AWS上的数据分析
AWS上的数据分析
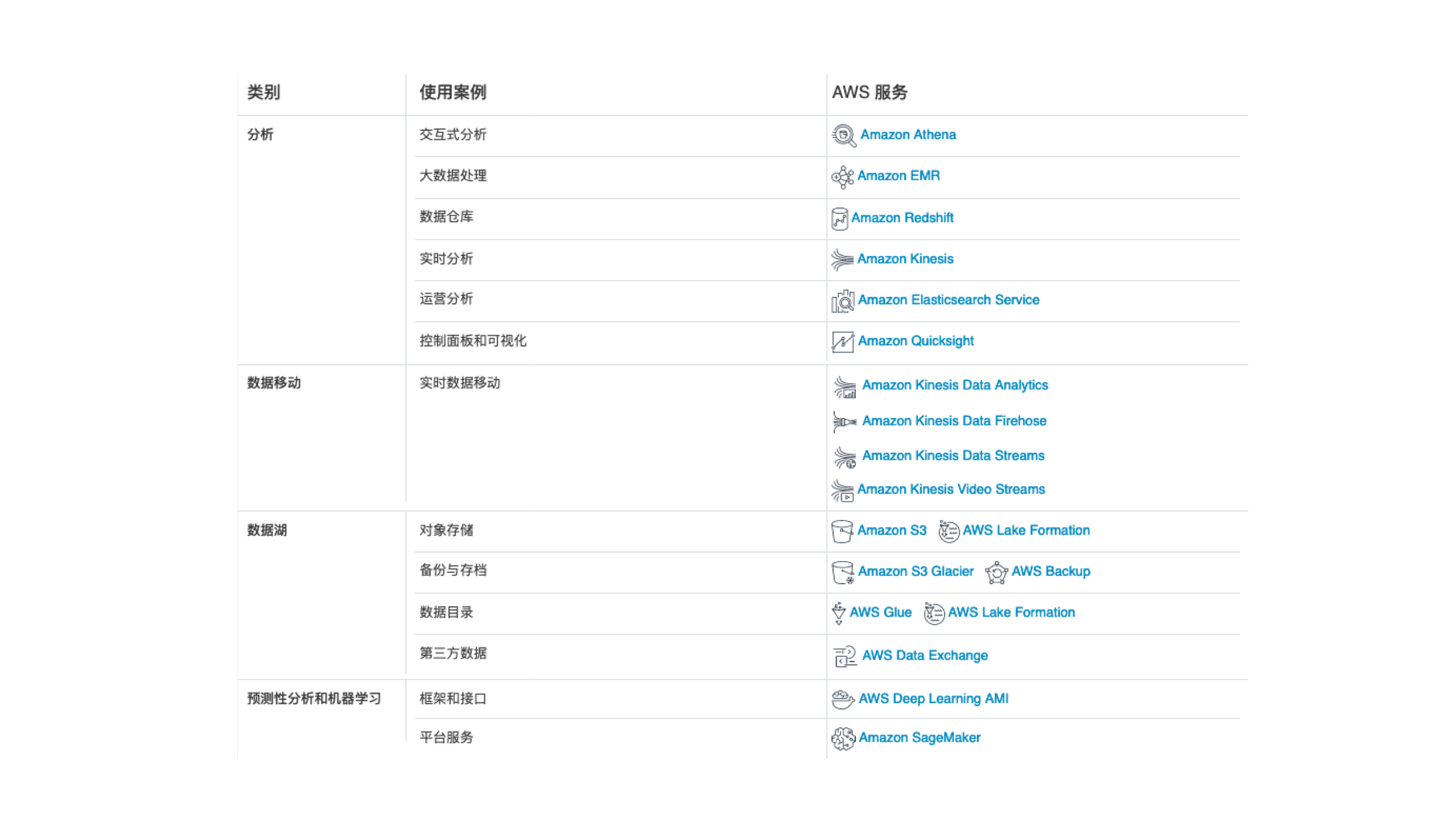
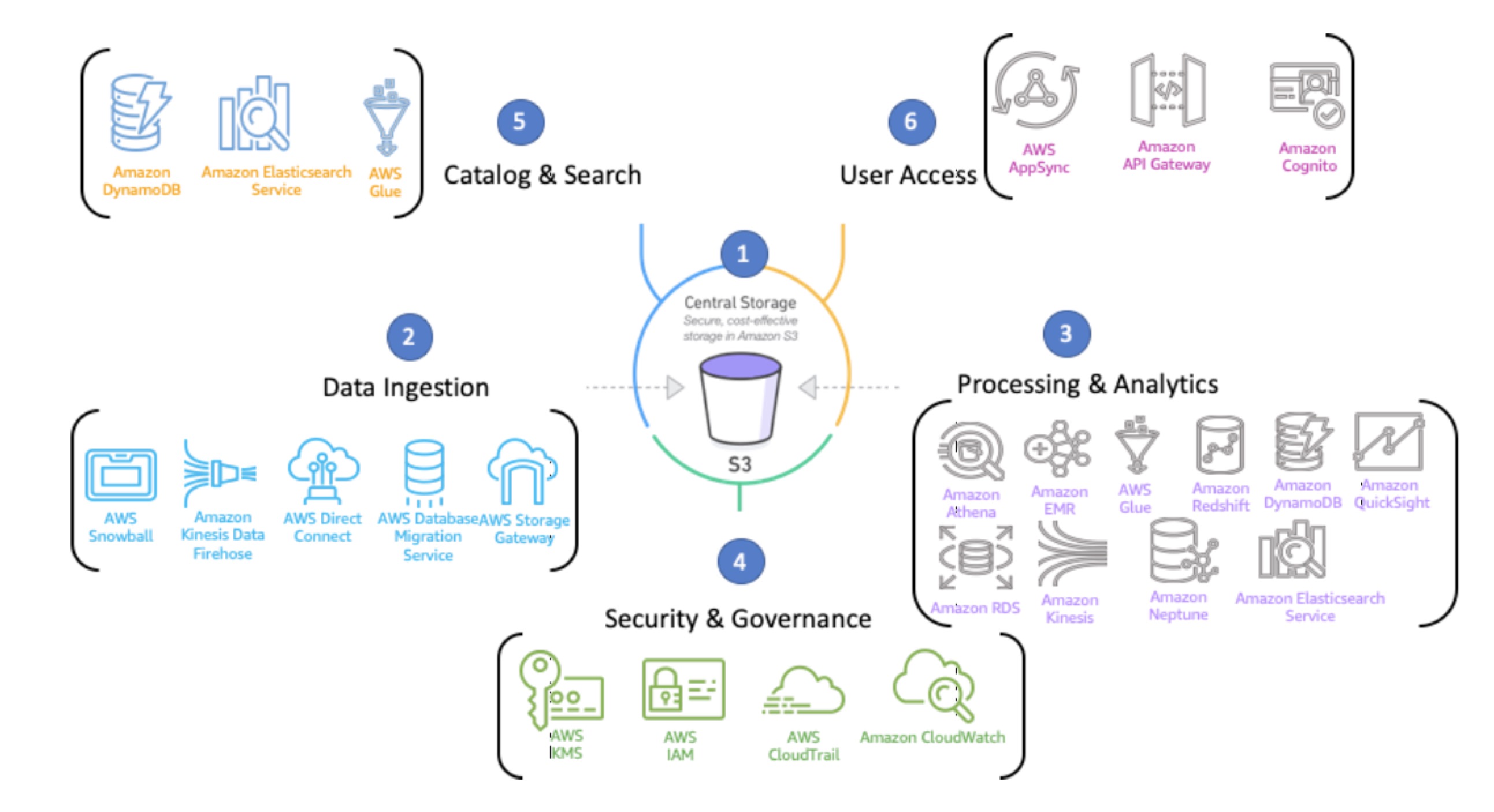
在数据库和分析方面,AWS提供了最广泛和最深入的云服务集。以下是从6个层级划分的数据分析架构中的服务组件:
-
1–数据湖和数据存储:
-
Amazon S3是AWS上的数据湖核心。Amazon S3能够支持ETL处理与分析环境所创建并使用的一切原始及迭代数据集的对象存储方案。根据数据湖的实际业务需求,我们可以将Amazon S3中容纳的数据划分为双层或者三层结构:
T1存储(原始数据)——此存储层为一个或者多个S3存储桶,用于承载来自摄取服务的原始数据。最重要的是,此层中的数据必须以原始格式进行维护与存储,不可进行任何形式的数据转换。
T2存储,分析优化——此存储层负责托管在T1层中通过ETL作业处理(例如Spark on EMR,或AWS Glue)将原始数据转换成的通用列式数据(例如Parquet、ORC或Avro)及其数据集。这些数据将按分区形式组织并保存为列,这使得计算环境在从T2存储层摄取数据时可以获得更低的成本与更佳性能表现。
T3特定于用例的数据集市(可选)——此层中托管的数据属于T2层数据的子集,针对特定用例数据集市组织而成。T3数据通常拥有更高的访问权限与安全性约束。根据实际使用情况,数据提供方将由更合适的计算与分析环境充当(例如Amazon EMR、Amazon Redshift、Amazon Neptune以及Amazon Aurora)
-
-
2–数据摄取:
- 数据湖架构的数据摄取组件,代表着将数据持久存储在Amazon S3中的具体过程。在数据湖当中,一切以T1层中的原始数据为起点。除了需要预先指定存储数据所使用的S3存储桶之外,数据生成服务不需要考虑其他任何约束条件、结构一致性或者数据合约要求。
-
3–处理与分析:
- 处理与分析(Processing & Analytics)部分囊括多种AWS服务,用于处理或存储来自T1层的ETL数据,并将处理后的数据传递至T2层。接下来,大家可以通过交互式查询或者机器学习/建模等分析或机器学习环境使用T2层中的数据。
-
4–保护与安全
