实验4:Athena & Superset
使用superset和Athena进行数据可视化
- 针对处理后的数据,我们将使用Athena读取Glue中的表结构,读取S3中的数据进行SQL查询,再使用superset进行可视化的展示。
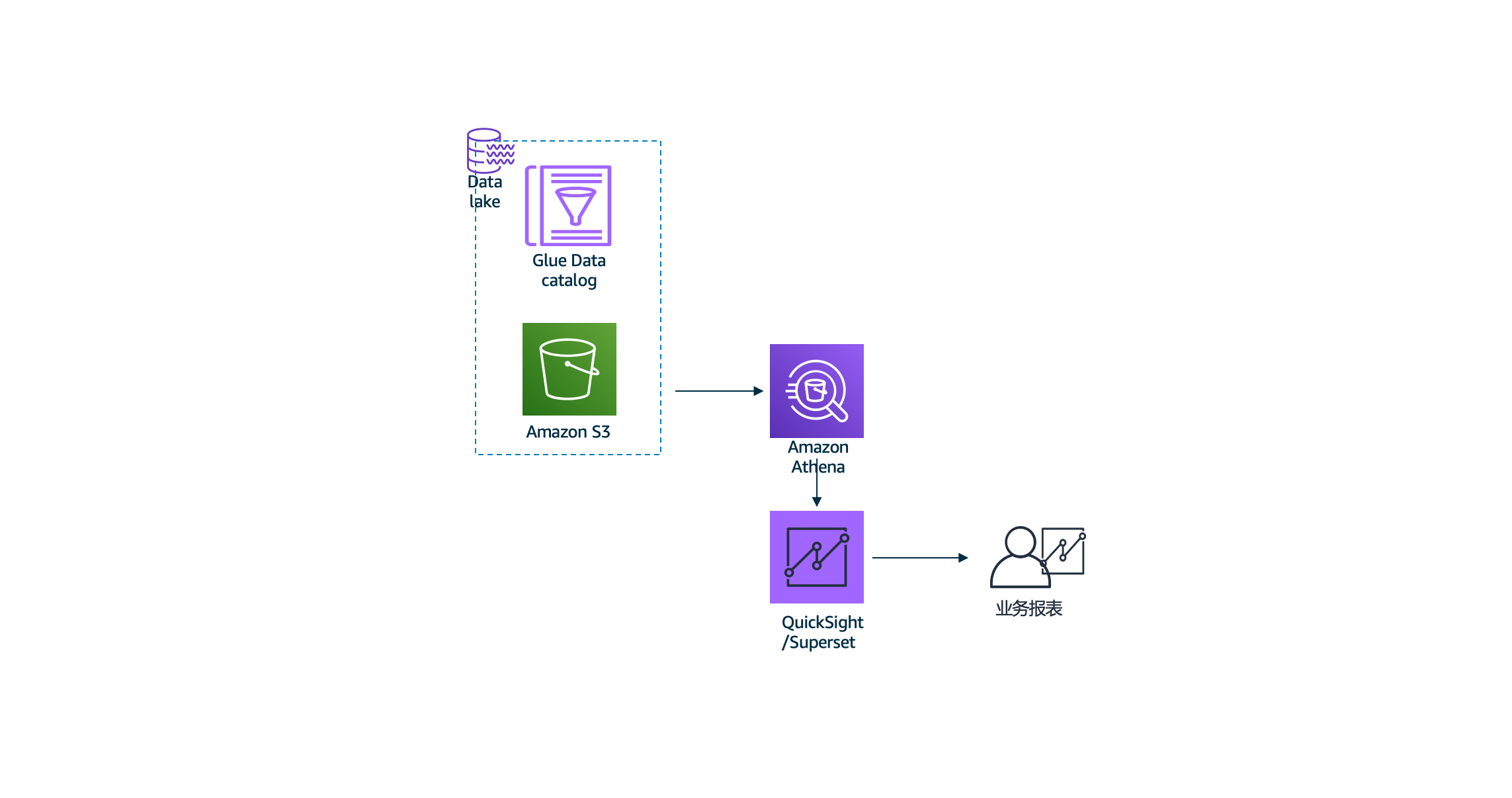
由于目前中国区region没有上线QuickSight服务,可视化环节我们将使用本地Docker部署superset来进行,要完成本实验,请确保您的本地环境已经安装Docker。您可以参考这里的指导快速完成Docker在本地的安装。您也可以快速启动一台EC2或EKS/ECS来部署superset镜像。
安装superset
1,如果您已经安装了Docker,请执行docker version 检查是否安装成功。
➜ docker version
Client: Docker Engine - Community
Version: 19.03.8
API version: 1.40
Go version: go1.12.17
Git commit: afacb8b
Built: Wed Mar 11 01:21:11 2020
OS/Arch: darwin/amd64
Experimental: false.................
2,现在,我们从互联网下载Superset docker镜像
请使用拉取镜像的命令:docker pull amancevice/superset
Using default tag: latest
latest: Pulling from amancevice/superset
8f0fdd3eaac0: Downloading [===> ] 3.578MB/50.38MB
d918eaefd9de: Downloading [====================> ] 3.144MB/7.812MB
43bf3e3107f5: Downloading [===============> ] 3.062MB/9.996MB
27622921edb2: Waiting
dcfa0aa1ae2c: Waiting
ca7e1bbea389: Waiting .................
检查是否已经完成镜像的下载:docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
amancevice/superset latest 796cfafa63e2 6 weeks ago 1.8GB
3,启动Superset容器 docker run -p 8088:8088 -d amancevice/superset
docker run -p 8088:8088 -d amancevice/superset
989c3f7b54397ba0e94cc69a73be95842c1c909a64e91439801f45396f88af3d
4,查看Superset容器运行状态,docker ps
➜ docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
7c5786163f7f amancevice/superset "gunicorn superset.a…" 2 hours ago Up 2 hours (healthy) 0.0.0.0:8088->8088/tcp sleepy_euclid
➜ superset
5,初始化Superset容器,注册账号信息,并等待初始化完成,请将查看docker状态命令中的CONTAINER ID指定在命令中,执行docker exec -it CONTAINERID superset-init,例如docker exec -it 7c5786163f7f superset-init。随后自定义账户信息您可以全部输入admin或您自定义的名字
➜ docker exec -it 7c5786163f7f superset-init
Username [admin]: admin
User first name [admin]: admin
User last name [user]: admin
Email [admin@fab.org]: admin
Password:
Repeat for confirmation:
/usr/local/lib/python3.6/site-packages/psycopg2/__init__.py:144: UserWarning: The psycopg2 wheel package will be renamed from release 2.8; in order to keep installing from binary please use "pip install psycopg2-binary" instead. For details see: <http://initd.org/psycopg/docs/install.html#binary-install-from-pypi>.
""")
2020-03-03 08:13:49,694:INFO:root:logging was configured successfully
2020-03-03 08:13:49,819:INFO:root:Configured ....................
