实验2:Kinesis 接入实时数据流
使用 Kinesis 接入实时数据流
- 我们创建一个
lambda函数生成实时的数据,模拟真实业务中流式的数据想数据湖加载。lambda生成的数据将首先经过kinesis data stream,再经过kinesis dara Firehose,之后到达S3。
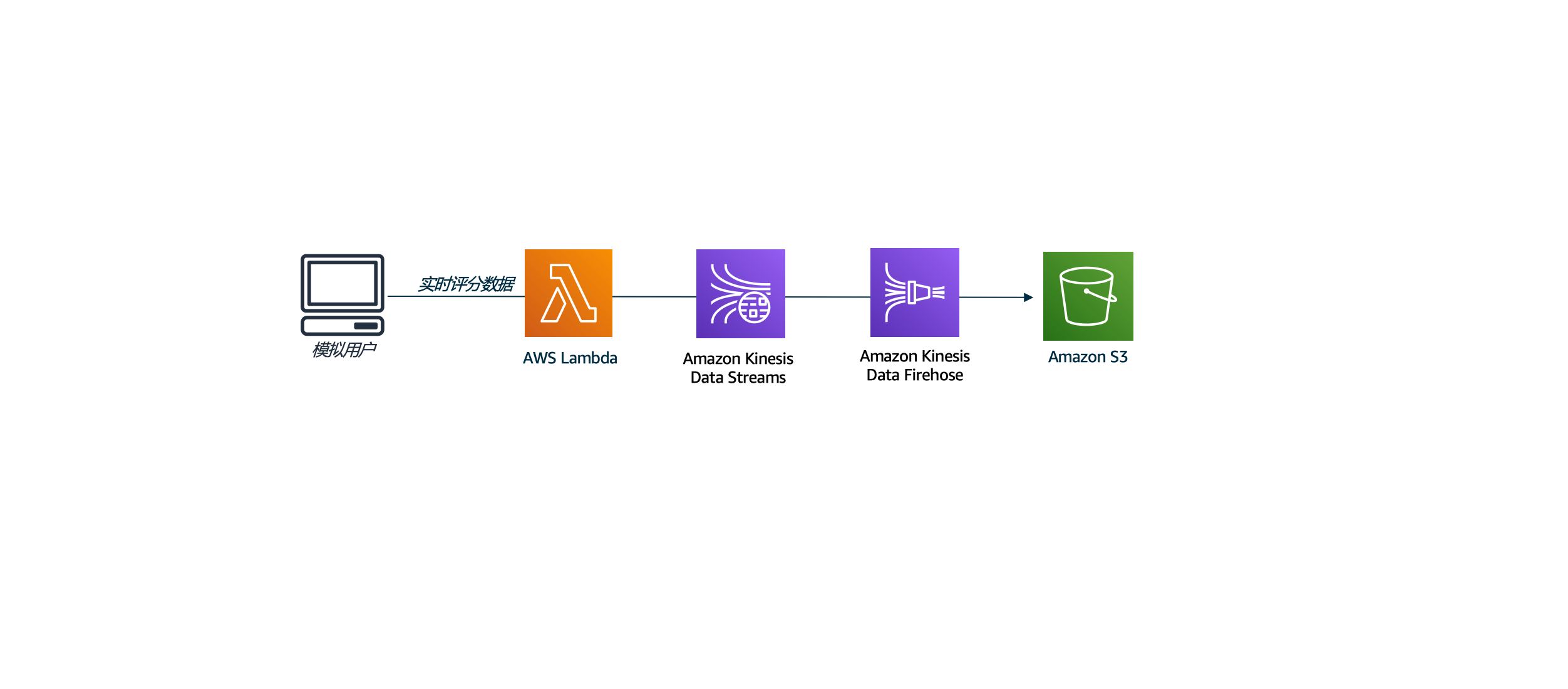 在本实验中,我们将设置Lambda函数,以将用户评分数据推送到Kinesis数据流中,然后使用Amazon Kinesis Firehose将数据导出到S3。
在本实验中,我们将设置Lambda函数,以将用户评分数据推送到Kinesis数据流中,然后使用Amazon Kinesis Firehose将数据导出到S3。
Lambda函数将模拟用户生成的实时电影收视率数据。 Amazon Kinesis使收集,处理和分析实时流式数据变得容易,因此您可以及时了解情况并快速对新信息做出反应。通过使用Kinesis,我们可以存储实时数据更新我们的机器学习模型。 Kinesis为其数据流支持多个使用者,因此可以设置另一个使用者来处理数据并将其存储到DynamoDB中。