- 保护与安全(Protect & Secure)是一种总体抽象,被全面集成至数据湖内的多项服务当中。这一部分主要负责强调处理静态/传输数据时,身份验证、授权、审计、合规性与加密等机制的重要性,这些机制需要全面对接数据湖内的摄取、存储与处理/分析等各个环节。这些安全概念大多以功能集的形式被集成至每一项数据处理服务当中,用以保护数据管理服务的访问能力与完整性。
-
5–目录与搜索
- 目录与搜索组件负责捕捉、管理、维护、索引以及搜索托管在数据湖存储(Amazon S3)内数据集中的元数据。为此,组织通常需要对数据湖目录所管理的各个数据集所需要的最小元数据集(包括描述、标签及使用说明等)进行授权。也正是通过这种方式,数据湖数据集内的各个单一对象都会被映射至整体数据集的元数据记录中。您可以使用DynamoDB、Elasticsearch Service以及AWS GlueCatalog等AWS服务来跟踪并索引数据湖内所托管数据集的元数据。对Amazon S3内新的或者经过更新的对象事件可以触发AWS Lambda函数,帮助您轻松保持目录的持续更新。
-
6–访问与用户接口
-
在AWS中,包括Amazon API Gateway、AWS Lambda以及AWS Directory Service在内的多种服务,都可帮助您安全跟踪执行进程
创建、修改并删除新的数据湖数据集及其对应元数据。
负责创建、更新及合并迭代数据集的ETL作业(用于将T1数据转换为列式、进行压缩并充当T2数据)的创建与管理。
对摄取T2数据的分析计算环境进行创建、删除或修改,从而实现后续查询、可视化开发及洞见分析。
-
AWS上流行的数据分析服务组合
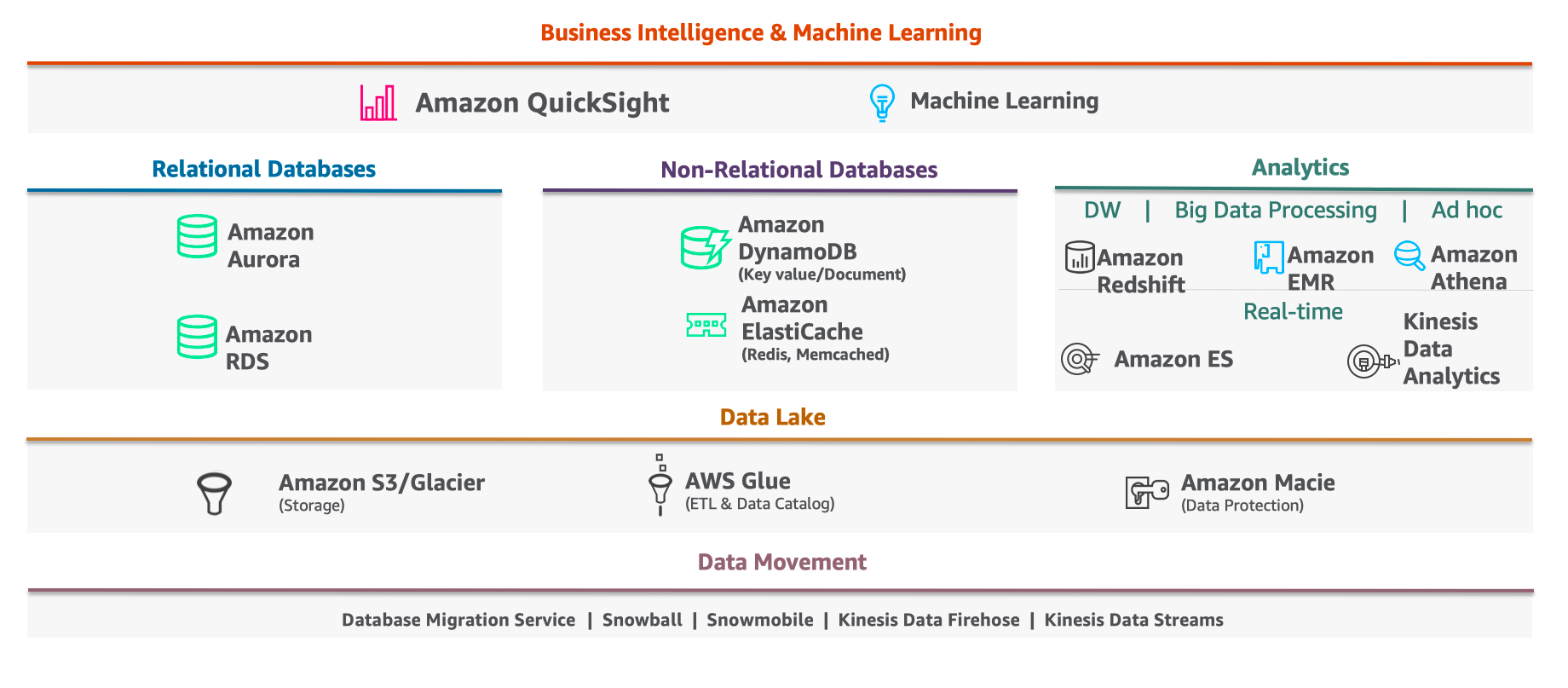
如果我们将服务的组合架构成从下至上从摄取到数据应用的模式,可以参考如下流行的架构组合
数据摄取层
数据摄取层主要负责将数据摄取至集中存储层(例如数据湖)以进行分析。摄取层包含多项服务,各服务用于使用来自外部来源数据集的批量与实时流数据,具体涵盖网站点击流、数据库事件流、财务交易、社交媒体馈送、IT日志、位置跟踪事件、物联网遥测数据、本地数据源以及云原生数据存储等等。
Amazon Kinesis为专门用于实时数据摄取的服务家族,不仅提供安全的流数据加载与分析功能,同时可将流数据传输至Amazon Simple Storage Service(简称Amazon S3)以实现长期存储。我们还提供Amazon Managed Streaming for Kafka(简称MSK),这是一项全托管服务,可帮助用户通过安全的高可用性Apache Kafka集群处理流数据,且无需修改现有代码库。