6,最后,为superset加入连接Athena需要的依赖,请执行docker exec -it CONTAINERID pip install PyAthenaJDBC
➜ docker exec -it 7c5786163f7f pip install PyAthenaJDBC
Defaulting to user installation because normal site-packages is not writeable
Requirement already satisfied: PyAthenaJDBC in ./.local/lib/python3.6/site-packages (2.1.0)
Requirement already satisfied: jpype1<=0.7.0,>=0.6.0 in ./.local/lib/python3.6/site-packages (from PyAthenaJDBC) (0.7.0)
Requirement already satisfied: future in /usr/local/lib/python3.6/site-packages (from PyAthenaJDBC) (0.18.2)
以上,我们完成了Superset的安装和对接Athena的准备工作。
Glue创建聚合后的rating表catalog
现在您可以在数据库中添加表,还记得我们刚刚用 Glue 聚合了两个评分表吗,我们可以再用Glue创建他的表结构,并在superset里使用他
-
登录到AWS管理控制台https://console.aws.amazon.com/。
-
在AWS管理控制台的右上角,确认您位于所需的AWS区域。
-
从所有服务列表中单击“Glue”。这将带您进入AWS Glue控制台页面。
-
单击左侧面板上的“爬网程序”,然后单击“添加爬网程序”
-
对于爬网程序名称名称,输入你自定义的名称,例如
RatingForSuperset。 -
单击下一步
-
对于数据存储,请确保已选择S3。浏览到在实验1中创建的存储桶(实验1中记录的存储桶)中的xxxxxx-Partner-works。单击选择,在点击到您在上一环节中将两张rating表做聚合ETL输出的路径,如这里的
354790194606-partner-workshop/ml/trainingdata/rating/。
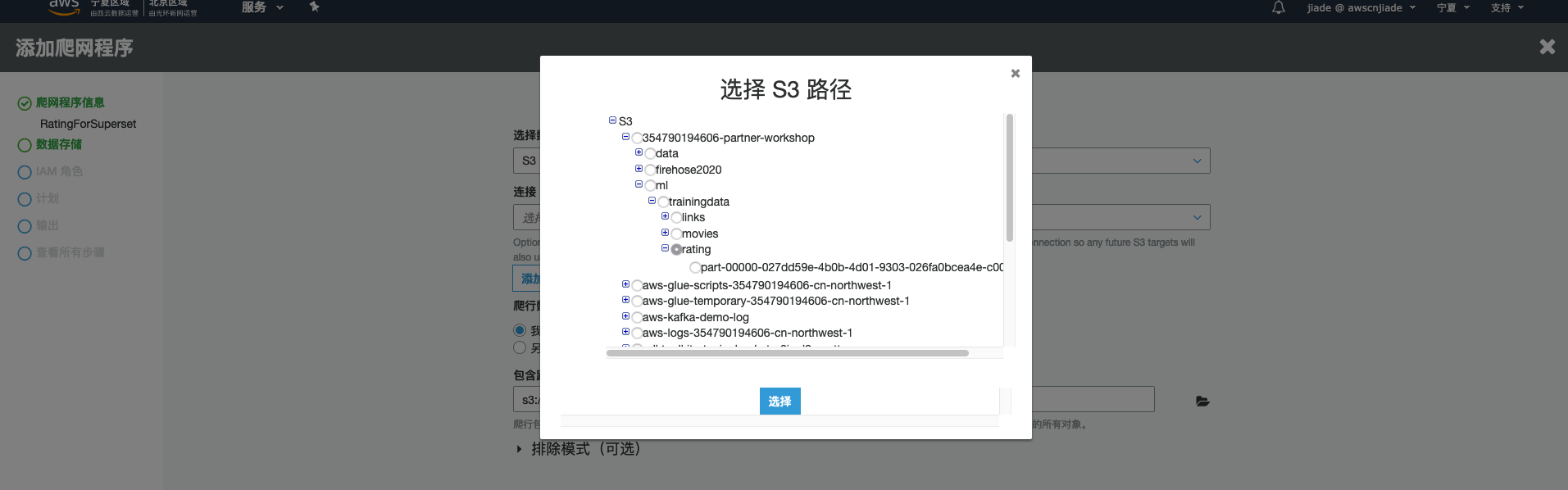
-
单击下一步
-
选择
否以添加其他数据存储 -
单击下一步
-
选择一个现有的IAM角色,然后在下拉框中选择glue-service-role,他应该具有读取S3的权限。
-
单击下一步
-
对于“频率”,选择“按需运行”,然后单击“下一步”。
-
对于“数据库”,单击“添加数据库”,例如命名为“ml-data-lake”,然后单击“创建”。
-
单击下一步
-
查看配置,然后单击“完成”。
-
在“爬网程序”页面上,选中刚创建的爬网程序的复选框,然后单击“运行爬网程序”。
-
等待搜寻器完成。
-
单击左侧面板上的数据库,然后选中您自定义的数据库名称(如示例的ml-data-lake)数据库旁边的复选框,然后单击查看表。
-
验证您的表是根据S3数据创建的。 表名为
rating
使用Athena查询数据
现在我们配置Athena查询rating的数据。
-