1.创建Amazon Kinesis流
1.登录到AWS管理控制台。
2.在控制台的右上角,确保您位于所需的区域中(例如:宁夏)
3.从服务列表中单击Kinesis。您将到达 kinesis 控制台。
4.在Kinesis仪表板上,单击左侧面板上的 数据流,然后单击 创建数据流。如果您没有在面板上看到欢迎页面,请继续,然后单击“ 入门”。(当前kinesis的控制台可能已进行更新,您可能需要导航至数据流页面)
 5.对于Kinesis流名称,输入 你自定义的名字,例如
5.对于Kinesis流名称,输入 你自定义的名字,例如test_stream。为分区数输入 1。单击创建Kinesis流。该流将处于创建状态。等待信息流处于“活动”状态。(当前kinesis的控制台可能已进行更新,您可以查看新控制台的更多选择,并与导师讨论按需和预置的差异)
2.创建Amazon Kinesis Firehose流
1.登录到AWS管理控制台。
2.在控制台的右上角,确保您位于所需的区域中(例如:宁夏)
3.从服务列表中单击 Kinesis。(当前kinesis的控制台可能已进行更新,您可能需要导航至交付流页面)
4.在Kinesis仪表板上,单击左侧面板上的交付流,然后单击创建交付流。如果您没有在面板上看到欢迎页面,请继续,然后单击“ 入门”。
5.对于Delivery stream name,输入你自定义的名字,例如test_firehose。在“源”选项字段中,选择“ Kinesis数据流”,然后在“ Kinesis流”下拉列表中,在“目标”选项字段中选择S3。点击下一步
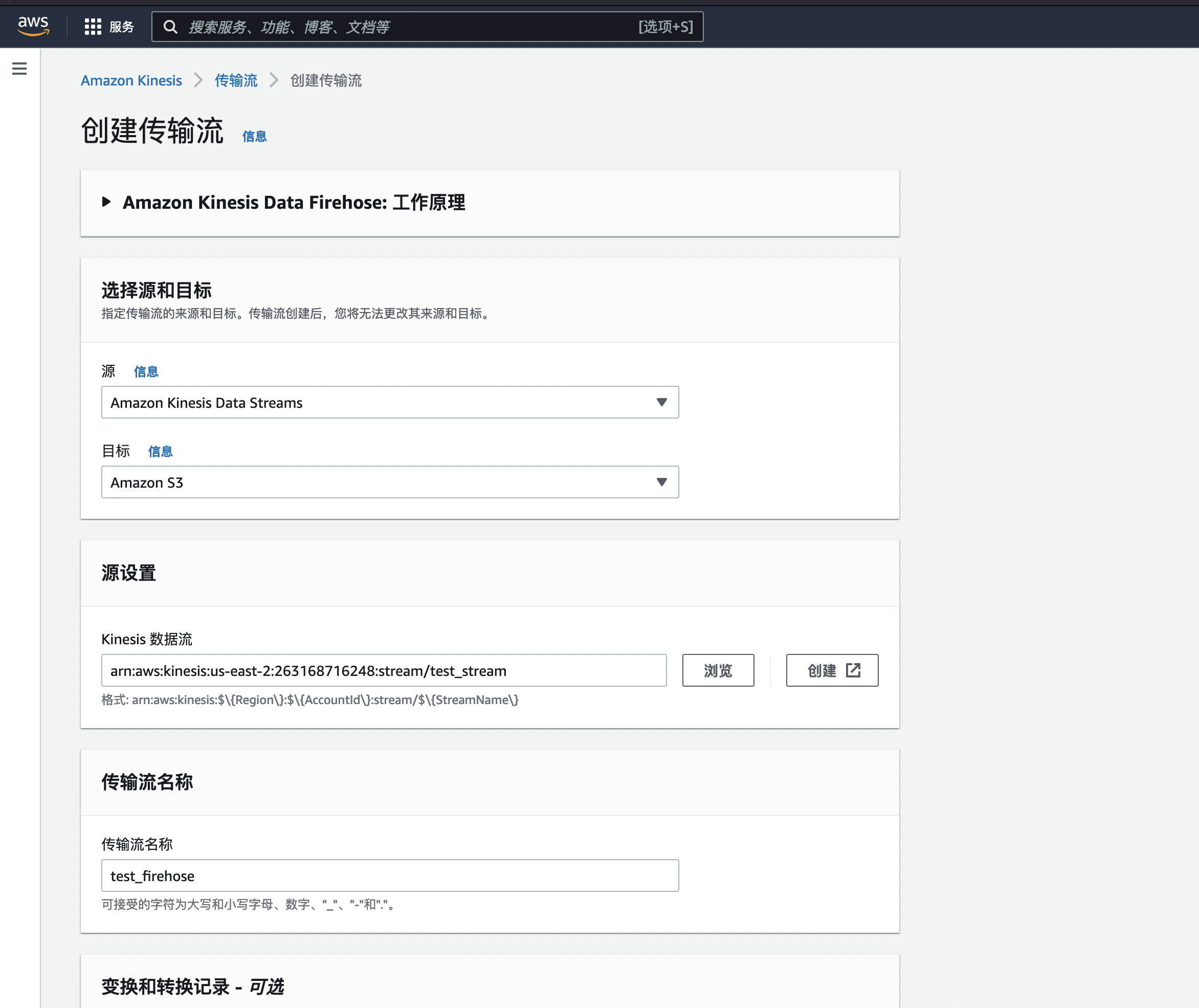
6.在“流程记录”页面中,选择“禁用”。请注意,Amazon Kinesis Firehose通过Lambda提供了在将源数据加载到目标数据源之前对其进行转换的功能。单击下一步。
7.选择Amazon S3作为目的地。对于S3存储桶,选择为您的实验1创建的存储桶。存储桶名称应为以partner-workshop结尾,以数字开头(aws帐户#)例如263168716248-partner-workshop。可选指定firehose作为前缀和错误前缀,然后单击下一步。