接下来是AWS Database Migration Services(简称DMS),您可以借此在保证源数据库正常运行的同时复制并摄取该数据库。此项服务支持多个数据库源与目标,包括直接将数据写入至Amazon S3。为了加快DMS迁移,您还可以选择AWS Snowball——这项服务通过安全物理设备实现大规模数据对AWS云的批量传入与导出。最后,您也可以使用AWS Direct Connect,这项服务负责在本地数据中心与AWS云环境之间建立起统一的专用网络连接。
有些用户可能还需要使用其他数据摄取点,例如AWS IoT Core,这是一套托管平台,能够可靠且安全地大规模处理消息并将消息内容路由至AWS 数据存储当中。AWS DataSync是一项数据传输服务,能够自动简化并加快数据在本地存储系统(例如NFS)与AWS存储服务(例如Amazon EFS及Amazon S3)之间的移动与复制流程,并将数据内容摄取至分析类工作负载当中。
数据访问与安全层
数据访问与安全层提供一套完整机制,用于实现数据资产保护及访问,而且为使用者提供与其权限对应的授权管理方案。该层的具体功能包括:
- 保护指向集中数据存储库(即数据湖)的安全访问
- 保护指向集中数据目录的访问
- 对数据库目录中的数据库、表及列进行细粒度访问控制
- 对传输及静态数据进行加密 要安全管理指向AWS服务与资源的访问操作,您需要使用AWS身份与访问管理(AWS Identity and Access Management,简称IAM)。使用IAM,您可以创建并管理AWS用户与分组,并通过权限机制许可及拒绝指向AWS资源的访问操作。AWS CloudTrail则帮助用户记录、持续监控并保留AWS基础架构中各用户及角色中与数据访问相关的账户活动。此外,您还可以使用Amazon CloudWatch收集监控与运营数据,以日志、指标以及事件的形式把握分析类工作负载的运行状态。