登录到AWS管理控制台https://console.aws.amazon.com/。
-
在AWS管理控制台的右上角,确认您位于所需的AWS区域。
-
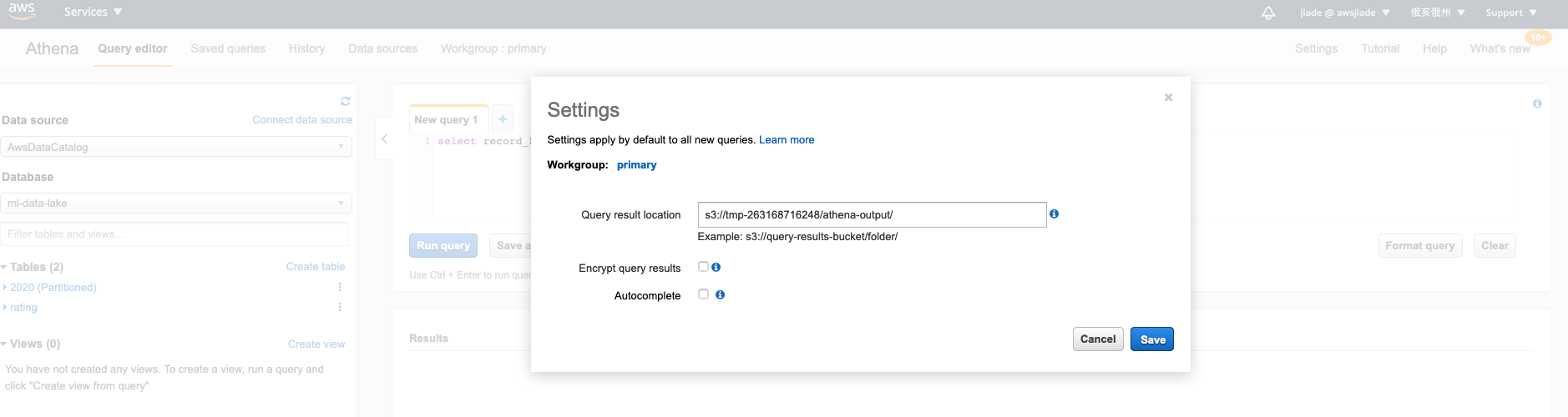
从所有服务列表中单击“Athena”。这将带您进入Athena控制台页面。 如果您的账号之前没有使用过Athena,你将看见欢迎导航页面,导航会要求你输入
Athena Query result location,这是你未来使用Athena进行查询保存结果的S3位置,请您输入任意自定义的路径,例如s3://tmp-263168716248/athena-output/.未来你也可以通过Athena页面右上角的Settings按钮配置该项
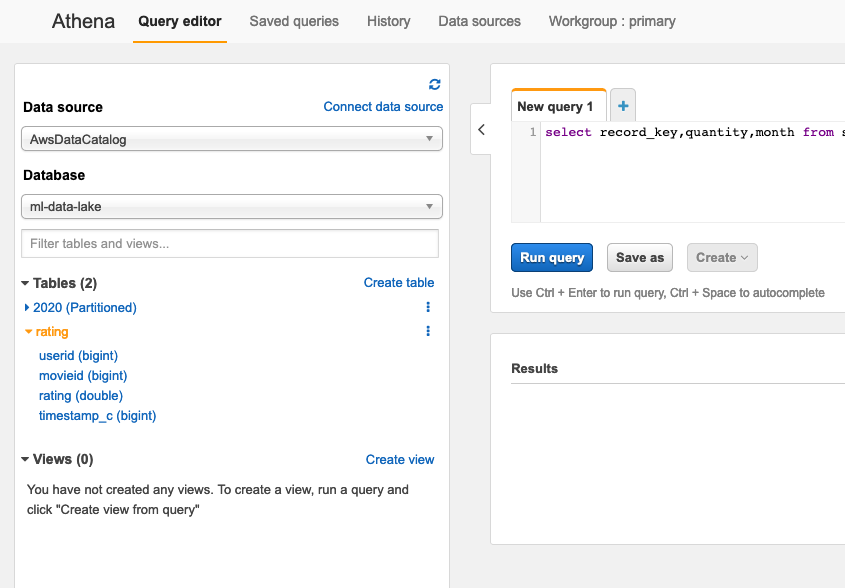
- 完成设置后您将看见Athena的实验页面,点击左侧的Database,选择您在Glue中自定义的数据库名称,例如
ml-data-lake,这样您将在Tables项看见Glue中存储的两个表,2020和rating(它们的数据在S3,数据结构在Glue catalog)。
- 查询表数据,现在您可以点击表名称操作按钮,点击Preview table。或是在query窗口输入任意你需要的SQL去操作和查询表。
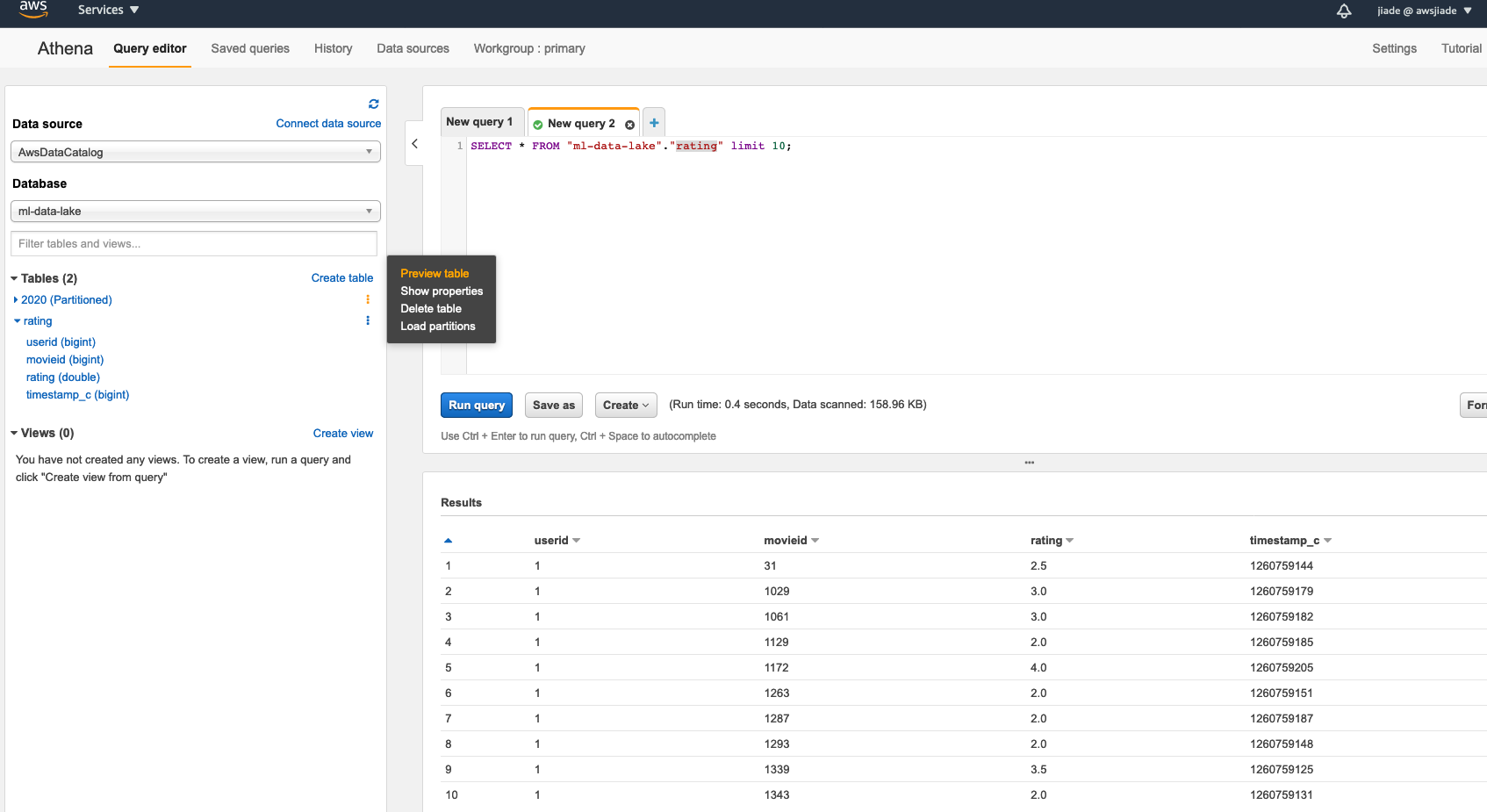
使用superset与Athena连接
我们继续配置,完成superset对接Athena,以实现可视化 1,首先,我们为superset准备一个具有权限的IAM用户
- 导航到aws控制台,点击服务,输入IAM,这将导航至IAM控制台页面
