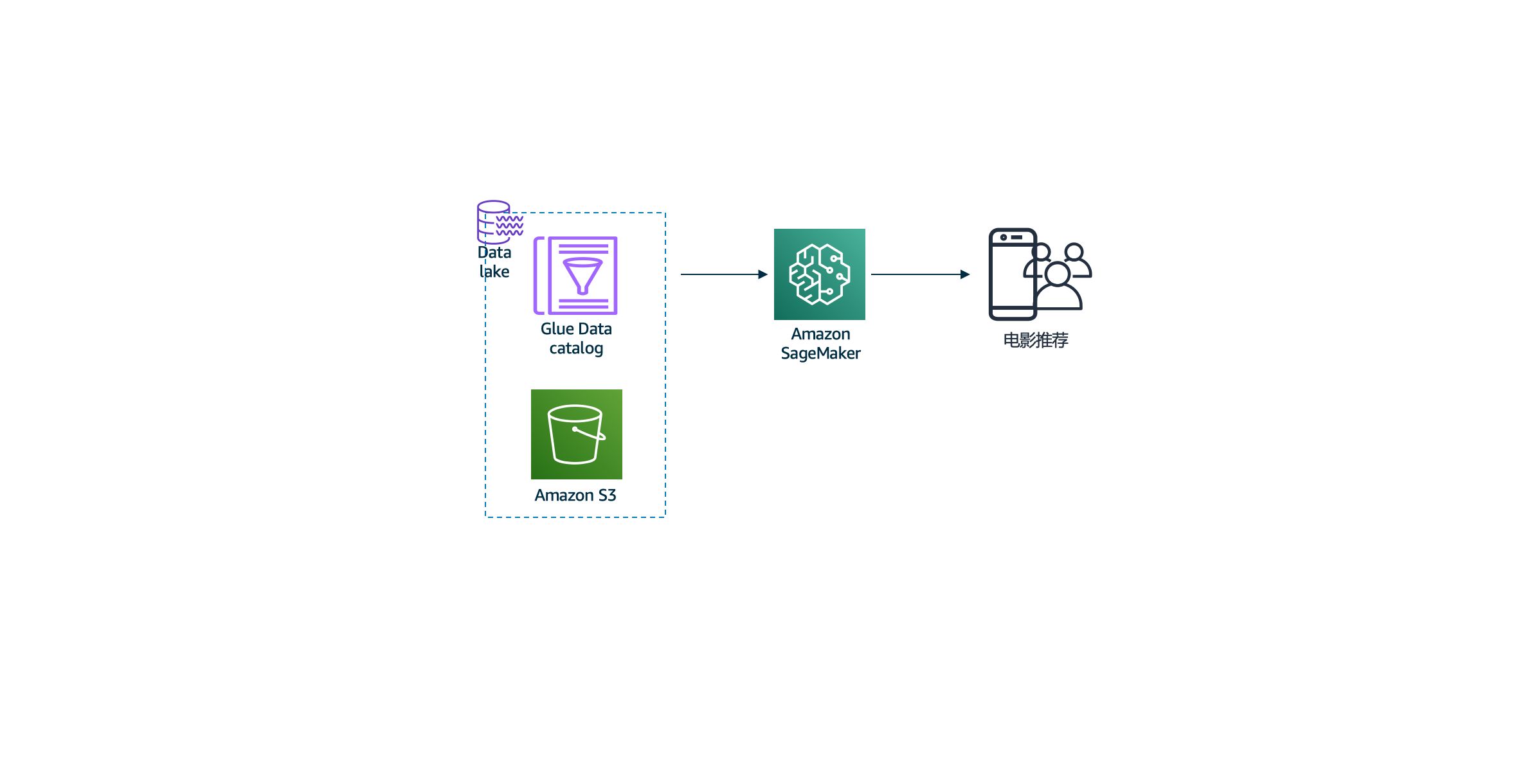
此时,您应该将所有文件都放在AWS S3存储桶中,以准备进行数据科学工作。 以下步骤将引导您完成本部分实验所需的所有过程。
步骤1:启动Amazon SageMaker Notebook实例
1.打开AWS管理控制台,搜索,然后 选择SageMaker。
2.在SageMaker仪表板中,单击创建笔记本实例。