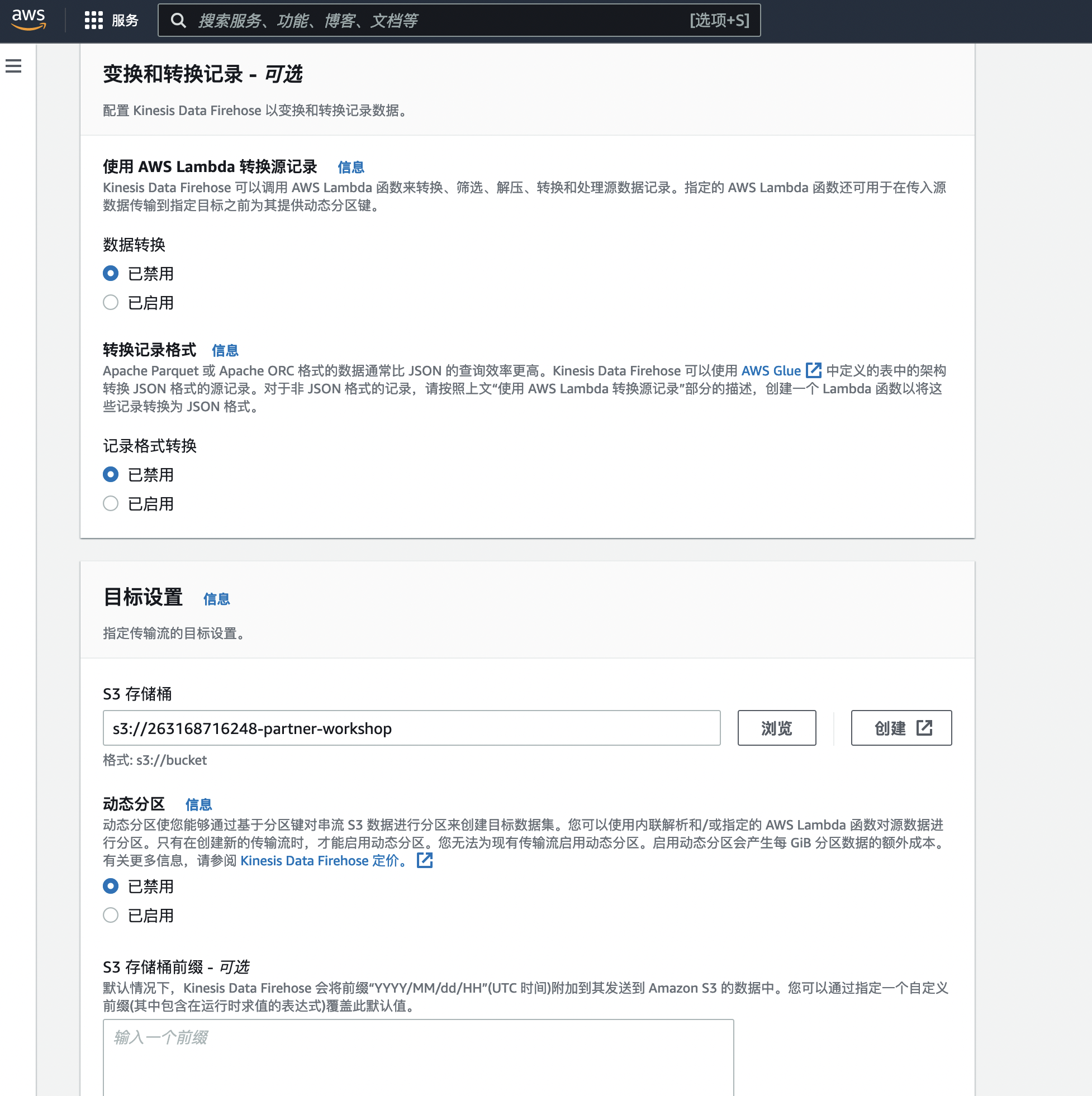
8.在“配置设置”上,提供了缓存区大小,缓存时间,压缩加密等选项,在生产环境中您可以按照需求进行配置,这里我们使用默认值进行实验,我们仅需赋予 Firehose 权限。
9.在“配置设置”上的权限栏位,选择创建一个新的IAM,然后单击“允许”。单击下一步,然后选择创建传送流
3.创建AWS Lambda函数以将数据加载到流中
1.登录到AWS管理控制台。
2.在AWS管理控制台的右上角,确认您位于所需的AWS地区(例如,宁夏)。
3.从所有服务列表中单击Lambda。这将带您进入AWS Lambda仪表板页面。
4.在Lambda仪表板上,单击“创建函数”
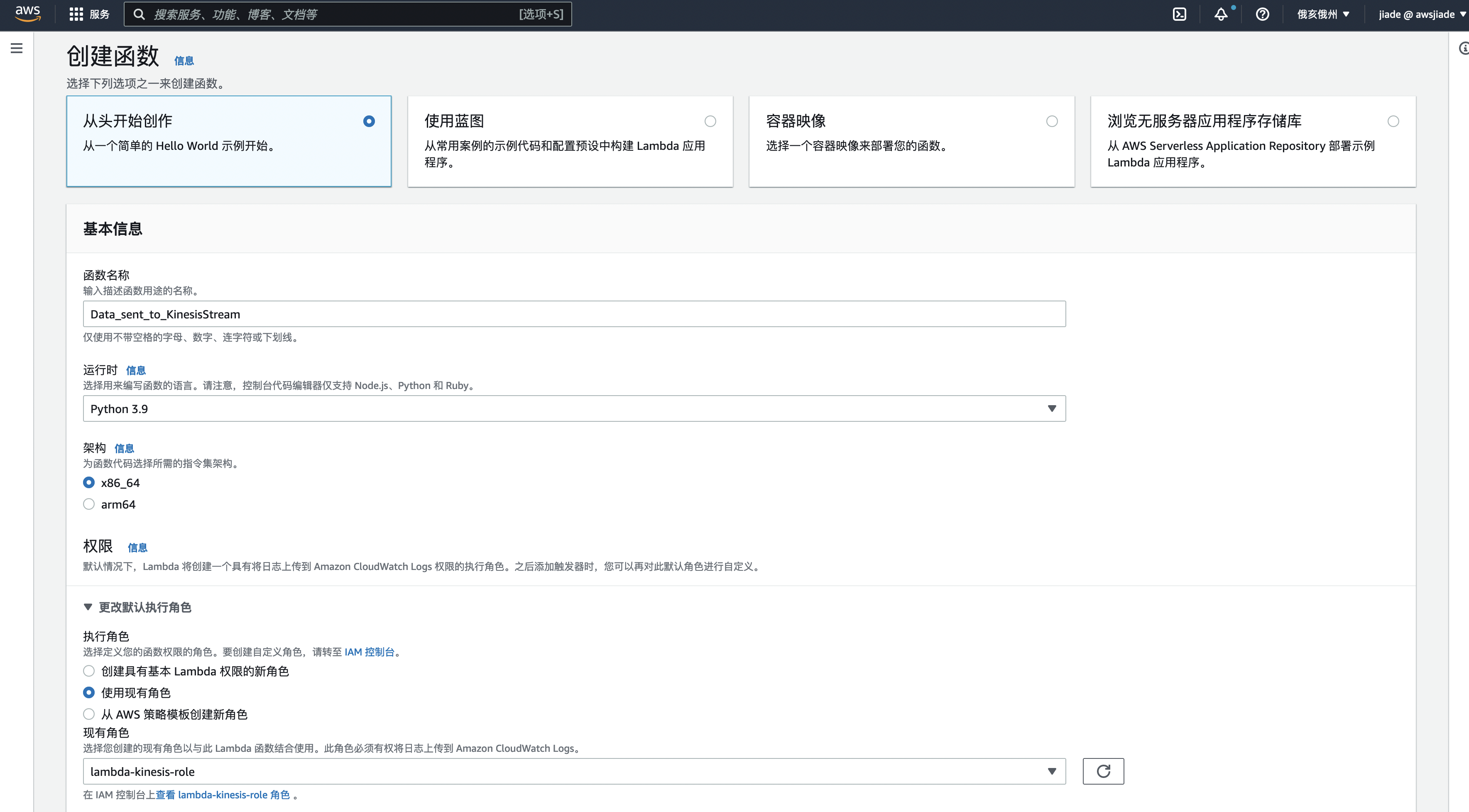
 5.从头开始创作,然后输入以下内容
5.从头开始创作,然后输入以下内容
函数名称: 你自定义的名称,例如`Data_sent_to_KinesisStream`
运行时: Python 3.9
执行角色: 选择一个现有角色