要实现静态数据加密,请使用AWS密钥管理服务(AWS Key Management Service,简称KMS)。这是一种安全的弹性服务,可帮助您轻松创建并控制用于加密数据的密钥。部分法规还要求您将KMS与AWS CloudHSM配合使用——AWS CloudHSM为基于云的硬件安全模块(HSM),用户可以借此轻松生成并使用自己的加密密钥。AWS CloudHSM可帮助用户证明安全性、隐私与防篡改等法规层面的合规性,遵循HIPAA、FedRAMP与PCI等法规的具体要求。您还可以在KMS配置中将CloudHSM集群设定为自定义密钥存储,借此替代默认的KMS密钥存储。
AWS Lake Formation是一项集成化数据湖服务,可帮助用户轻松摄取、清洗、分类、转换并保护数据,并将处理后的数据用于分析及机器学习(ML)。Lake Formation还提供自己的权限模型,用于进一步扩展AWS IAM提供的权限模型——包括配置数据湖的数据访问与安全策略,同时审计并控制来自AWS分析与ML服务的访问操作。通过这套集中定义的权限模型,我们可以使用简单的授权/撤销机制对存储在数据湖内的数据进行细粒度访问。
目录与搜索层
分析类工作负载中的目录与搜索层,用于管理跟数据资产相关的元数据的发现与分类。随着数据资产数量与规模的增长,该层还顾名思义提供搜索功能。在这类使用场景下,您需要根据事先定义的条件查找表摄取数据子集,这也是一种在分析类应用当中相当常见的操作。
AWS Glue是一项全托管型提取、转换与加载(ETL)服务,可帮助客户轻松准备并加载等待分析的数据。您可以直接将AWS Glue指向保存在AWS上的数据,该服务会自动识别数据,并将与之关联的元数据(例如表定义与schema)存储在AWS Glue数据目录当中。在分类完成之后,您即可直接对数据进行搜索、查询以及ETL。
使用Amazon Elasticsearch Service,您可以在AWS云中部署一套或多套全托管Elasticsearch集群,进而搜索您的数据集。您可以直接访问Elasticsearch API——该服务能够将现有代码与应用程序无缝匹配起来,提供对Kibana、Logstash以及其他AWS服务的集成支持,而且内置有警报与SQL查询功能。