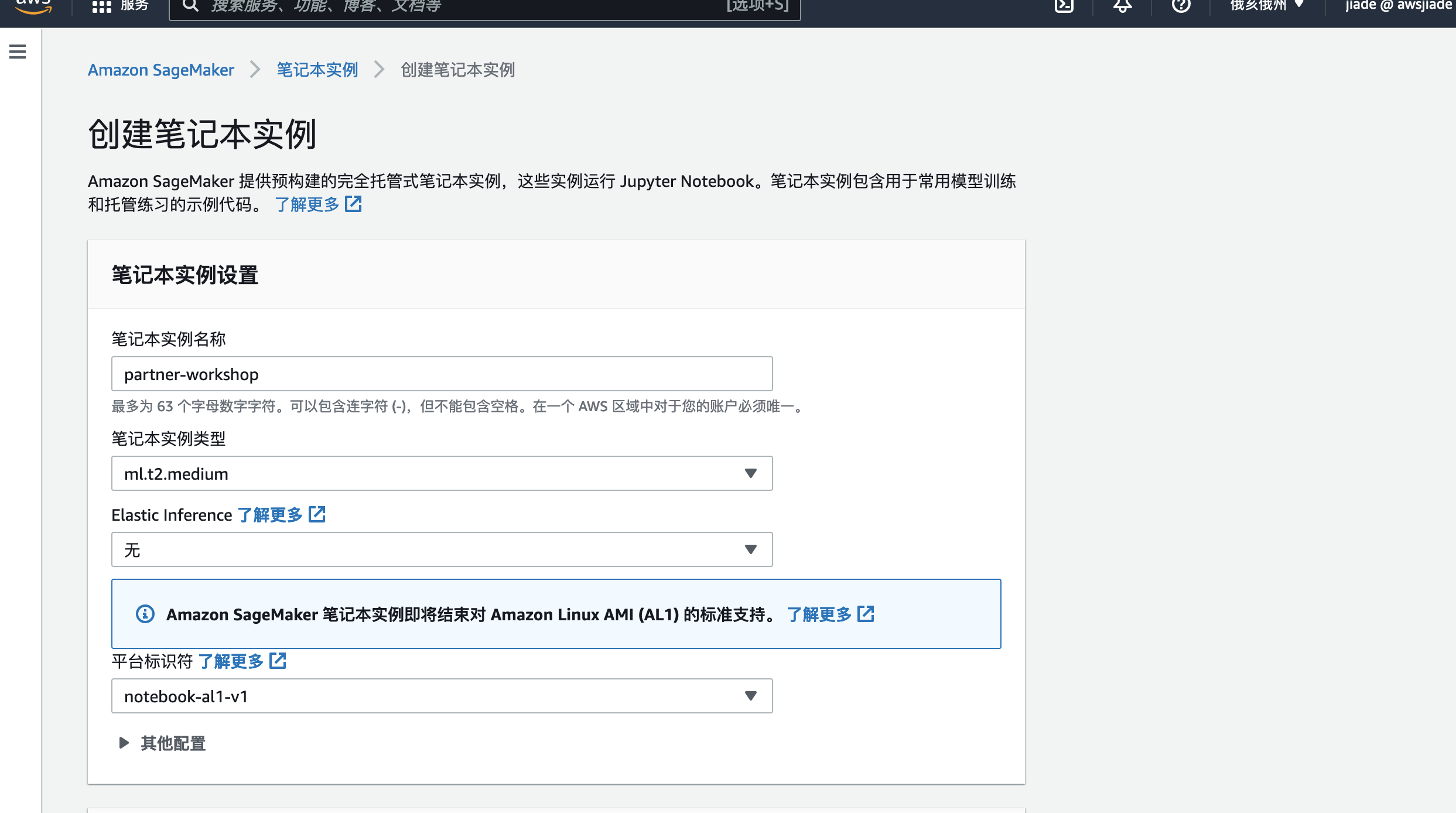
3.在“创建笔记本实例”页面上,执行以下操作:
- 给笔记本实例命名,例如
partner-workshop。 - 选择ml.m4.2xlarge作为笔记本实例类型(选择更大的实例将提升我们训练的速度,但也会提升实验成本)。
- 对于您的IAM角色-从下拉菜单中选择“创建新角色”。
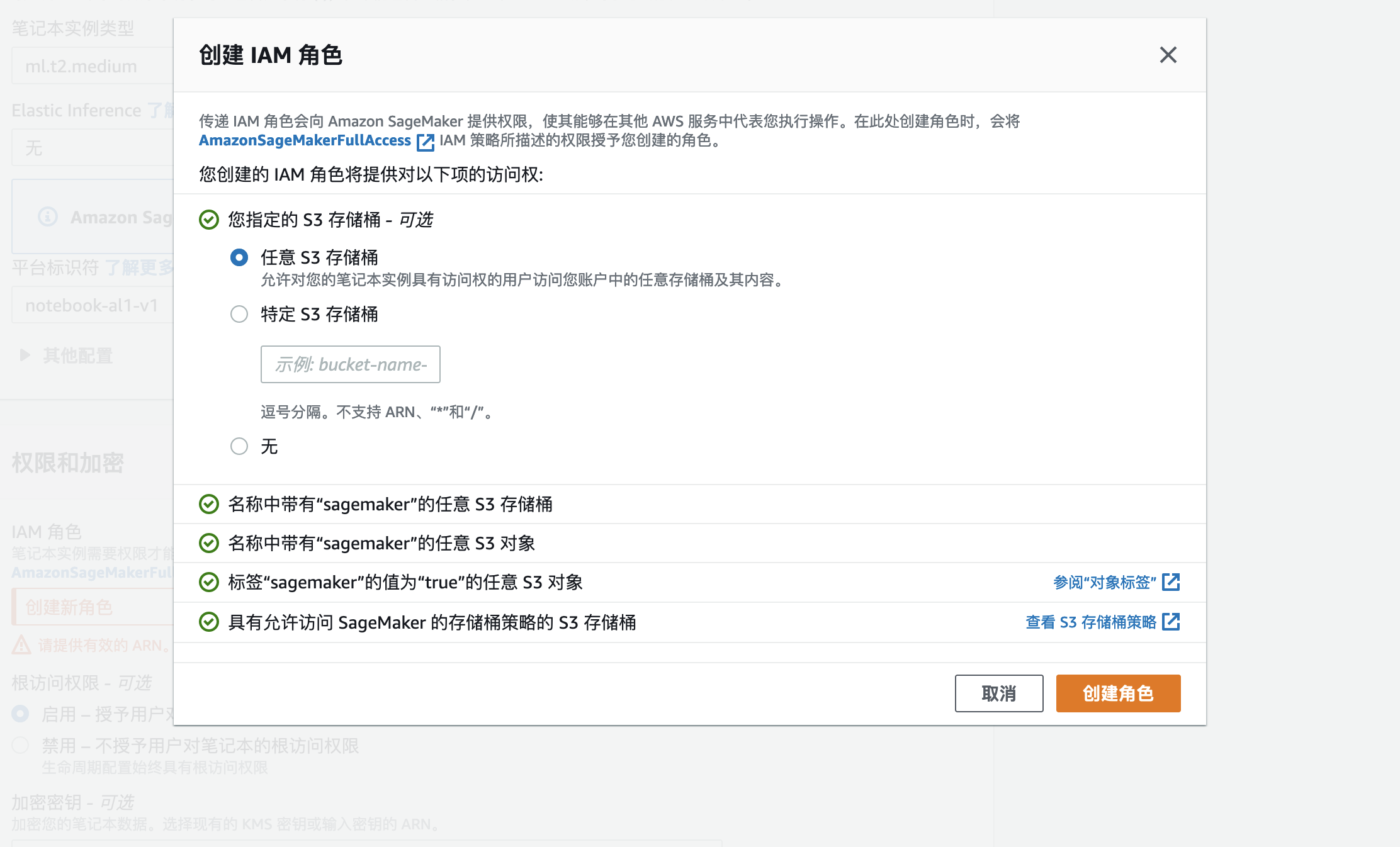