使用现有角色: 选择 lambda-kinesis-role
6.单击创建函数
7.在代码编辑器中,将以下代码复制并粘贴到该项目的lambda编辑框内,并进行修改。
import json
import datetime
import random
import boto3
import csv
import io
kinesis = boto3.client('kinesis', region_name='us-east-2') #<--- 调整 region 如果您不在 cn-northwest-1,例如调整为 us-east-2
def lambda_handler(event, context):
bigdataStreamName = "test_stream"#<--- 调整 StreamName 为您在之前实验中的Kinesis dataStream名字
s3 = boto3.client('s3')
response = s3.get_object(Bucket="xxxxxxxx-partner-workshop", Key="data/ratings-partial-load/ratings-partial-load.csv")#<--- 调整 Bucket 为您之前实验创建的桶名称,例如263168716248-partner-workshop
tsv = str(response['Body'].read().decode('UTF-8'))
lines = tsv.split("\n")
for line in tsv.split("\n"):
val = line.split(",")
data = json.dumps(getRating(val[0], val[1], val[2], val[3]))
kinesis.put_record(StreamName=bigdataStreamName, Data=data, PartitionKey="rating")
return "complete"
def getRating(userId, itemId, ratingId, timestamp):
data = {}
data['userid'] = userId
data['movieid'] = itemId