Amazon关系数据库服务(Amazon Relational Database Service,简称Amazon RDS)能够极大简化云环境中关系数据库的设置、操作与扩展等流程。除了AWS Glue之外,您也可以使用Amazon RDS为EMR创建外部Hive元存储。元存储中不仅包含与表相关的描述,还有以此为基础构建的其他表基础数据,例如分区名称、数据类型等等。 Amazon DynamoDB是一项NoSQL数据存储服务,可用于创建高性能、低成本的外部索引,并借此将可查询的属性映射至Amazon S3对象键。Amazon DynamoDB具备自动扩展与高可用性等优势,帮助用户摆脱传统服务器带来的维护负担。
集中存储层
集中存储层负责管理摄取自各生产程序处的数据,并将其进一步提供给下游应用程序。集中存储层是数据湖的核心,应该能够支持对一切数据类型的存储,具体包括非结构化数据、半结构化数据与结构化数据。随着时间推移,您的数据量可能不断增长,因此集中存储层还应以安全且经济高效的方式实现灵活扩展。
在数据处理管道当中,我们也可以将数据存储在流程的中间阶段处,这既可以避免不必要的重复操作,也可以让中间数据同时供多个下游消费程序使用。根据实际场景的需求,这些中间数据可能需要经常更新、临时存储或者长期存储。 Amazon S3具备近乎无限的可扩展性,99.999999999%(11个9)持久性以及原生加密与访问控制功能,因此非常适合作为集中存储方案的底层基础。随着数据存储需求的增长,您可以将数据迁移至低成本层,例如S3 Infrequent Access或者Amazon S3 Glacier,通过多种生命周期管理策略节约存储成本,同时保证原始数据的安全性与完整性。另外,您也可以使用S3 Intelligent-Tiering,借此在数据访问模式发生改变时自动优化存储成本,且不会对性能或运营开销造成任何影响。
Amazon S3让多租户环境的构建变得非常轻松,不同用户可以在其中将自己的独特数据分析工具与一组通用数据对接起来。与需要建立多套分布式数据副本的传统解决方案相比,多租户环境能够显著改善成本与数据治理能力。为了进一步降低访问门槛,Amazon S3还提供简单的RESTful API,目前Apache Hadoop以及大多数第三方独立软件供应商(ISV)及分析工具供应商已经在支持这些RESTful API。