4.从弹出对话框中选择任何S3存储桶并创建角色
5.Amazon SageMaker将为您创建一个新角色并预先选择该角色。接下来创建笔记本实例。
6.如果您在这里,则您的实例正在启动;因此处于Pending状态。您应该可以在5分钟内访问笔记本电脑。
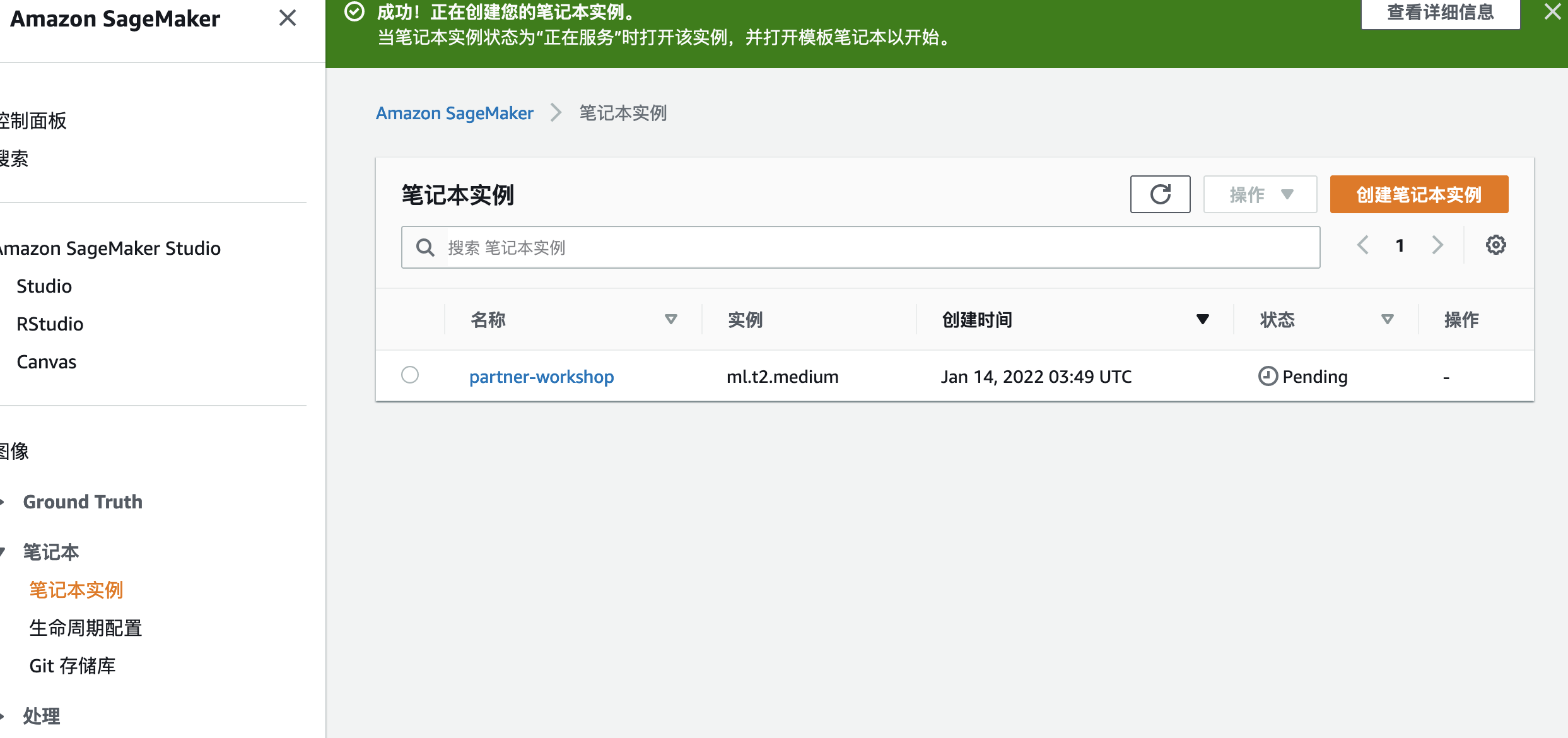
步骤2:访问您的笔记本实例
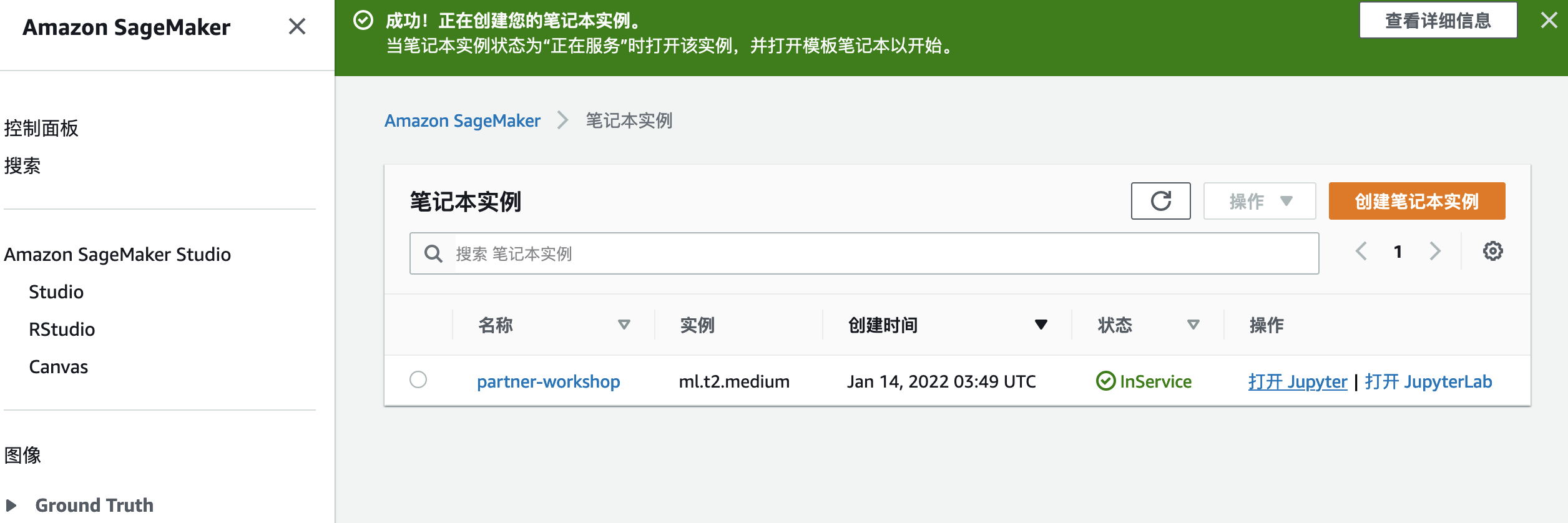
1.要访问笔记本,请等到实例状态为 InService并单击 打开jupyter。
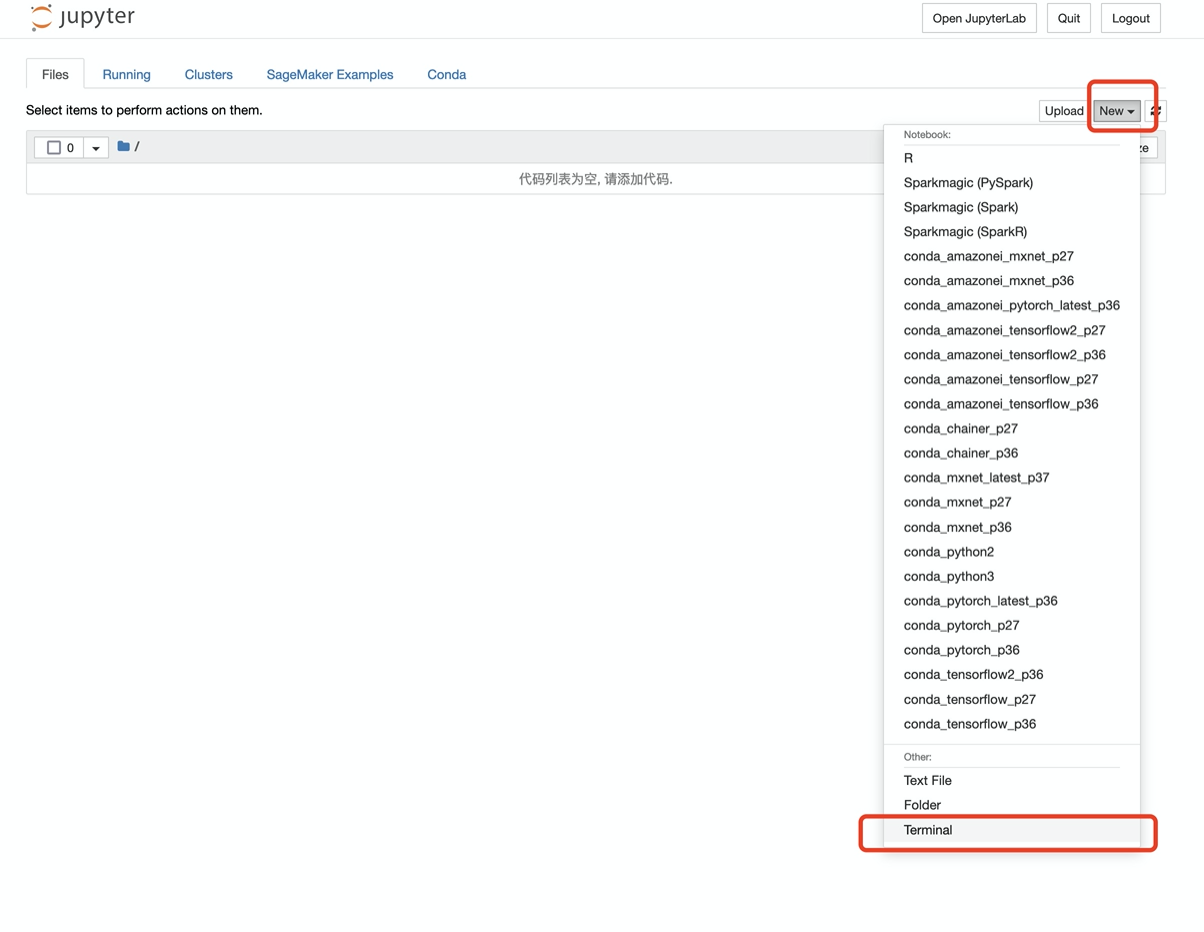
2.您的笔记本登录页面应类似于以下内容,请单击“NEW”,然后单击“终端”,打开一个终端。
4.在终端中运行以下命令(复制,粘贴并按Enter),并确保遵循终端屏幕上的指示输入您的S3桶名称和您的名字。
wget https://partner-workshops-cn-northwest-1.s3.cn-northwest-1.amazonaws.com.cn/sh-scripts/Helper.sh
sh Helper.sh
5.运行以上两个命令后,您的输出应类似于以下内容:
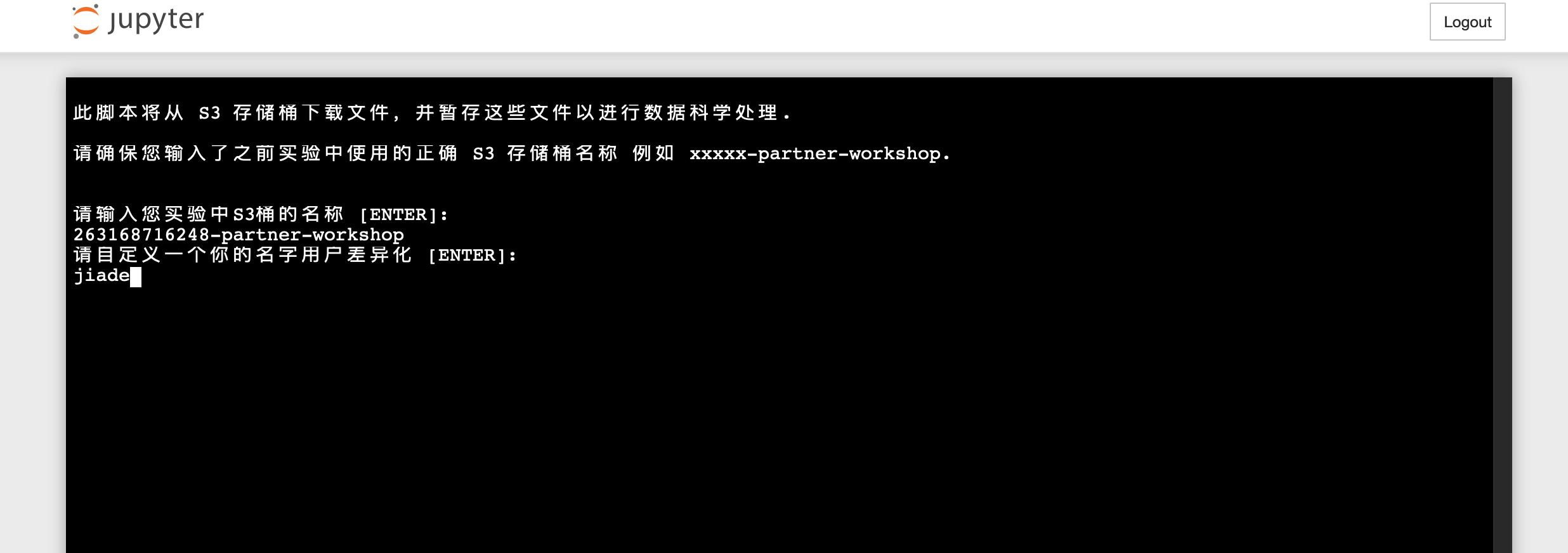
请按照您的环境输入S3 bucket name,例如263168716248-partner-workshop,然后输入您的自定义名称 ,例如demo,这两个变量会自动填写到nodebook的代码中,您即可无需手动修改里面的代码
此脚本将从 S3 存储桶下载文件,并暂存这些文件以进行数据科学处理.
请确保您输入了之前实验中使用的正确 S3 存储桶名称 例如 xxxxx-partner-workshop.
请输入您实验中S3桶的名称 [ENTER]:
263168716248-partner-workshop
请自定义一个你的名字用户差异化 [ENTER]:
jiade
6.完成后回到jupyter netobook的home页面(浏览器页面)。 单击Movie_Recommender.ipynb笔记本,然后按照笔记本中的说明进行操作。
7.接下来,请您离开此页面,在Movie_Recommender _Lab5.ipynb笔记本中按照指导完成本实验。