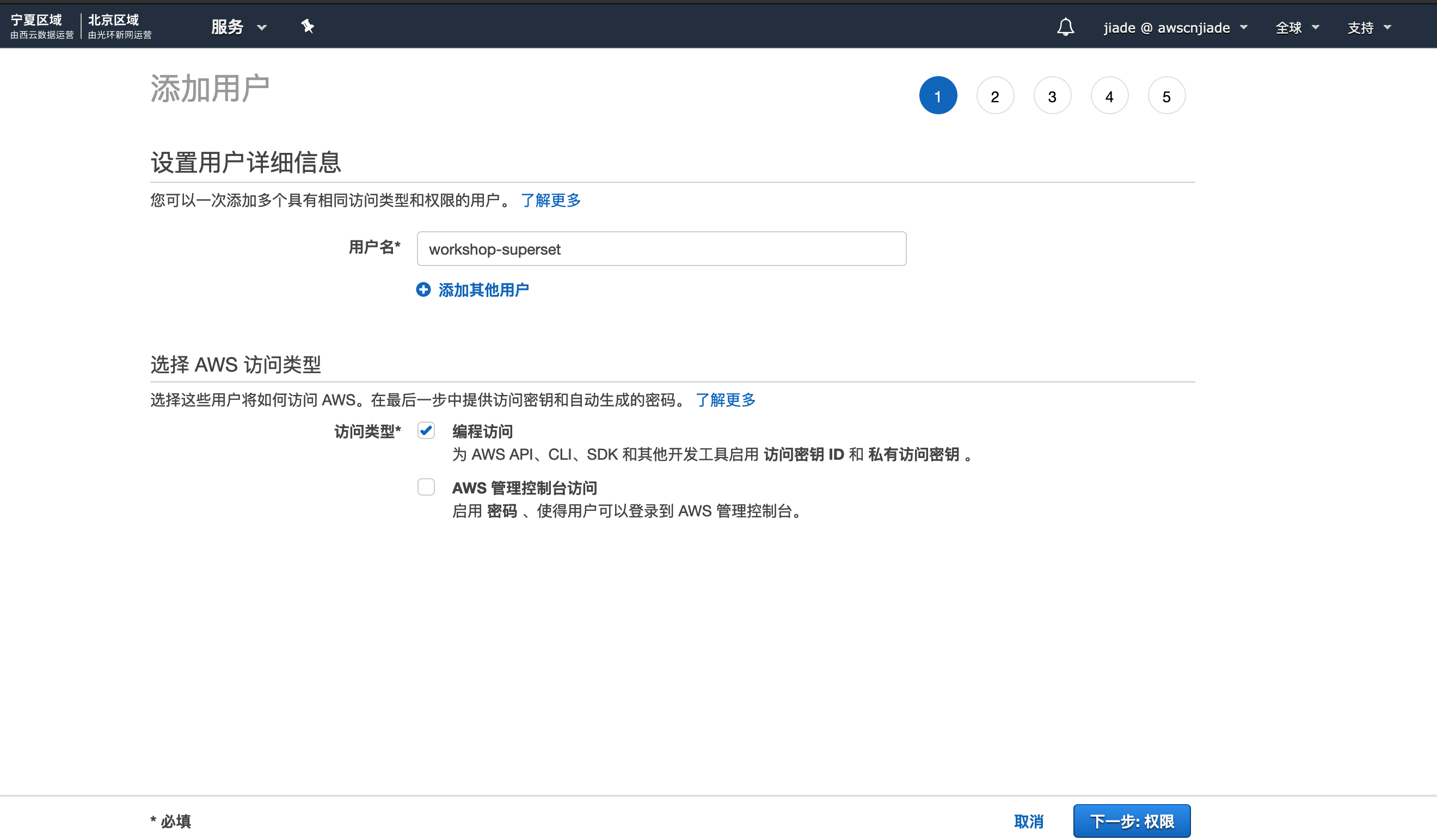
- 点击
用户,点击添加用户,随后填写用户名,例如workshop-superset,并在访问类型上点击编程访问,点击下一步
- 在添加策略页面,点击
直接附加现有策略,在筛选策略栏位,我们依次搜索并勾选以下3个策略:AWSGlueConsoleFullAccess,AmazonAthenaFullAccess,AmazonS3FullAccess,点击两次下一步至审核页面
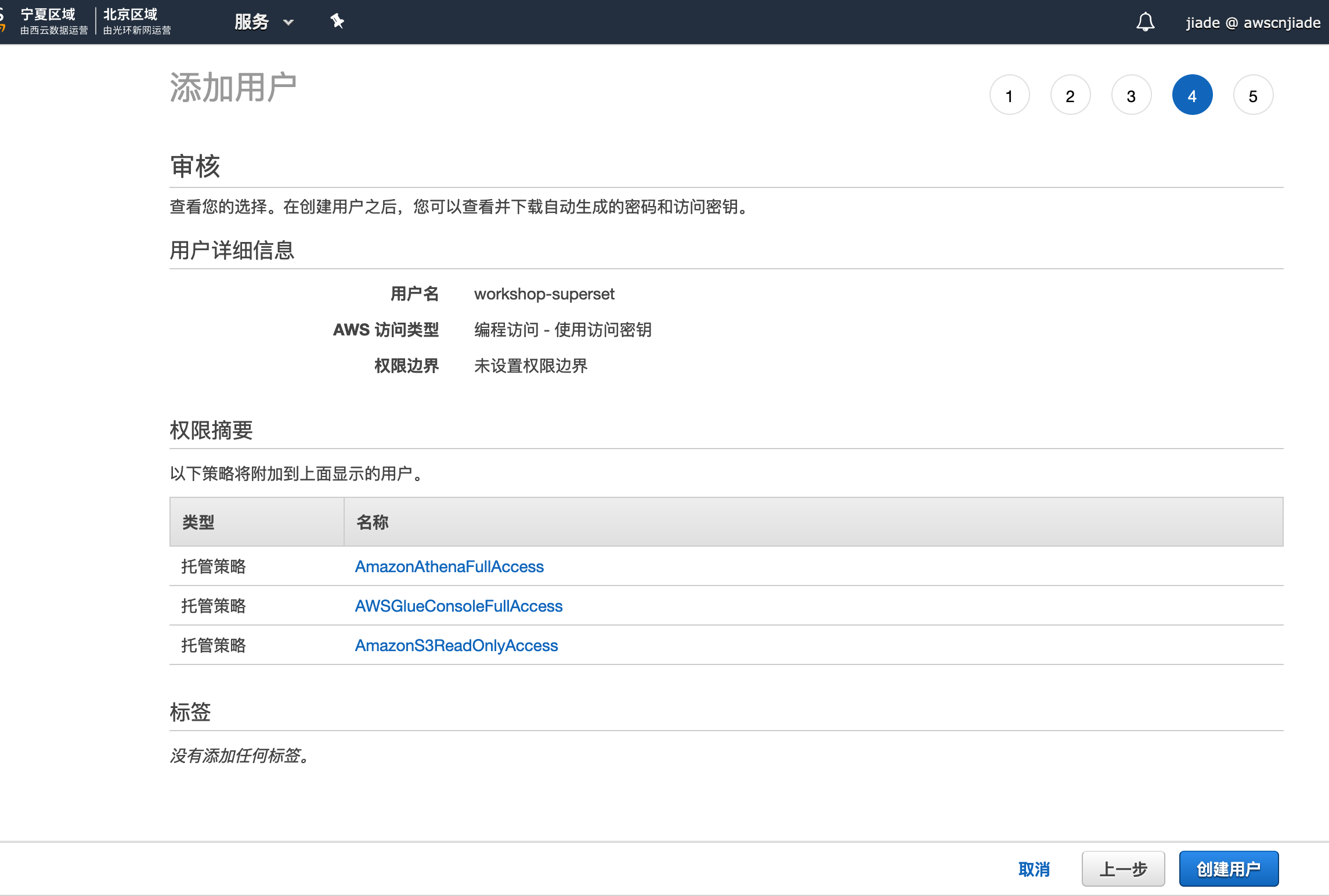
-
检查无误,点击
创建用户 -
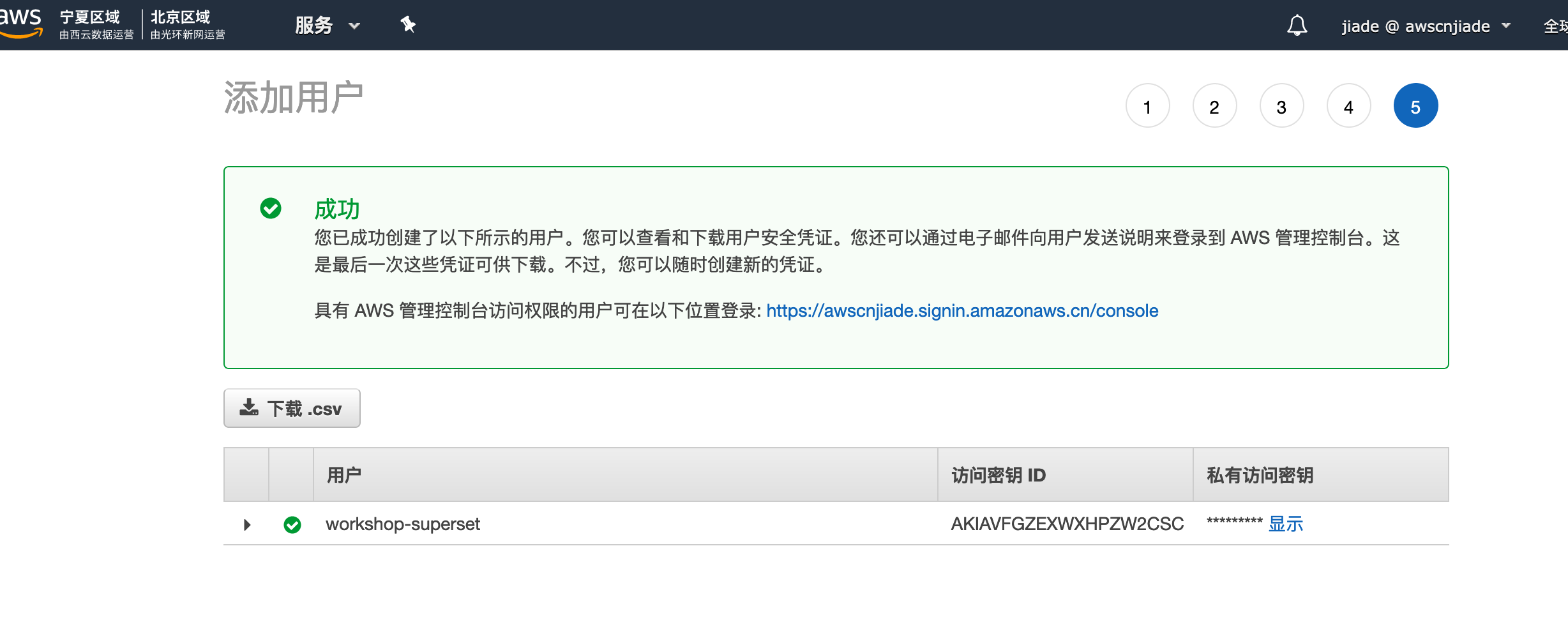
创建用户成功后将看见凭证获取页面,我们点击
下载CSV,或者点击访问秘钥栏位的显示,这将获取一会将赋予superset的 AKSK凭证,请保留这个页面或记录AKSK值备用
2,浏览器访问superset客户端http://localhost:8088,输入您刚刚自定义的用户名密码进行登录,例如admin/admin
3,来到superset控制台,现在配置连接Athena
点击Data,点击Database,进入到Database管理页面,点击右上角的加号进行数据库添加
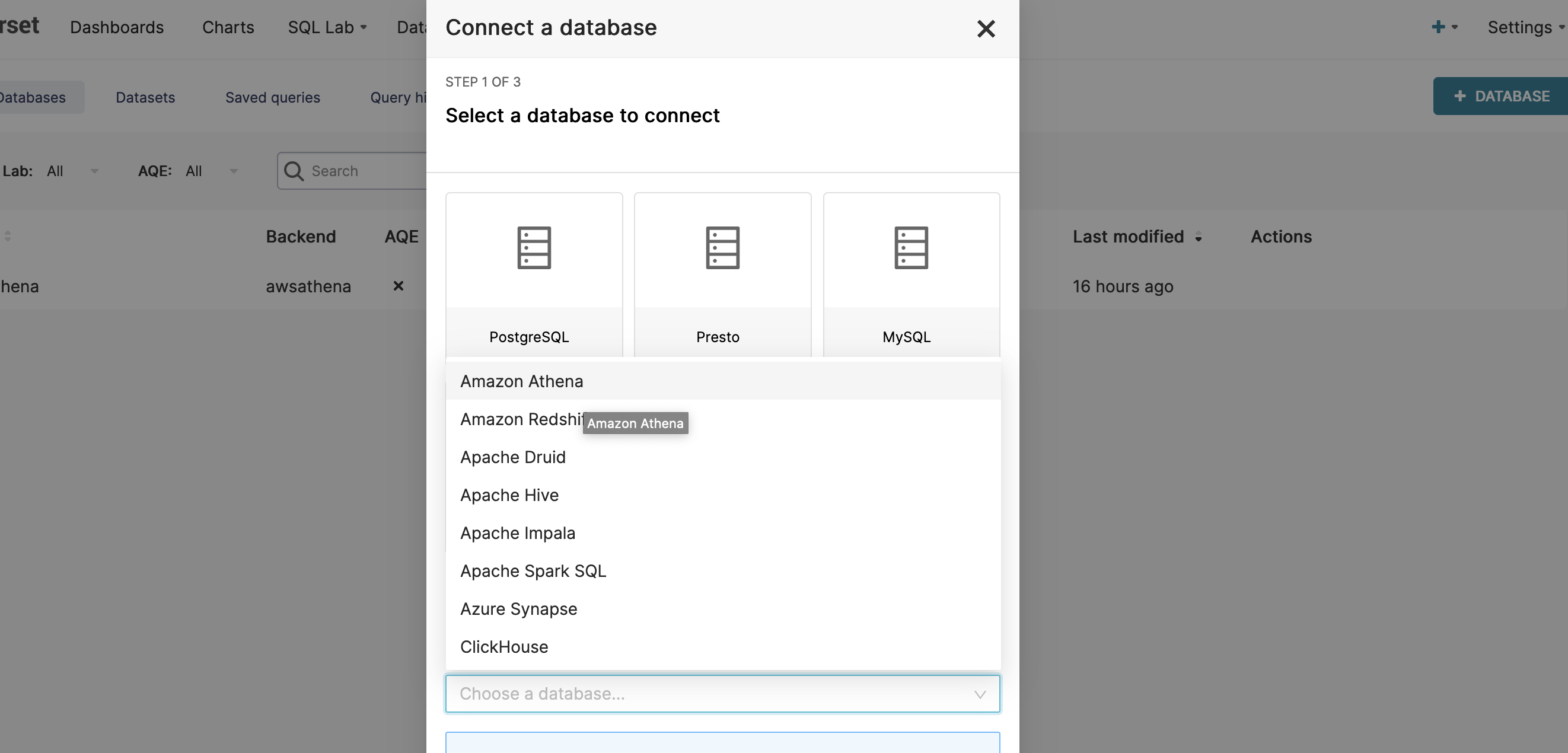
4,在添加数据库页面,需要填写Database名称,和SQLAlchemy URI,SQLAlchemy URI格式组成如下:
awsathena+rest://{aws_access_key_id}:{aws_secret_access_key}@athena.{region_name}.amazonaws.com.cn/{schema_name}?s3_staging_dir={s3_staging_dir}&…
{aws_access_key_id}:{aws_secret_access_key}是您刚刚创建的IAM ASSK{region_name}是你的Athena所在区域{schema_name}是你Glue中存放表元数据的数据库名称{s3_staging_dir}是你保存查询结果和记录的桶名称和路径(您可以填写Athena结果保存路径,或是创建一个新的桶路径填在这里)
例如最终拼接出中国区域的连接地址示例: awsathena+rest://AKIASJCHSJHN87DXD980:XXXXXXXXXX@athena.cn-northwest-1.amazonaws.com.cn/ml-data-lake?s3_staging_dir=s3://aws-athena-query-results-xx/
全球区域的连接地址示例: awsathena+rest://AKIAT2RQT5XMNQINWOG7:xxxxxxxxxx@athena.us-east-2.amazonaws.com/ml-data-lake?s3_staging_dir=s3://tmp-263168716248/athena-output/
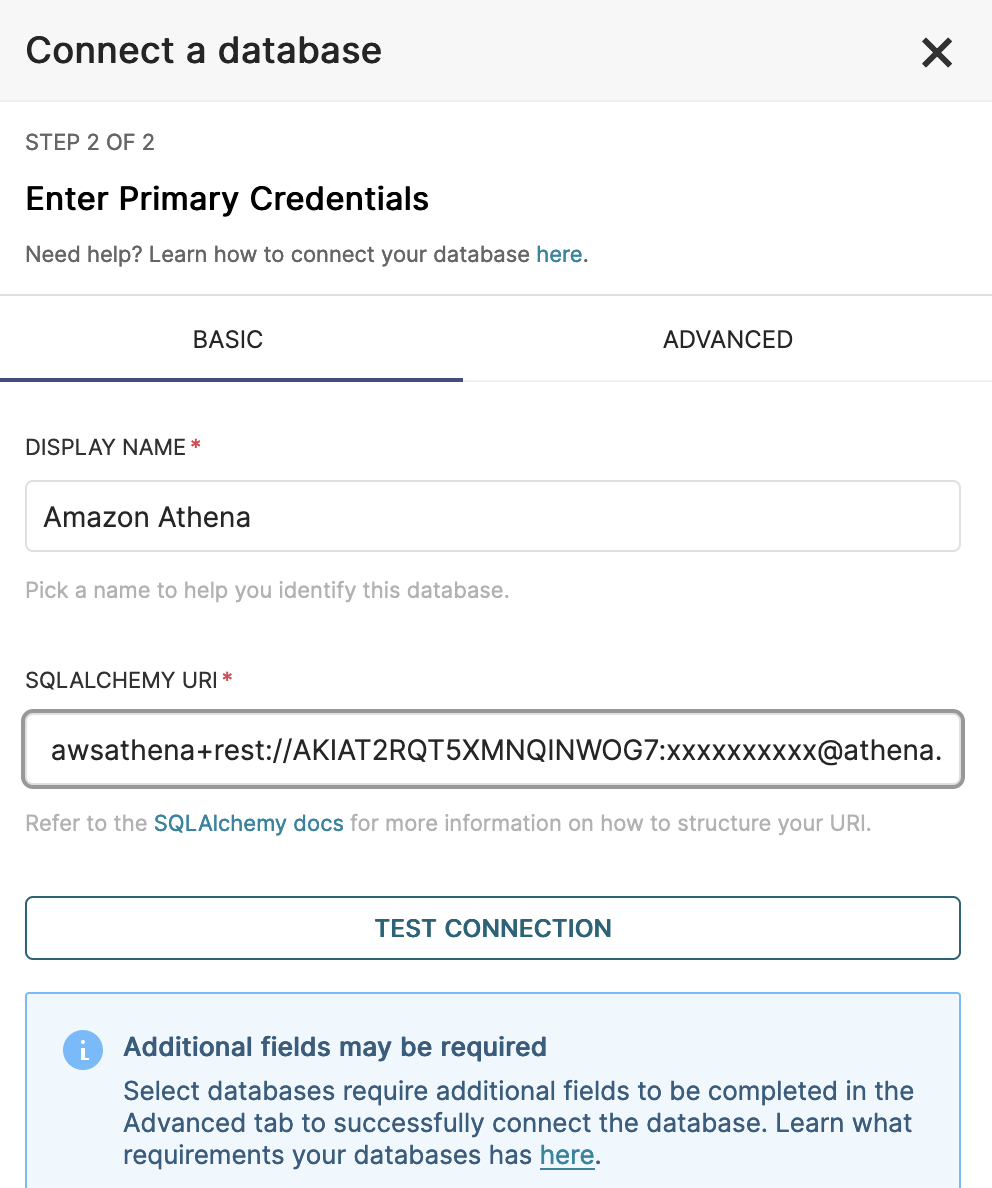
5,填写完后点击TEST CONNECTION测试连接可用性.其他项均可使用默认,点击创建以创建新的catalog连接。
Superset添加rating表
-
点击
Sources,点击Dataset,进入到Dataset管理页面,点击右上角的加号进行表添加 -
填写你的表名称,与Glue保持一致,例如
rating,点击SAVE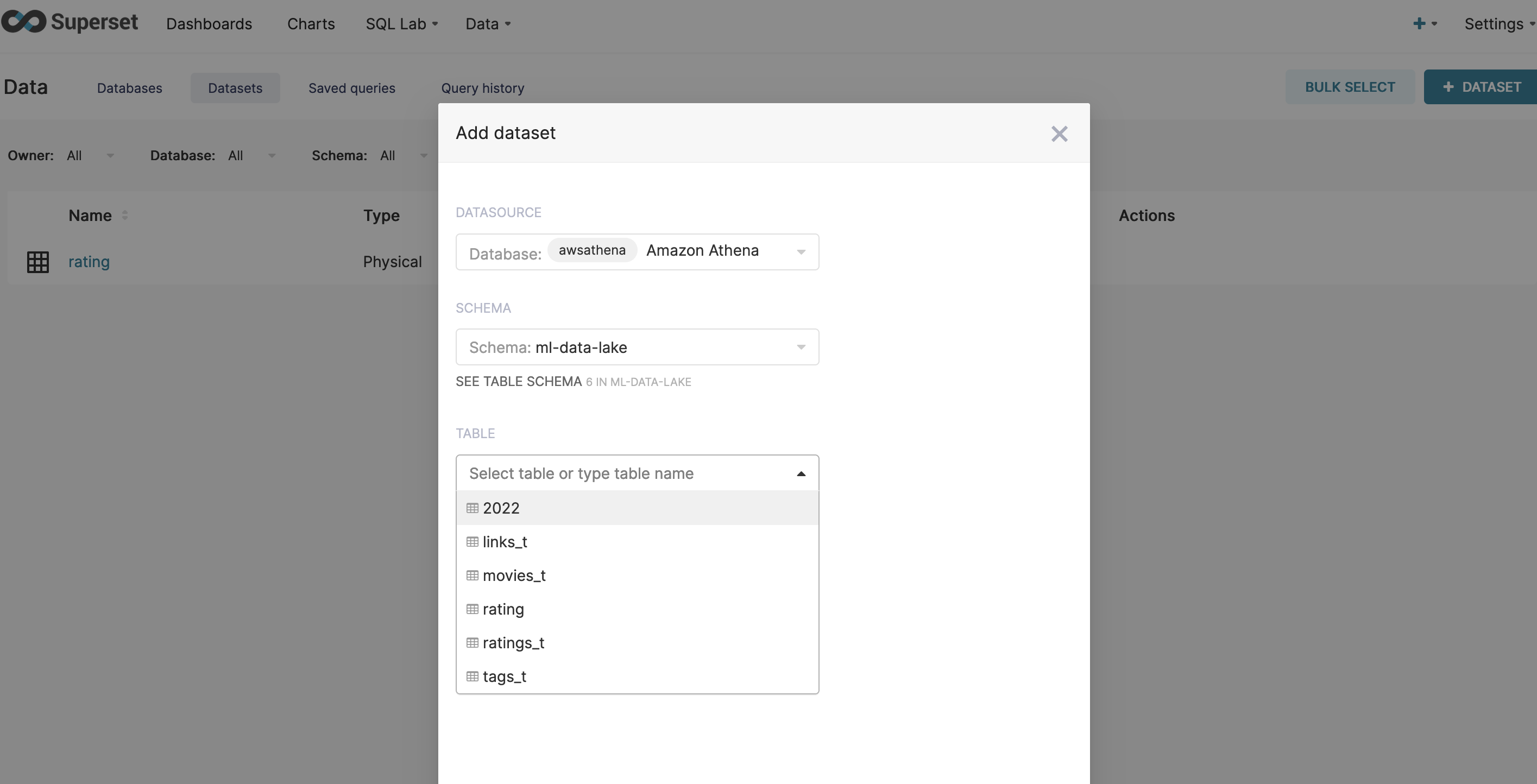
4,执行可视化查询
- 创建Charts,Charts是Superset中的数据可视化模块,您可以通过鼠标点选,聚焦在业务视野绘制不同的业务图表。有很多丰富流行的可视化模板供我们选择。
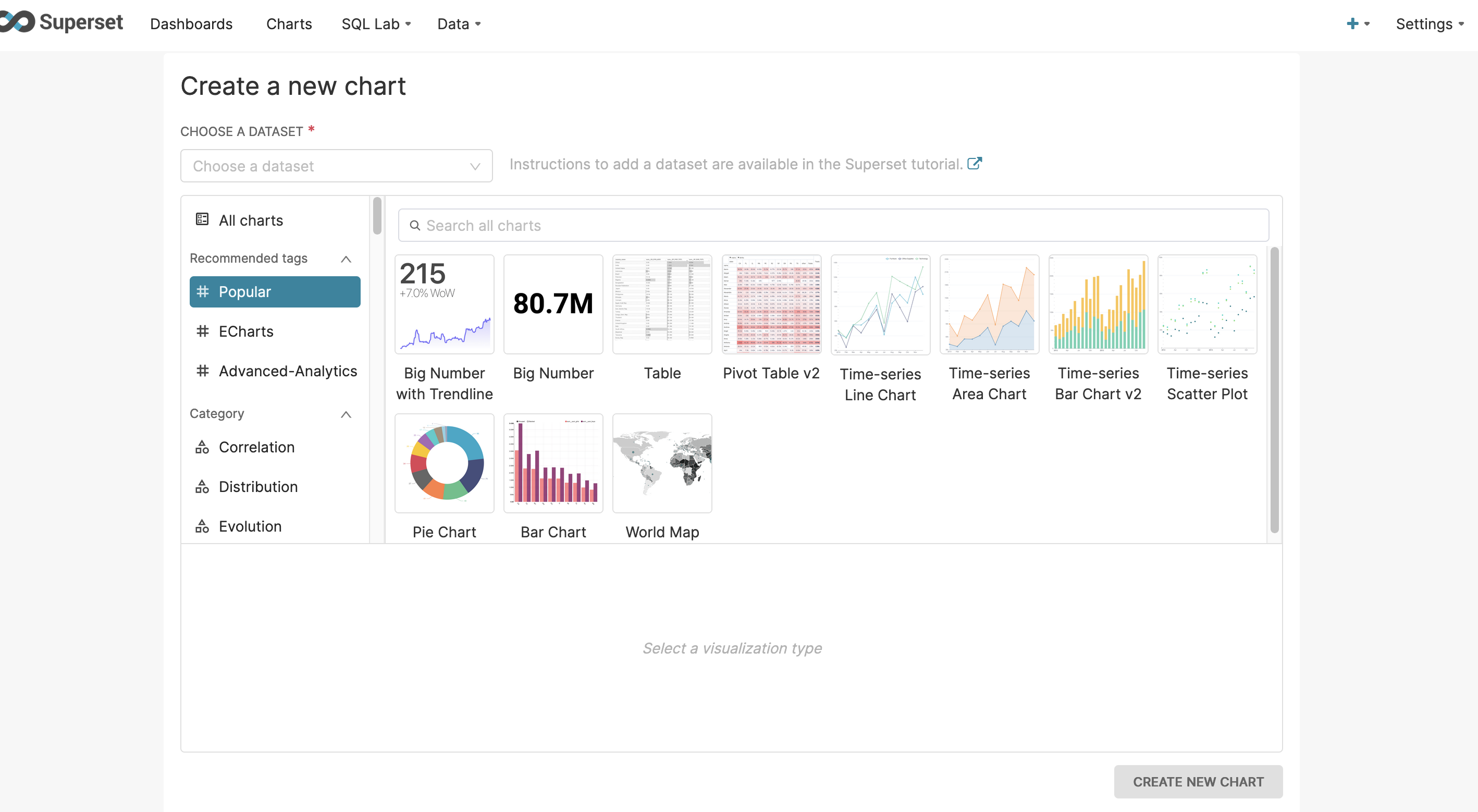
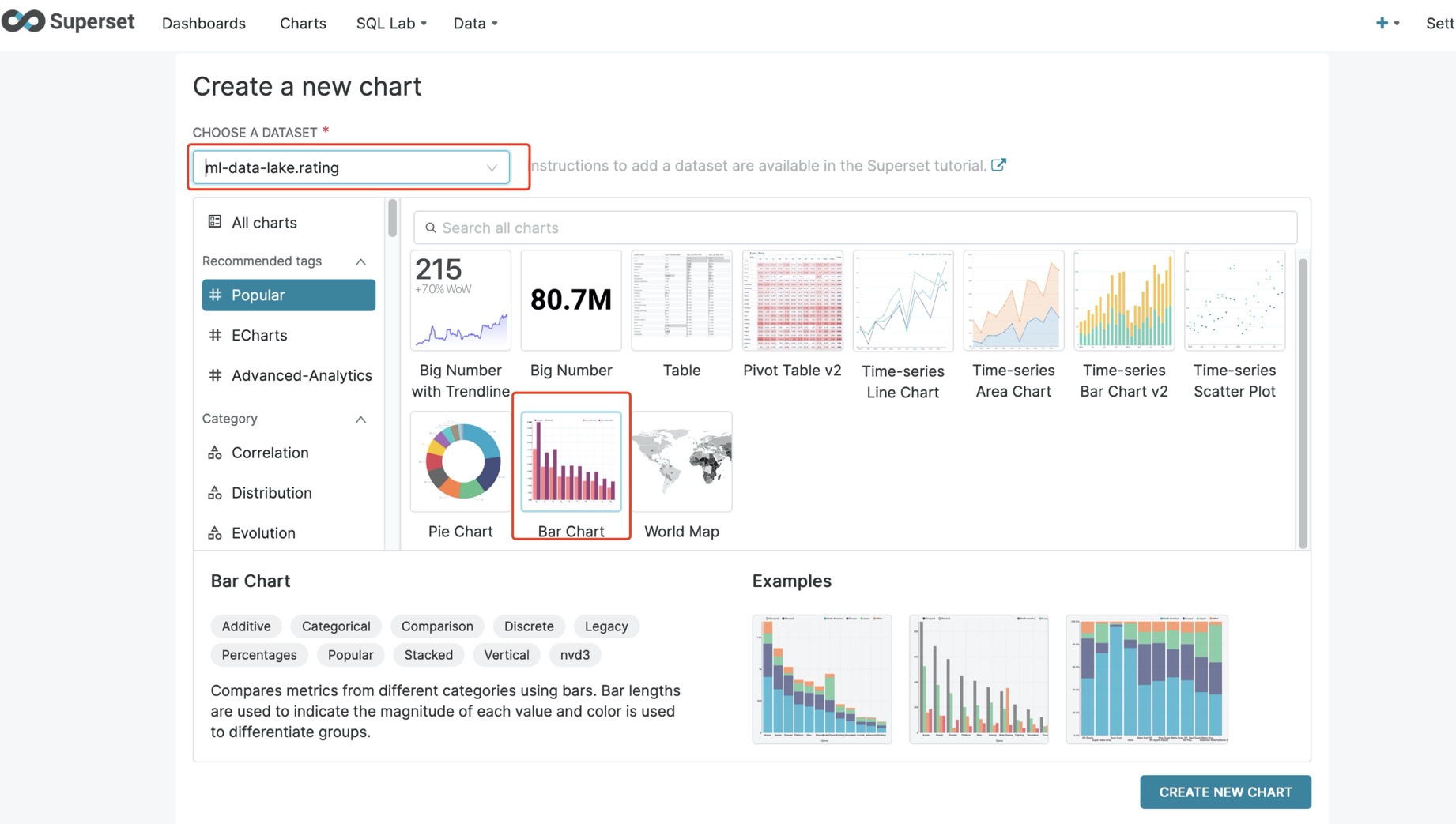
- 考虑当前
rating表的结构,4个字段分别是用户ID、电影ID、评分、时间戳.我们可以选择2位的柱状图已做实例。请选择我们刚刚添加的rating表和柱状图模板。
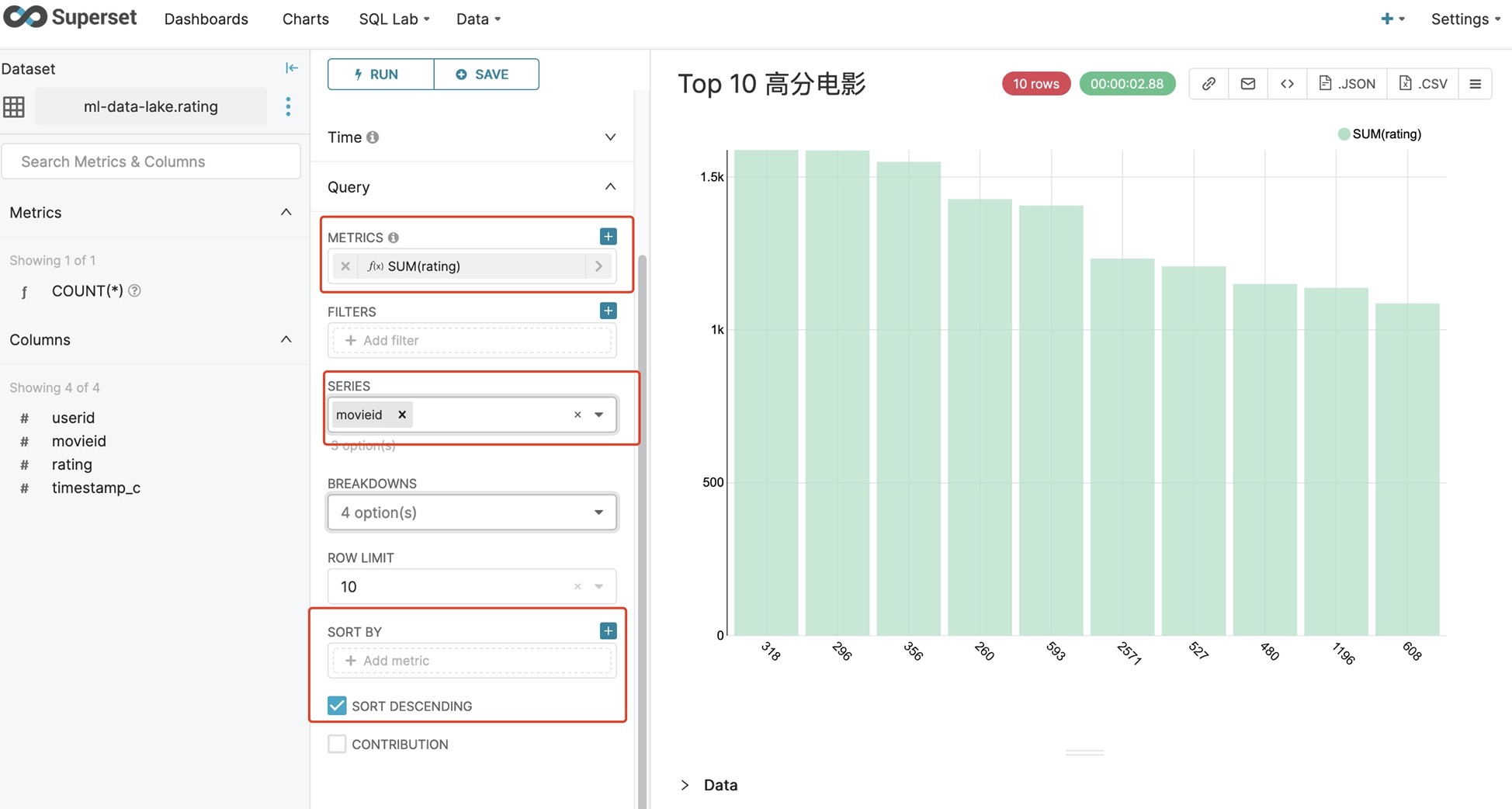
- 现在我们可以通过对表数据的理解进行各种数据探索,例如,以电影ID为展示单元,让各电影所获得的评分求和,得到正排序地得分最高的10部电影。
- 例如,以user ID为展示单元,计算最高对电影进行评价的用户是谁,他们通常打几分,这个分值打了多少次。这或许可以控制某些用户恶意的刷高或刷低某部电影。
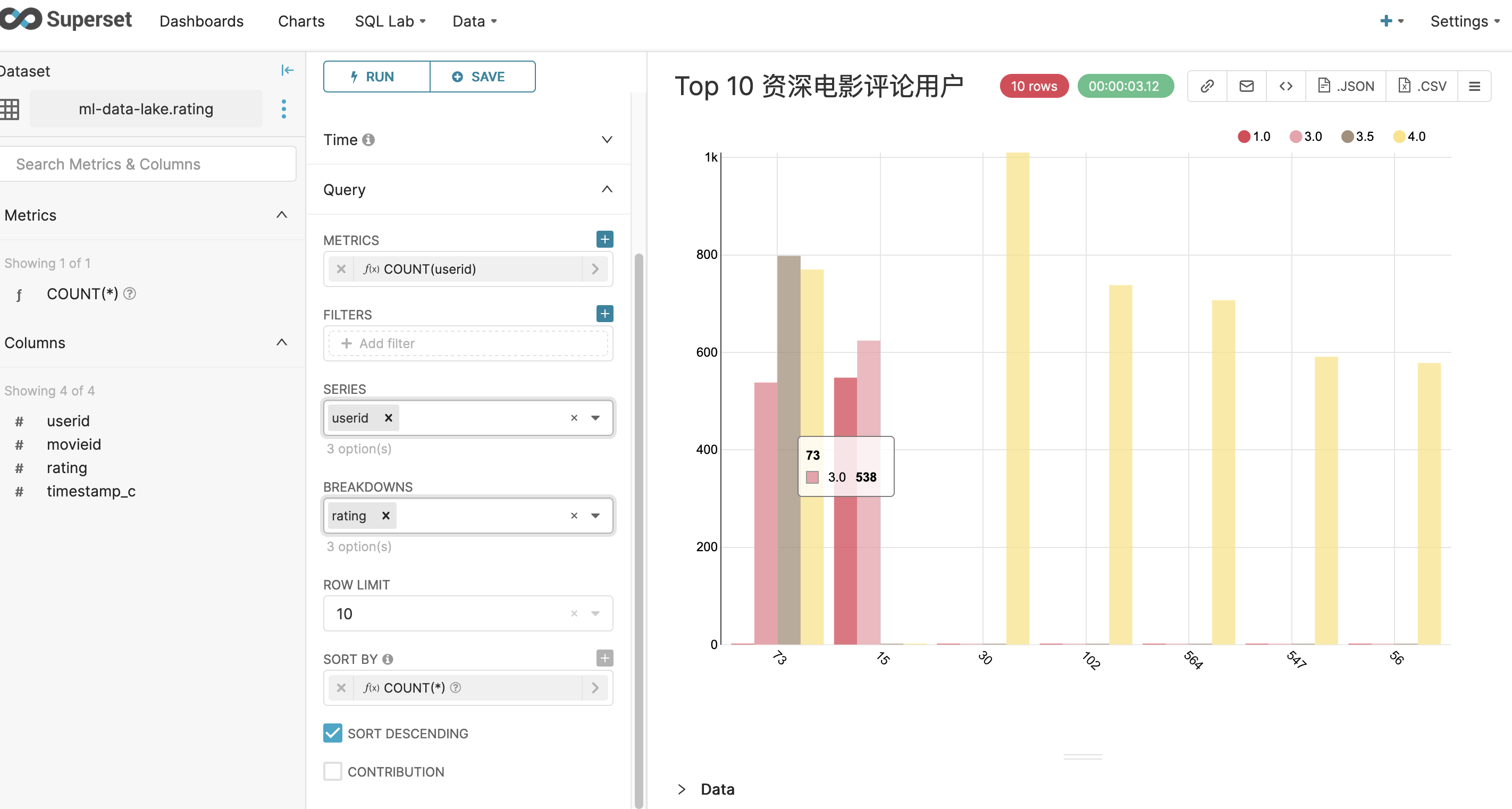
- 请您发挥您对业务的理解,在评分表内进行各种可视化查询分析
例如,Query里为Group by选择userid,在Metrics栏位为rating表选择COUNT,AVG,MAX,MIN,这样,您将可以看见全部用户进行了多少次电影评分,这么多次打分中平均分是多少,打出的最高分以及打出的最低分。
例如,Visualization Type 选择Pie Chart(饼图),Query里为Metrics栏位选择rating表的AVG,Group by选择movieid,Row limit选择10,这样,您将可以看见被点评打分次数最高的10部电影饼图分布。
依然使用饼图,你还可以在Query里为Metrics栏位选择rating表的COUNT,Group by选择movieid,Filters选择COUNT(rating) > 200,Row limit选择10,这样,您将可以打分次数高于200次的前10部电影,并且他们按平均分进行分布。
您还可以点击右上角的各种功能按钮,例如结果导出为JSON,CSV,查看SQL语句。查看SQL语句将反馈您锁点选的查询的SQL代码,您可以将它复制到Athena中运行,验证SQL结果。
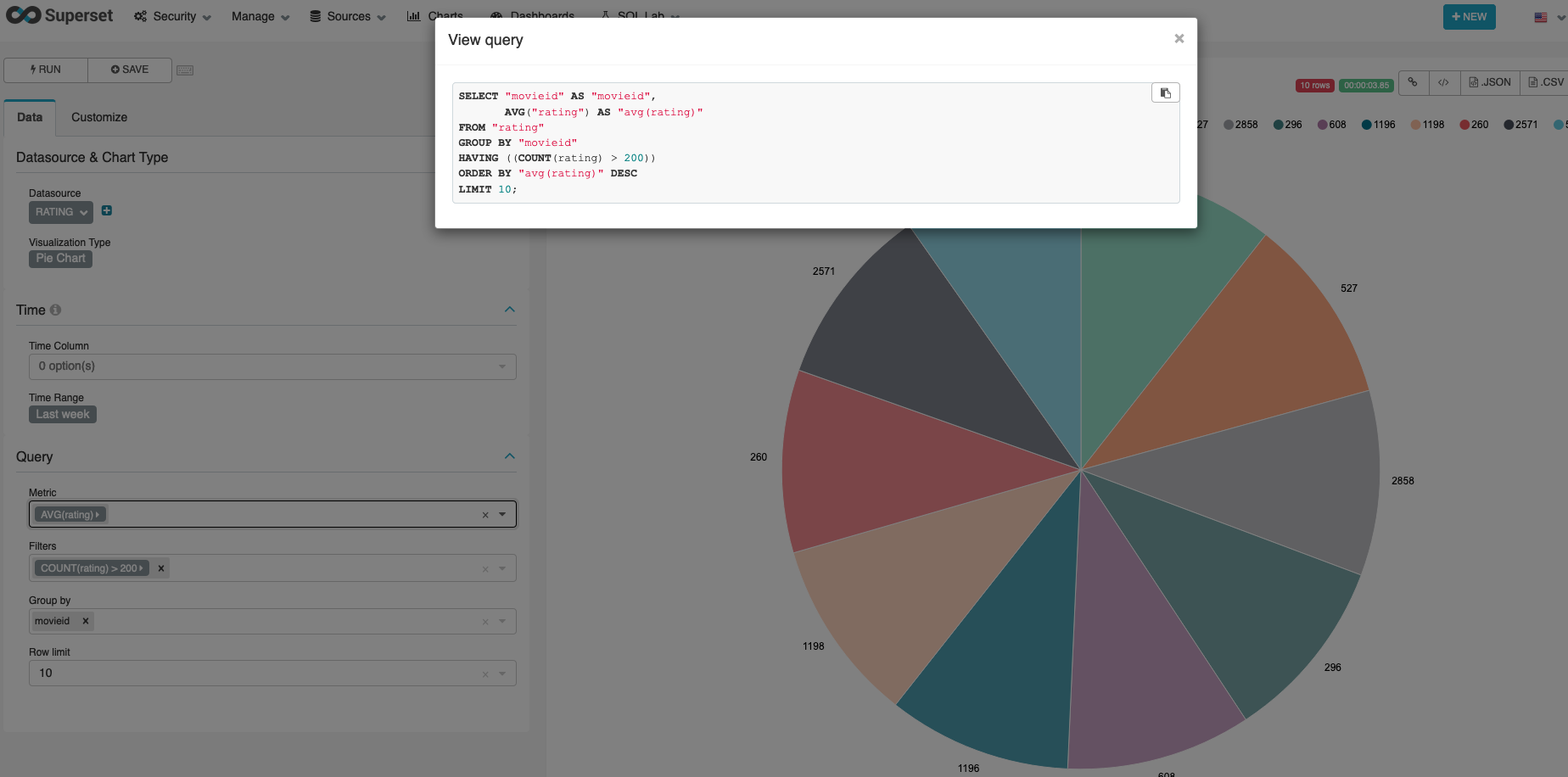
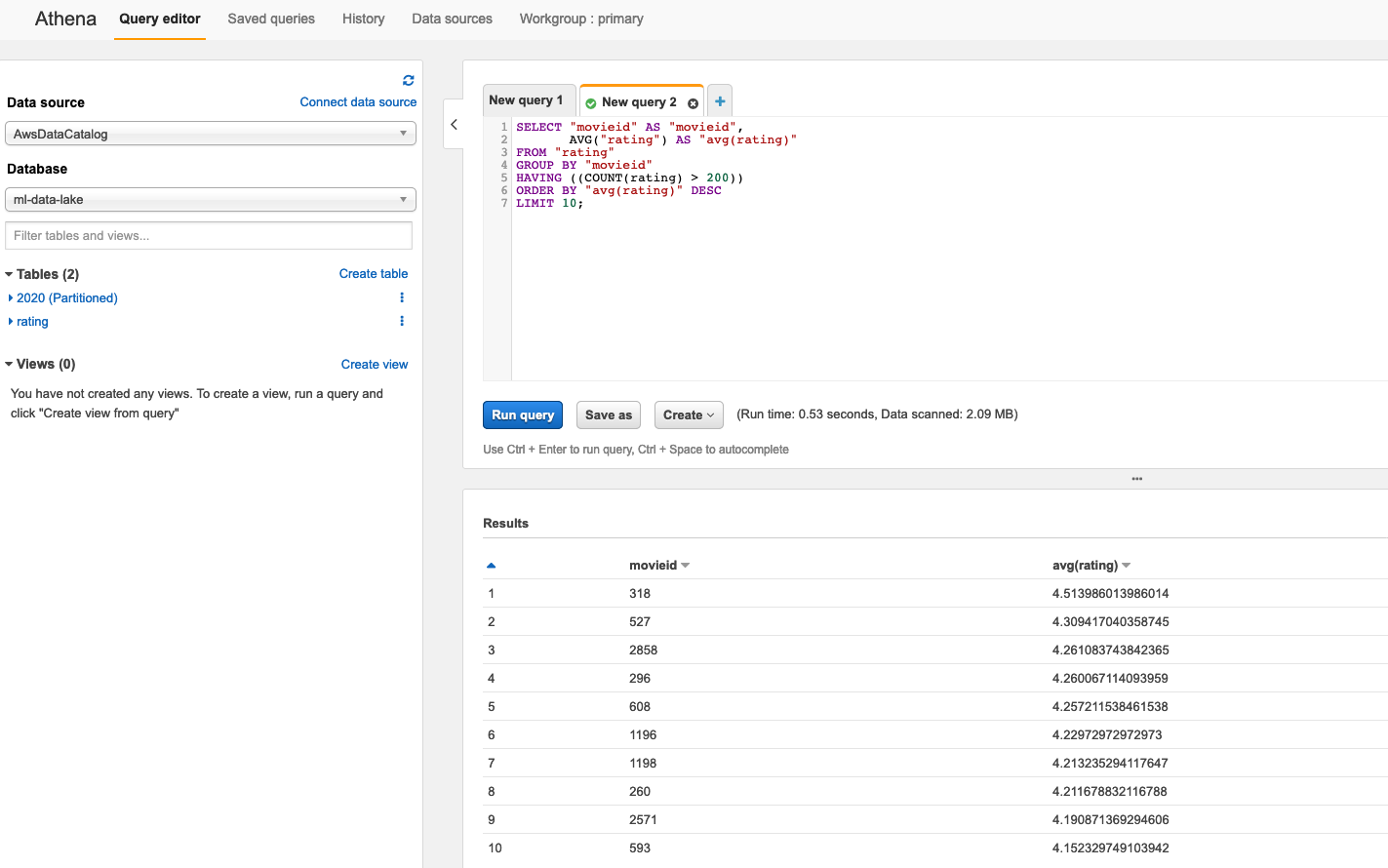
回到superset中,当您点击任意列名,排列将切换正序和倒序。或许您可以继续深挖,可视化出评分的平均分最高的电影ID,分析哪些用户为相同的电影打出了接近的分数等等操作。
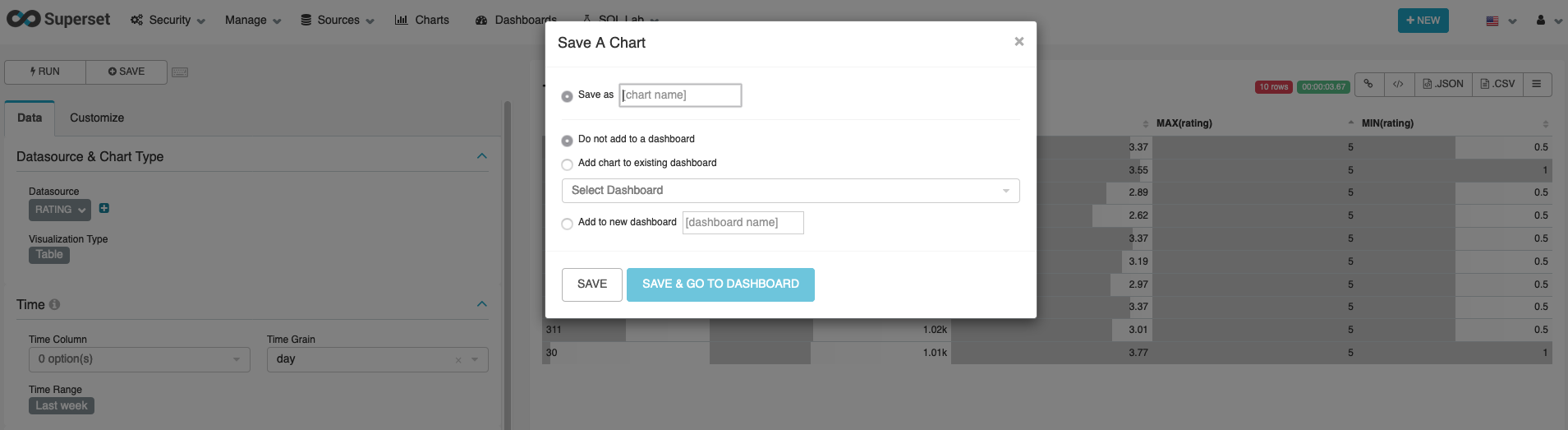
当您点击左上角SAVE将可以把您绘制的图标添加到指定的dashboard。
至此,我们完成了实验4。请您考虑:当我的业务有海量的存量数据,他们或许有空值,无效值,我们如果建立数仓分层,superset这类数据可视化工具应该去什么样的表格