在Amazon S3的支持下,您的数据湖能够将存储同计算/数据处理机制拆分开来。在传统Hadoop及数据仓库解决方案当中,存储与计算总是紧密结合在一起,因此对成本与数据处理工作流程的优化总是困难无比。Amazon S3允许您以原生格式存储一切数据类型,并指定任意数量的虚拟服务器执行数据处理。此外,您还可以与多种无服务器解决方案进行集成,例如AWS Lambda、Amazon Athena、Amazon Redshift Spectrum、Amazon Rekognition以及AWS Glue等等——无需置备或管理任何服务器,即可轻松获得数据处理能力。
Amazon Elastic Block Store(简称EBS)提供永久性的块存储卷,可用于AWS云中的Amazon EC2实例。每一个Amazon EBS存储卷都会自动在其所在可用区内复制,保证您的系统免受组件故障的影响,借此实现高可用性与持久性。对于分析类工作负载,您可以将EBS与运行在EC2实例上的各类大数据分析引擎(例如Hadoop/HDFS生态系统或者Amazon EMR集群)、关系数据库与NoSQL数据库(例如微软SQL Server与MySQL,或Cassandra与MongoDB)、流数据与日志处理应用程序(例如Kafka与Splunk)以及数据仓库应用程序(例如Vertica与Teradata)配合使用。
处理与分析层
处理与分析层负责提供与数据集查询及处理(包括清洗、验证、转换、丰富以及规范化)相关的工具及服务,并以批量及实时流数据模式提取业务洞见。处理与分析层当中包含多项具体服务。
Amazon EMR是一项托管服务,能够跨越多个Amazon EC2实例轻松运行并动态扩展Apache Spark、Hadoop、HBase、Presto、Hive以及其他多种大数据框架,并与Amazon S3及Amazon DynamoDB等其他AWS数据存储实现交互。
Amazon Redshift是一套全托管数据仓库,使用标准SQL与现有商务智能(BI)工具以简单且极具经济效益的方式分析各类数据。Redshift Spectrum属于Amazon Redshift中的一项功能,可帮助用户查询保存在Amazon S3中的EB级超大规模非结构化数据,且无需涉及任何加载或ETL操作。Redshift Spectrum能够在短短几分钟内对EB甚至更高数量级的数据执行极为复杂的查询。