data['ratingid'] = ratingId
data['timestamp'] = timestamp
return data
8.对于常量bigdataStreamName,选择在第1节中创建的数据流的名称。还要验证客户端已初始化为您所在的区域,如代码中的region_name改为您实验的region,例如region_name=‘us-east-2’ 如下图参考,检查您的代码后请跳转到“配置”部分。
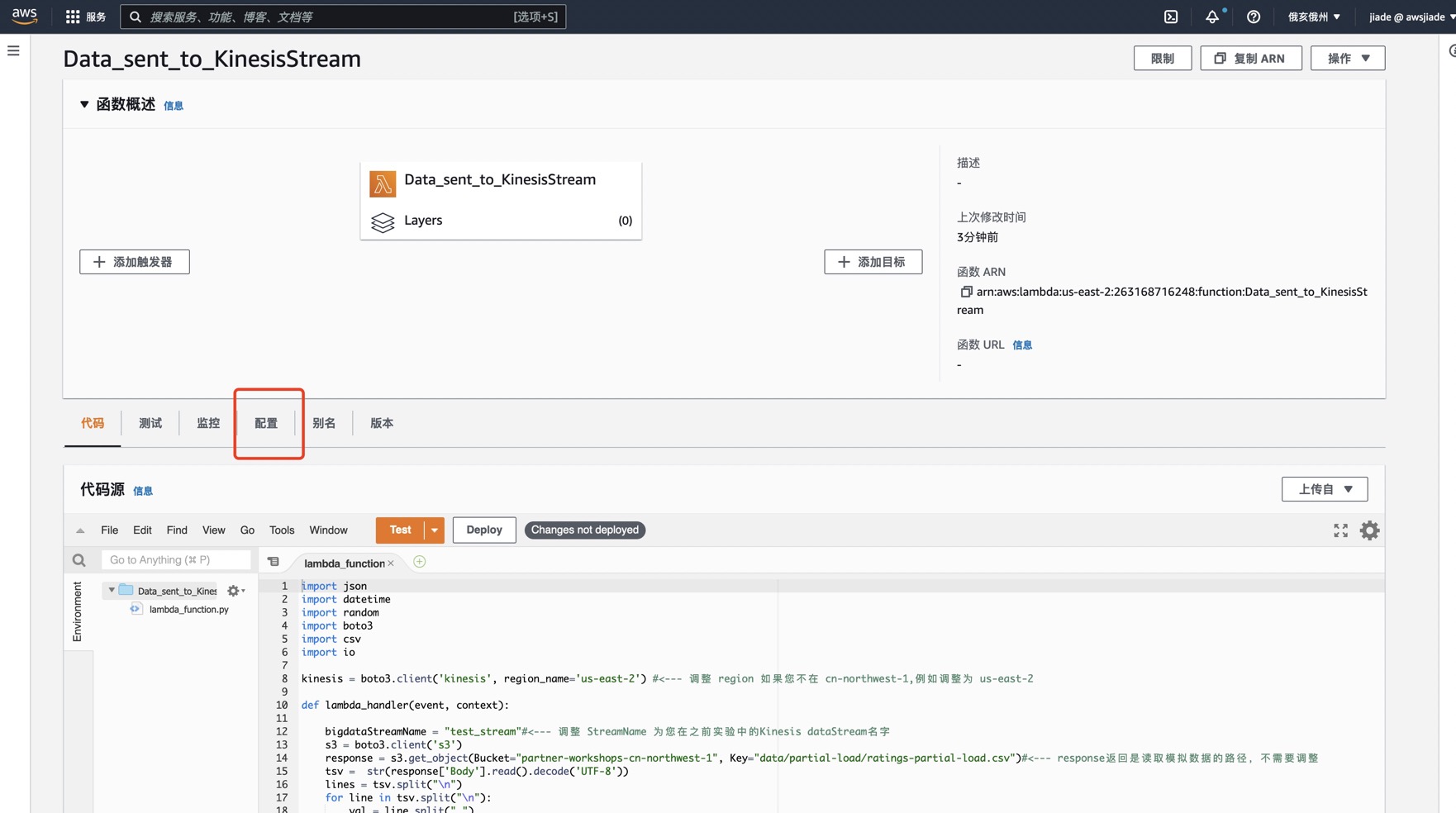
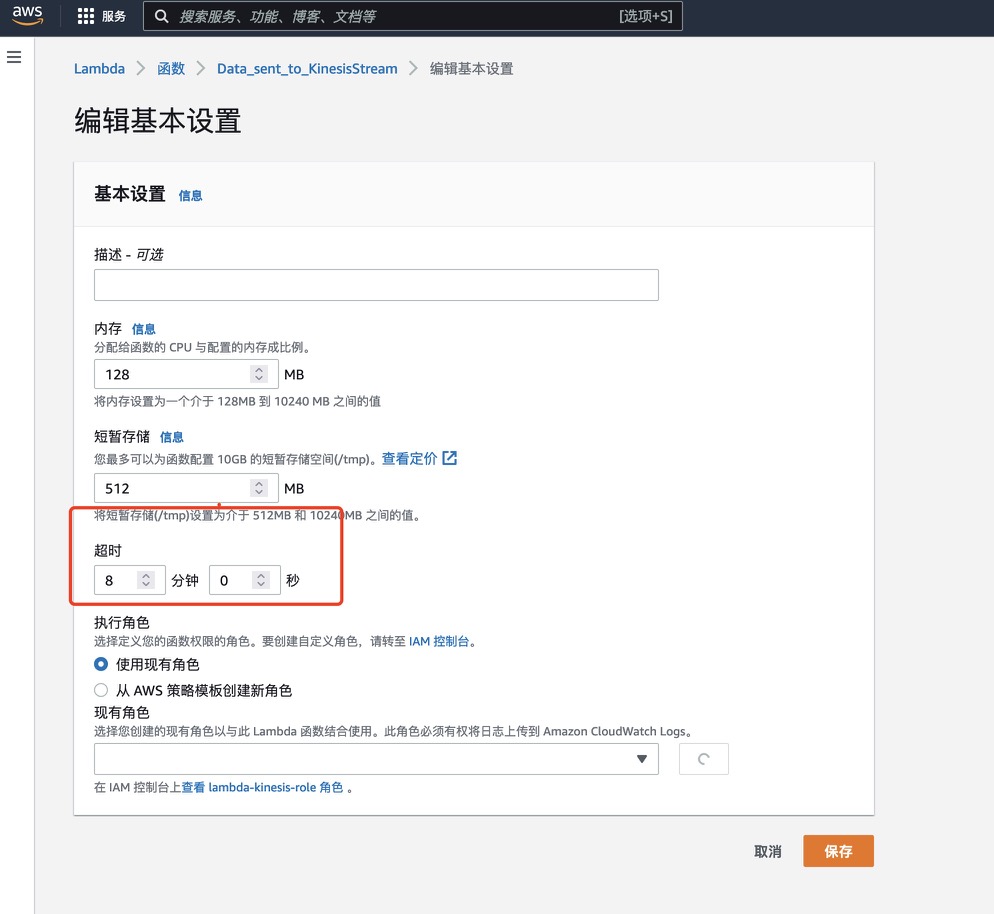
9.请在“配置”部分中找到“常规配置”,点击“超时”值以外的所有默认值。将其从3秒更改为8分钟,将其从128M内存更改为512M。如此在这段时间内,lambda会一直将数据连续的打到我们的kinesis数据流中
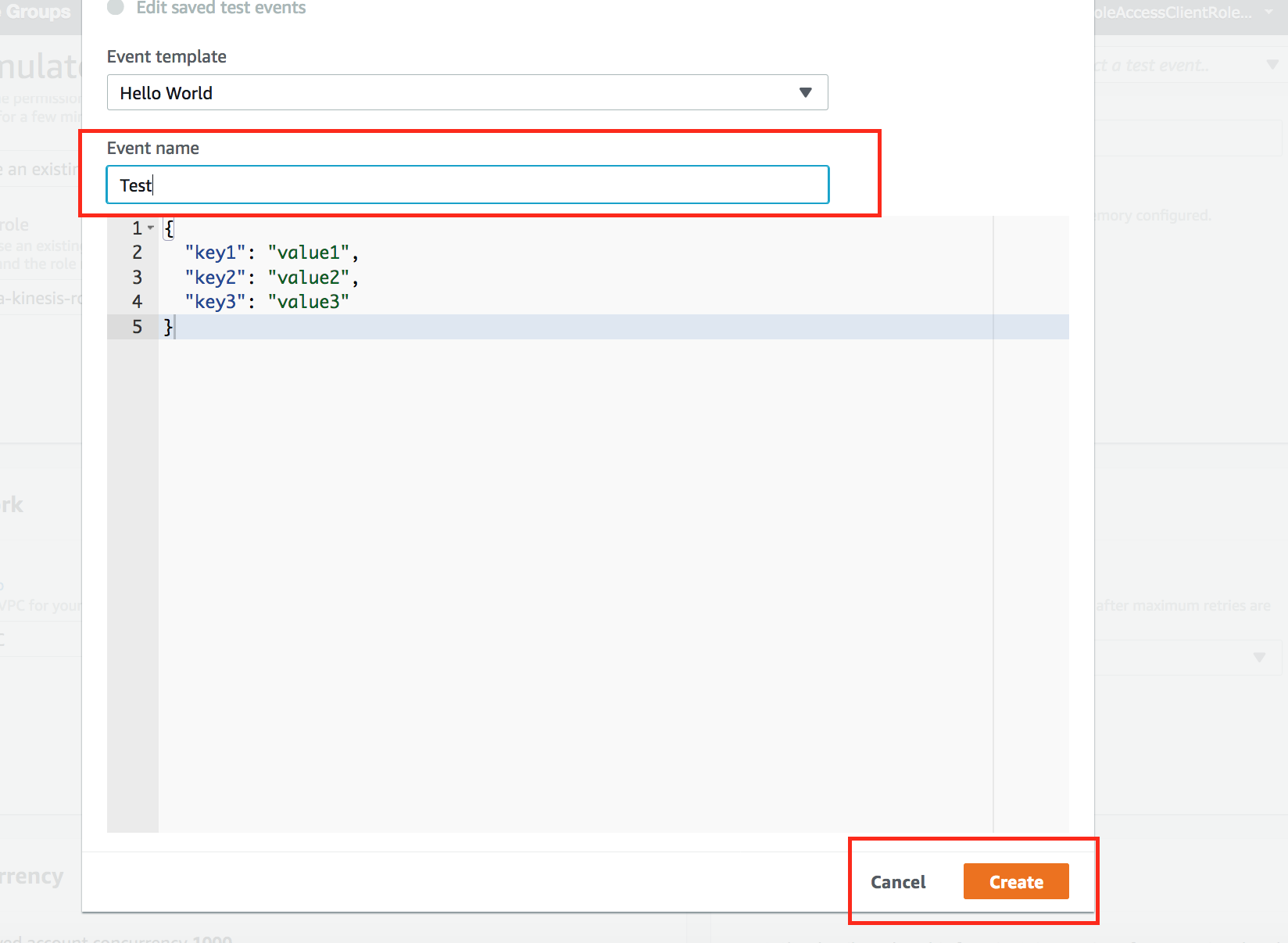
10.单击代码编辑框上面的"“Deploy"的将函数进行部署,然后单击“测试”。由于我们未提供任何参数或输入值,因此请保留所有默认设置,并为其命名为“ Test”,然后单击“创建”,单击“测试”。
11.该函数将运行8分钟,以将评分数据放入Kinesis流中。请注意,您可能会遇到超时错误,这是正常现象,因为该函数在可以推送所有记录之前已超时(8分钟),而在这8分钟内,我们不断的模拟了流式的数据输入,您也可以到kinesis data stream和kinesis data firehose的监控页面查看数据的流动。请继续下一步。
Ps,您可以查阅kinesis 两个API的差异(PutRecords 和 PutRecord)根据您的架构和当前代码的理解,讨论如果系统上线,流式海量数据打入系统会遇到什么瓶颈?有哪些调整空间?
12.到目前为止,我们有一个Kinesis流,并且我们已经创建了Lambda函数以将收视率记录放入流中。我们还设置了Kinesis Firehose来检索流中的数据并将其存储在S3存储桶中。要验证一切正常,请转到S3存储桶并验证数据文件是否存在。注意Kinesis Firehose将数据存储在年/月/日文件夹中。

现在请您思考并讨论:我们搭建的这套流式摄取数据管道有何利弊?