Amazon Athena是一项交互式查询服务,可使用标准SQL轻松分析保存在Amazon S3中的数据。Athena具备无服务器特性,用户无需管理任何基础设施,仅按使用量付费即可。Athena还能够与AWS Glue数据目录相集成,帮助您跨多项服务创建起统一的元数据存储、爬取数据源以识别重要模式、使用新的/经过修改的表及分区定义执行目录填充,同时实现对schema的版本控制能力。
使用Amazon Neptune,您可以创建起一套快速、可靠的全托管图数据库,从而轻松构建并运行基于高连接度数据集的应用程序。Amazon Neptune支持多种流行图模型,包括Property Graph与W3C的RDF,且支持二者对应的查询语言Apache TinkerPo Gremlin与SPARQL。Amazon Neptune还能够增强图关系用例的功能,实现包括推荐引擎、欺诈检测、知识图谱、药物发现以及网络安全性等多种应用。
Amazon SageMaker是一套全托管机器学习平台,帮助开发人员与数据科学家快速灵活地构建、训练并部署任意规模的机器学习模型。数据科学家可以使用它轻松针对不同数据湖元素完成ML模型的创建、训练与部署。 除此之外,还有更多原有服务为处理与分析类负载提供支持,包括Amazon Kinesis、Amazon RDS、Apache Kafka以及AWS Glue ETL作业。
用户访问与接口层
AWS Lambda帮助用户在托管平台上运行各类无状态无服务器应用程序,且该平台的函数层全面支持微服务架构、部署以及执行管理等功能。
使用Amazon API Gateway,您可以运行与Lambda集成的全托管REST API以执行业务逻辑,同时实现流量管理、授权与访问控制、监控以及API版本控制等多种功能。例如,您可以使用API网关(通过HTTPS接收请求)创建数据湖API。在发出API请求时,Amazon API Gateway会使用自定义认证器(一条Lambda函数)保证在实现发出数据之前,对所有请求的权限进行验证。
使用Amazon Cognito,您可以轻松在无服务器应用程序当中添加用户注册、登录与数据同步等功能。Amazon Cognito用户池提供内置登录屏幕,并通过安全性声明标记语言(SAML)实现与Facebook、Google及Amazon的身份验证联动。Amazon Cognito Federated Identities帮助您更安全地对无服务器架构内的各类AWS资源进行受限、受控访问。
AWS 分析服务
您可以通过以下列表查看各层级流行服务的详细介绍: